加菲猫欢乐跑
65.99M · 2026-03-26

官网标题:「 Build AI Knowledge Assistants over your enterprise data 」
LlamaIndex 是一个为开发「知识增强」的大语言模型应用的框架。知识增强,泛指任何在私有或特定领域数据基础上应用大语言模型的情况。例如:
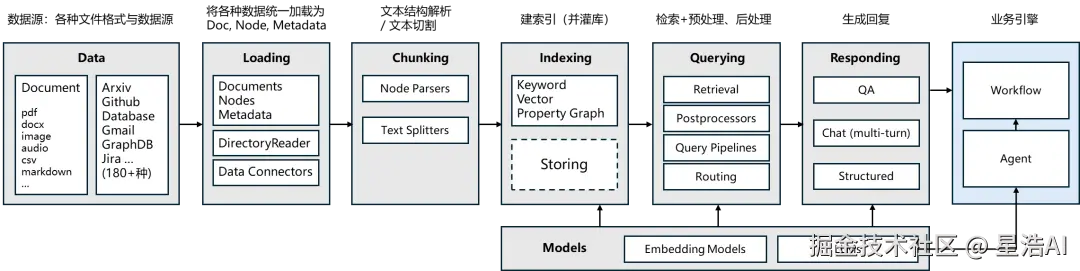
在这里补充一张图。
LlamaIndex 有 Python 和 Typescript 两个版本,Python 版的文档相对更完善。
pip install llama-index
在深入学习 LlamaIndex 之前,我们先了解几个核心概念:
LlamaIndex 中的基本数据单元,代表一个完整的文档(如 PDF、网页、文本文件等)。每个 Document 包含文本内容以及可选的元数据(metadata)。
Document 被切分后的文本片段,是检索和索引的基本单位。每个 Node 包含文本内容、元数据以及与其他 Node 的关系信息。
为了快速检索而构建的数据结构。LlamaIndex 支持多种索引类型,如向量索引、关键词索引等。
负责从索引中检索相关 Node 的组件,根据查询返回最相关的文档片段。
结合检索器和 LLM,根据检索到的上下文生成最终答案。
支持多轮对话的查询引擎,能够维护对话历史上下文。
数据流转过程:
Document → Node → Index → Retriever → Query/Chat Engine → Response
SimpleDirectoryReader是一个简单的本地文件加载器。它会遍历指定目录,并根据文件扩展名自动加载文件(文本内容)。
支持的文件类型:
.csv- comma-separated values.docx- Microsoft Word.epub- EPUB ebook format.hwp- Hangul Word Processor.ipynb- Jupyter Notebook.jpeg,.jpg- JPEG image.mbox- MBOX email archive.md- Markdown.mp3,.mp4- audio and video.pdf- Portable Document Format.png- Portable Network Graphics.ppt,.pptm,.pptx- Microsoft PowerPoint# 辅助函数:用于格式化展示 JSON 数据
import json
from pydantic.v1 import BaseModel
def show_json(data):
"""用于展示json数据"""
if isinstance(data, str):
obj = json.loads(data)
print(json.dumps(obj, indent=4, ensure_ascii=False))
elif isinstance(data, dict) or isinstance(data, list):
print(json.dumps(data, indent=4, ensure_ascii=False))
elif issubclass(type(data), BaseModel):
print(json.dumps(data.dict(), indent=4, ensure_ascii=False))
def show_list_obj(data):
"""用于展示一组对象"""
if isinstance(data, list):
for item in data:
show_json(item)
else:
raise ValueError("Input is not a list")
from llama_index.core import SimpleDirectoryReader
# 创建目录读取器
# input_dir: 要读取的目录路径
# recursive: 是否递归读取子目录(True/False)
# required_exts: 可选,指定只读取特定扩展名的文件
reader = SimpleDirectoryReader(
input_dir="./data",
recursive=False,
required_exts=[".pdf"]
)
# 加载文档,返回 Document 对象列表
documents = reader.load_data()
print(documents[0].text)
show_json(documents[0].json())
默认的PDFReader效果并不理想,我们可以更换文件加载器
LlamaParse
首先,登录并从 cloud.llamaindex.ai ↗ 注册并获取 api-key 。
然后,安装该包:
pip install llama-cloud-services
# 在系统环境变量里配置 LLAMA_CLOUD_API_KEY=XXX
# 或使用 .env 文件配置(推荐)
from llama_cloud_services import LlamaParse
from llama_index.core import SimpleDirectoryReader
import nest_asyncio
from dotenv import load_dotenv
# 只在 Jupyter 环境中需要,解决异步事件循环问题
nest_asyncio.apply()
# 从 .env 文件加载环境变量
load_dotenv()
# 创建 LlamaParse 解析器
# result_type: 输出格式,"markdown" 或 "text"
parser = LlamaParse(result_type="markdown")
# 将 PDF 文件的解析器指定为 LlamaParse
file_extractor = {".pdf": parser}
# 使用自定义解析器加载文档
documents = SimpleDirectoryReader(
input_dir="./data",
required_exts=[".pdf"],
file_extractor=file_extractor
).load_data()
print(documents[0].text)
用于处理更丰富的数据类型,并将其读取为Document的形式。
例如:直接读取网页
pip install llama-index-readers-web
from llama_index.readers.web import SimpleWebPageReader
documents = SimpleWebPageReader(html_to_text=True).load_data(
["https://edu.guangjuke.com/tx/"]
)
print(documents[0].text)
为方便检索,我们通常把Document切分为Node。
在 LlamaIndex 中,Node被定义为一个文本的「chunk」。
例如:TokenTextSplitter按指定 token 数切分文本
from llama_index.core import Document
from llama_index.core.node_parser import TokenTextSplitter
# 创建文本切分器
# chunk_size: 每个 chunk 的最大 token 数(建议 256-1024,根据模型上下文窗口调整)
# chunk_overlap: chunk 之间的重叠 token 数(建议为 chunk_size 的 10-20%,保证上下文连续性)
node_parser = TokenTextSplitter(
chunk_size=512,
chunk_overlap=200
)
# 将 Document 切分为 Node 列表
# show_progress: 是否显示进度条(处理大量文档时有用)
nodes = node_parser.get_nodes_from_documents(
documents,
show_progress=False
)
# 查看切分后的 Node 结构
show_json(nodes[1].json())
show_json(nodes[2].json())
LlamaIndex 提供了丰富的TextSplitter,例如:
SentenceSplitter:在切分指定长度的 chunk 同时尽量保证句子边界不被切断;CodeSplitter:根据 AST(编译器的抽象句法树)切分代码,保证代码功能片段完整;SemanticSplitterNodeParser:根据语义相关性对将文本切分为片段。例如:HTMLNodeParser解析 HTML 文档
from llama_index.core.node_parser import HTMLNodeParser
from llama_index.readers.web import SimpleWebPageReader
documents = SimpleWebPageReader(html_to_text=False).load_data(
["https://www.baidu.com/"]
)
# 默认解析 ["p", "h1", "h2", "h3", "h4", "h5", "h6", "li", "b", "i", "u", "section"]
parser = HTMLNodeParser(tags=["span"]) # 可以自定义解析哪些标签
nodes = parser.get_nodes_from_documents(documents)
for node in nodes:
print(node.text+"n")
更多的NodeParser包括MarkdownNodeParser,JSONNodeParser等等。
Chunk Size 选择建议:
chunk_size=256-512,chunk_overlap=50-100
chunk_size=512-1024,chunk_overlap=100-200
chunk_size=1024-2048,chunk_overlap=200-400
注意事项:
CodeSplitter保持代码块完整性NodeParser而非简单切分基础概念:
在「检索」相关的上下文中,「索引」即index, 通常是指为了实现快速检索而设计的特定「数据结构」。
索引的具体原理与实现不是本课程的教学重点,感兴趣的同学可以参考:传统索引、向量索引
VectorStoreIndex直接在内存中构建一个 Vector Store 并建索引from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.node_parser import TokenTextSplitter, SentenceSplitter
# 1. 加载 PDF 文档
documents = SimpleDirectoryReader(
"./data",
required_exts=[".pdf"],
).load_data()
# 2. 定义 Node Parser 用于切分文档
node_parser = TokenTextSplitter(chunk_size=512, chunk_overlap=200)
# 3. 将文档切分为 Node
nodes = node_parser.get_nodes_from_documents(documents)
# 4. 构建向量索引(默认在内存中,适合小规模数据)
# 构建过程会自动调用 Embedding 模型为每个 Node 生成向量
index = VectorStoreIndex(nodes)
# 方式二:直接从 Document 构建(会自动应用 transformations)
# index = VectorStoreIndex.from_documents(
# documents=documents,
# transformations=[SentenceSplitter(chunk_size=512)]
# )
# 5. 持久化索引到本地(可选,用于后续复用)
# index.storage_context.persist(persist_dir="./doc_emb")
# 6. 创建检索器
# similarity_top_k: 返回最相似的前 k 个结果(建议 3-10,根据需求调整)
vector_retriever = index.as_retriever(
similarity_top_k=2
)
# 7. 执行检索
# 检索过程:将查询文本转换为向量 → 在向量空间中搜索相似 Node → 返回结果
results = vector_retriever.retrieve("deepseek v3数学能力怎么样?")
# 8. 查看检索结果
print(results[0].text)
Qdrant为例:pip install llama-index-vector-stores-qdrant
from llama_index.core.indices.vector_store.base import VectorStoreIndex
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.core import StorageContext
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance
# 1. 创建 Qdrant 客户端
# location=":memory:": 内存模式(重启后数据丢失)
# location="./qdrant_db": 持久化到本地目录(推荐生产环境使用)
client = QdrantClient(location=":memory:")
# 2. 创建向量集合(Collection)
collection_name = "demo"
# size: 向量维度,需与 Embedding 模型输出维度一致(如 OpenAI text-embedding-3-small 为 1536)
# distance: 距离度量方式,COSINE(余弦相似度)适合文本检索
collection = client.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=1536, distance=Distance.COSINE)
)
# 3. 创建 Qdrant Vector Store
vector_store = QdrantVectorStore(client=client, collection_name=collection_name)
# 4. 创建存储上下文,关联自定义的 Vector Store
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 5. 使用自定义 Vector Store 创建索引
# 数据会存储在 Qdrant 中,而非内存
index = VectorStoreIndex(nodes, storage_context=storage_context)
# 6. 创建检索器
vector_retriever = index.as_retriever(similarity_top_k=1)
# 7. 执行检索
results = vector_retriever.retrieve("deepseek v3数学能力怎么样")
print(results[0])
LlamaIndex 内置了丰富的检索机制,例如:
QueryFusionRetrieverLlamaIndex 的Node Postprocessors提供了一系列检索后处理模块。
例如:我们可以用不同模型对检索后的Nodes做重排序
# 获取 retriever
vector_retriever = index.as_retriever(similarity_top_k=5)
# 检索
nodes = vector_retriever.retrieve("deepseek v3有多少参数?")
for i, node in enumerate(nodes):
print(f"[{i}] {node.text}n")
from llama_index.core.postprocessor import LLMRerank
postprocessor = LLMRerank(top_n=2)
nodes = postprocessor.postprocess_nodes(nodes, query_str="deepseek v3有多少参数?")
for i, node in enumerate(nodes):
print(f"[{i}] {node.text}")
更多的 Rerank 及其它后处理方法,参考官方文档:Node Postprocessor Modules
内存 vs 持久化存储选择:
检索策略选择:
QueryFusionRetriever)Embedding 模型选择:
text-embedding-v3(DashScope)、bge-large-zh-v1.5(HuggingFace)text-embedding-3-small/large(OpenAI)、multilingual-e5-large# 创建查询引擎(单轮问答)
# Query Engine 内部流程:检索相关 Node → 构建 Prompt → 调用 LLM 生成回答
qa_engine = index.as_query_engine()
# 执行查询
response = qa_engine.query("deepseek v3数学能力怎么样?")
# 输出结果
print(response)
# 启用流式输出,适合实时交互场景
qa_engine = index.as_query_engine(streaming=True)
response = qa_engine.query("deepseek v3数学能力怎么样?")
# 方式一:使用内置方法打印流式输出
response.print_response_stream()
# 方式二:手动控制输出(更灵活)
# for token in response.response_gen:
# print(token, end="", flush=True)
chat_engine = index.as_chat_engine()
response = chat_engine.chat("deepseek v3数学能力怎么样?")
print(response)
response = chat_engine.chat("代码能力呢?")
print(response)
chat_engine = index.as_chat_engine()
# 流式对话,逐 token 输出
streaming_response = chat_engine.stream_chat("deepseek v3数学能力怎么样?")
# 方式一:使用内置方法
# streaming_response.print_response_stream()
# 方式二:手动控制输出(推荐,可自定义格式)
for token in streaming_response.response_gen:
print(token, end="", flush=True)
Query Engine(单轮问答):
Chat Engine(多轮对话):
选择建议:
from llama_index.core import PromptTemplate
# 创建提示词模板,使用 {变量名} 作为占位符
prompt = PromptTemplate("写一个关于{topic}的笑话")
# 格式化模板,替换占位符
result = prompt.format(topic="小明")
print(result)
# 输出:'写一个关于小明的笑话'
from llama_index.core.llms import ChatMessage, MessageRole
from llama_index.core import ChatPromptTemplate
chat_text_qa_msgs = [
ChatMessage(
role=MessageRole.SYSTEM,
content="你叫{name},你必须根据用户提供的上下文回答问题。",
),
ChatMessage(
role=MessageRole.USER,
content=(
"已知上下文:n"
"{context}nn"
"问题:{question}"
)
),
]
text_qa_template = ChatPromptTemplate(chat_text_qa_msgs)
print(
text_qa_template.format(
name="小明",
context="这是一个测试",
question="这是什么"
)
)
system: 你叫小明,你必须根据用户提供的上下文回答问题。 user: 已知上下文: 这是一个测试
问题:这是什么 assistant:
from llama_index.llms.openai import OpenAI
llm = OpenAI(temperature=0, model="gpt-4o")
response = llm.complete(prompt.format(topic="小明"))
print(response.text)
response = llm.complete(
text_qa_template.format(
name="小明",
context="这是一个测试",
question="你是谁,我们在干嘛"
)
)
print(response.text)
pip install llama-index-llms-deepseek
import os
from llama_index.llms.deepseek import DeepSeek
llm = DeepSeek(model="deepseek-chat", api_key=os.getenv("DEEPSEEK_API_KEY"), temperature=1.5)
response = llm.complete("写个笑话")
print(response)
from llama_index.core import Settings
Settings.llm = DeepSeek(model="deepseek-chat", api_key=os.getenv("DEEPSEEK_API_KEY"), temperature=1.5)
除 OpenAI 外,LlamaIndex 已集成多个大语言模型,包括云服务 API 和本地部署 API,详见官方文档:Available LLM integrations
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import Settings
# 全局设定 Embedding 模型
# model: 模型名称
# dimensions: 向量维度(可选,某些模型支持自定义维度以节省成本)
Settings.embed_model = OpenAIEmbedding(
model="text-embedding-3-small",
dimensions=512 # 降低维度可节省存储和计算成本,但可能影响精度
)
LlamaIndex 同样集成了多种 Embedding 模型,包括云服务 API 和开源模型(HuggingFace)等,详见官方文档。
LLM 选择建议:
Temperature 参数调整:
Embedding 模型选择:
功能要求:
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance
EMBEDDING_DIM = 1536
COLLECTION_NAME = "full_demo"
PATH = "./qdrant_db"
client = QdrantClient(path=PATH)
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, get_response_synthesizer
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.response_synthesizers import ResponseMode
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core import Settings
from llama_index.core import StorageContext
from llama_index.core.postprocessor import LLMRerank, SimilarityPostprocessor
from llama_index.core.retrievers import QueryFusionRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.chat_engine import CondenseQuestionChatEngine
from llama_index.llms.dashscope import DashScope, DashScopeGenerationModels
from llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModels
import os
# ========== 第一步:配置全局模型 ==========
# 1. 设置 LLM(用于生成回答)
Settings.llm = DashScope(
model_name=DashScopeGenerationModels.QWEN_MAX,
api_key=os.getenv("DASHSCOPE_API_KEY")
)
# 2. 设置 Embedding 模型(用于生成向量)
Settings.embed_model = DashScopeEmbedding(
model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1
)
# 3. 设置全局文档处理管道(自动应用于所有文档)
Settings.transformations = [
SentenceSplitter(chunk_size=512, chunk_overlap=200)
]
# ========== 第二步:加载和索引文档 ==========
# 4. 加载本地文档
documents = SimpleDirectoryReader("./data").load_data()
# 5. 清理已存在的集合(可选,用于重新构建索引)
if client.collection_exists(collection_name=COLLECTION_NAME):
client.delete_collection(collection_name=COLLECTION_NAME)
# 6. 创建 Qdrant 集合
client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config=VectorParams(size=EMBEDDING_DIM, distance=Distance.COSINE)
)
# 7. 创建 Vector Store 并关联到 Qdrant
vector_store = QdrantVectorStore(client=client, collection_name=COLLECTION_NAME)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 8. 构建索引(会自动应用 Settings.transformations 切分文档)
index = VectorStoreIndex.from_documents(
documents,
storage_context=storage_context
)
# ========== 第三步:配置检索和排序 ==========
# 9. 定义检索后处理器
# LLMRerank: 使用 LLM 对检索结果重新排序,提高准确性(但会增加延迟和成本)
reranker = LLMRerank(top_n=2)
# SimilarityPostprocessor: 过滤相似度低于阈值的文档(未使用,仅作示例)
# sp = SimilarityPostprocessor(similarity_cutoff=0.6)
# 10. 创建 RAG-Fusion 检索器
# RAG-Fusion 原理:将原始查询扩展为多个相关查询,分别检索后合并结果
fusion_retriever = QueryFusionRetriever(
[index.as_retriever()], # 可以传入多个检索器进行融合
similarity_top_k=5, # 每个查询返回 top 5 结果
num_queries=3, # 生成 3 个扩展查询
use_async=False, # 是否异步执行(True 可提升速度)
)
# ========== 第四步:构建查询引擎 ==========
# 11. 构建单轮查询引擎
# ResponseMode.REFINE: 先基于第一个 chunk 生成回答,再用其他 chunk 逐步优化
query_engine = RetrieverQueryEngine.from_args(
fusion_retriever,
node_postprocessors=[reranker], # 应用重排序
response_synthesizer=get_response_synthesizer(
response_mode=ResponseMode.REFINE # 其他模式:COMPACT, TREE_SUMMARIZE, SIMPLE_SUMMARIZE
)
)
# ========== 第五步:构建对话引擎 ==========
# 12. 创建多轮对话引擎
# CondenseQuestionChatEngine: 将历史对话压缩为独立查询,适合长对话
chat_engine = CondenseQuestionChatEngine.from_defaults(
query_engine=query_engine,
# 可以自定义问题压缩的 prompt 模板
# condense_question_prompt="..."
)
# 测试多轮对话
# User: deepseek v3有多少参数
# User: 每次激活多少
while True:
question=input("User:")
if question.strip() == "":
break
response = chat_engine.chat(question)
print(f"AI: {response}")
Q: 如何处理大文件或大量文件?
A: 有几种策略:
recursive=True递归读取子目录# 示例:分批加载
files = ["file1.pdf", "file2.pdf", "file3.pdf"]
for file in files:
documents = SimpleDirectoryReader(input_files=[file]).load_data()
# 处理 documents
Q: PDF 文件解析效果不好怎么办?
A: 可以尝试以下方法:
LlamaParse替代默认的 PDFReader(效果更好但需要 API key)Q: 如何处理图像、视频、音频文件中的文字?
A: 需要使用专门的 Data Connectors:
ImageReader或集成 OCR 服务Q: Chunk size 应该设置多大?
A: 需要根据以下因素综合考虑:
Q: Chunk overlap 设置多少合适?
A: 一般建议:
Q: 为什么切分后的结果不理想?
A: 可能的原因和解决方案:
SentenceSplitter而非TokenTextSplitterCodeSplitterSemanticSplitterNodeParserNodeParser(如HTMLNodeParser、MarkdownNodeParser)Q: 检索效果不好,返回的结果不相关怎么办?
A: 可以尝试以下优化方法:
SentenceSplitter通常比TokenTextSplitter效果更好LLMRerank对检索结果重新排序Q: 检索速度太慢怎么办?
A: 优化建议:
similarity_top_k的值use_async=True)Q: 向量检索和关键字检索应该选哪个?
A: 选择建议:
Q: 如何处理中文文档?
A: 关键点:
# 中文场景推荐配置
from llama_index.embeddings.dashscope import DashScopeEmbedding
from llama_index.core.node_parser import SentenceSplitter
Settings.embed_model = DashScopeEmbedding(
model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V3
)
Settings.transformations = [SentenceSplitter(chunk_size=512, chunk_overlap=100)]
Q: 如何降低 API 调用成本?
A: 优化策略:
Q: 内存占用太大怎么办?
A: 解决方案:
Q: 索引构建速度慢怎么办?
A: 优化方法:
use_async=True)Q: 如何持久化索引以便后续复用?
A: 两种方式:
# 使用 Qdrant 等向量数据库,数据自动持久化
client = QdrantClient(path="./qdrant_db")
# 保存索引到本地
index.storage_context.persist(persist_dir="./doc_emb")
# 后续加载
from llama_index.core import load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="./doc_emb")
index = load_index_from_storage(storage_context)
Q: 如何更新已构建的索引?
A: 更新策略:
index.insert()添加新文档Q: 生产环境应该注意什么?
A: 关键点:
本文全面介绍了 LlamaIndex 框架的核心功能和使用方法,帮助读者快速上手构建 RAG 应用。
一个完整的 RAG 系统通常包含以下步骤:
希望本文能帮助你快速掌握 LlamaIndex,构建出强大的知识增强应用!如有问题,欢迎参考上面的常见问题部分,或查阅官方文档。
如果你觉得本文有帮助,欢迎点赞、在看、转发,也欢迎留言分享你的经验!

