锦书在线
80.52M · 2026-03-21

昨晚写代码写到凌晨,准备提交的时候,看着空荡荡的 commit message 输入框,突然不想动脑子了。
"这是 feat 还是 fix?scope 填 auth 还是 user?message 怎么概括才得体?" —— 每次都要在大脑里过一遍这些 Conventional Commits 的规则,真的很累。
于是,从昨晚 11 点开始,到今天上午发布上线,花了不到 4 个小时,我vibe coding了一个极其顺手的 Commit Message 生成器。
写完复盘了一下,发现虽然功能简单,但为了"极致的体验",里面用了不少有意思的技术细节。
其实 VS Code 原生就支持 Copilot 生成 commit message,但我之前的 Copilot 服务因为账号问题用不了了(懂的都懂)。
没了 Copilot,我去市场搜了一圈替代品,发现最大的痛点是:不够智能,也不够灵活。
这就导致了两个问题:
我想要的是:
啪 一下甩我脸上。基于这些需求,我 vibe coding 出了这个插件。
最初我设计了四个 Provider:OpenAI、Claude、Gemini、Custom。后来发现这是过度设计——现在大部分 LLM 服务都兼容 OpenAI 格式,没必要分开。
最终只留了三个配置项:
interface ProviderConfig {
apiKey: string;
model: string;
baseUrl: string; // 或
}
用 OpenAI?填 api.openai.com/v1。用 Claude 代理?换个 baseUrl。用本地 Ollama?localhost:11434/v1。一套代码全搞定。
等 AI 生成完再显示结果,体验很差。用户会以为插件卡死了。
解决方案是 SSE(Server-Sent Events)流式输出:
// 请求时开启流式
body: JSON.stringify({
model: this.config.model,
messages: [{ role: 'user', content: prompt }],
stream: true // 关键
})
然后解析 SSE 格式的响应:
async function readOpenAICompatibleStream(
body: ReadableStream<Uint8Array>,
onToken: (text: string) => void
): Promise<string> {
const reader = body.getReader();
const decoder = new TextDecoder('utf-8');
let buffer = '';
let result = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
// SSE 事件以双换行分隔
let sepIndex;
while ((sepIndex = buffer.indexOf('nn')) !== -1) {
const event = buffer.slice(0, sepIndex);
buffer = buffer.slice(sepIndex + 2);
for (const line of event.split('n')) {
if (!line.startsWith('data:')) continue;
const payload = line.slice(5).trim();
if (payload === '[DONE]') return result;
const json = JSON.parse(payload);
const delta = json?.choices?.[0]?.delta?.content ?? '';
if (delta) {
result += delta;
onToken(delta); // 每个 token 实时回调
}
}
}
}
return result;
}
每收到一个 token,就往 VS Code 的 commit 输入框里追加,用户能看到文字一个一个蹦出来。
Conventional Commits 格式是 type(scope): description。让 AI 自己猜 type 有时候不太准,比如改了测试文件,AI 可能还是写 feat。
我加了一层启发式推断:
function inferType(files: string[]): string {
const isDocsFile = (f) => f.endsWith('.md') || f.startsWith('docs/');
const isTestFile = (f) => f.includes('test') || /.(test|spec).[jt]sx?$/.test(f);
const isCIFile = (f) => f.startsWith('.github/workflows/');
if (files.every(isDocsFile)) return 'docs';
if (files.every(isTestFile)) return 'test';
if (files.some(isCIFile)) return 'ci';
// ...
return 'feat';
}
把推断结果作为"建议"传给 AI,而不是强制限制。这样 AI 既有参考,又保留了灵活性:
## Suggestions (optional)
- Suggested type: docs
- Suggested scope: readme
大型重构可能有几千行 diff,直接喂给 AI 会超 token 限制。简单粗暴地截断前 N 个字符,可能会把函数签名截断一半,AI 看不懂。
我的做法是语义裁剪:
function summarizeDiffBlock(block: string, budget: number): string {
const lines = block.split('n');
const header = []; // 保留 diff 头部
const important = []; // 保留关键行
// 用正则识别关键行
const signatureLike = /^[+-]?s*(exports+)?(function|class|interface)/;
const commentLike = /^[+-]?s*(//|#|/*)/;
for (const line of lines) {
if (signatureLike.test(line) || commentLike.test(line)) {
important.push(line);
}
}
return [...header, ...important].join('n');
}
优先保留:
这样即使原始 diff 有 5000 行,裁剪到 500 行后,AI 仍然能理解代码的意图。
有人喜欢简洁的单行 commit,有人喜欢带 body 的详细版本。
我加了 outputStyle 配置:
type OutputStyle = 'headerOnly' | 'headerAndBody';
不同模式下,prompt 模板会动态变化:
{{#if header_only}}
- Output ONLY ONE line (header only): no body, no footer
- Keep it concise (max 72 characters)
{{/if}}
{{#if allow_body}}
- Output a header line and optionally a short body
{{/if}}
headerOnly 模式还有个优化:检测到第一个换行符就立即中断流式输出,不浪费后面的 token:
if (headerOnly) {
const newlineIndex = text.search(/r?n/);
if (newlineIndex !== -1) {
abortController.abort(); // 立即停止
return;
}
}
AI 有时候会输出一些垃圾:
Commit message: feat: ...(带前缀)```feat: ...```(带 markdown 代码块)"feat: ..."(带引号)我加了一层后处理:
function normalizeCommitMessage(raw: string, options: { headerOnly: boolean }): string {
let text = raw;
// 去掉 markdown 代码块
text = text.replace(/```[sS]*?```/g, (block) => {
const lines = block.split('n');
return lines.slice(1, -1).join('n'); // 只保留内容
});
// 去掉常见前缀
text = text.replace(/^s*(commit message|message)s*:s*/i, '');
// 去掉首尾引号
text = text.replace(/^["'`]+|["'`]+$/g, '');
if (options.headerOnly) {
return text.split('n').find(l => l.trim()) ?? '';
}
return text;
}
很多时候写完代码忘了 git add 就直接点生成,大部分插件会报错 "No staged changes"。
我觉得工具应该更聪明一点:
git add 步骤)。const hasStaged = await git.hasStagedChanges();
const hasUnstaged = await git.hasUnstagedChanges();
if (!hasStaged && !hasUnstaged) {
return vscode.window.showWarningMessage('No changes found');
}
if (hasStaged && hasUnstaged) {
// 弹窗让用户选
const picked = await vscode.window.showWarningMessage(
'Detected both staged and unstaged changes',
'Use Staged',
'Use Unstaged'
);
// ...
}
这样在这个微小的交互上,又能少点一次鼠标。
VS Code 插件用 vsce 打包:
npx vsce package
为了减小包体积,我用了 esbuild 打包,把所有 TypeScript 代码编译成一个 extension.js:
// esbuild.mjs
await esbuild.build({
entryPoints: ['src/extension.ts'],
bundle: true,
outfile: 'dist/extension.js',
platform: 'node',
external: ['vscode'],
minify: production
});
最终 .vsix 包只有 435 KB,8 个文件。
这个插件的核心思路就是:在对的地方做对的事。
代码不多,但每个模块都解决了一个实际问题。
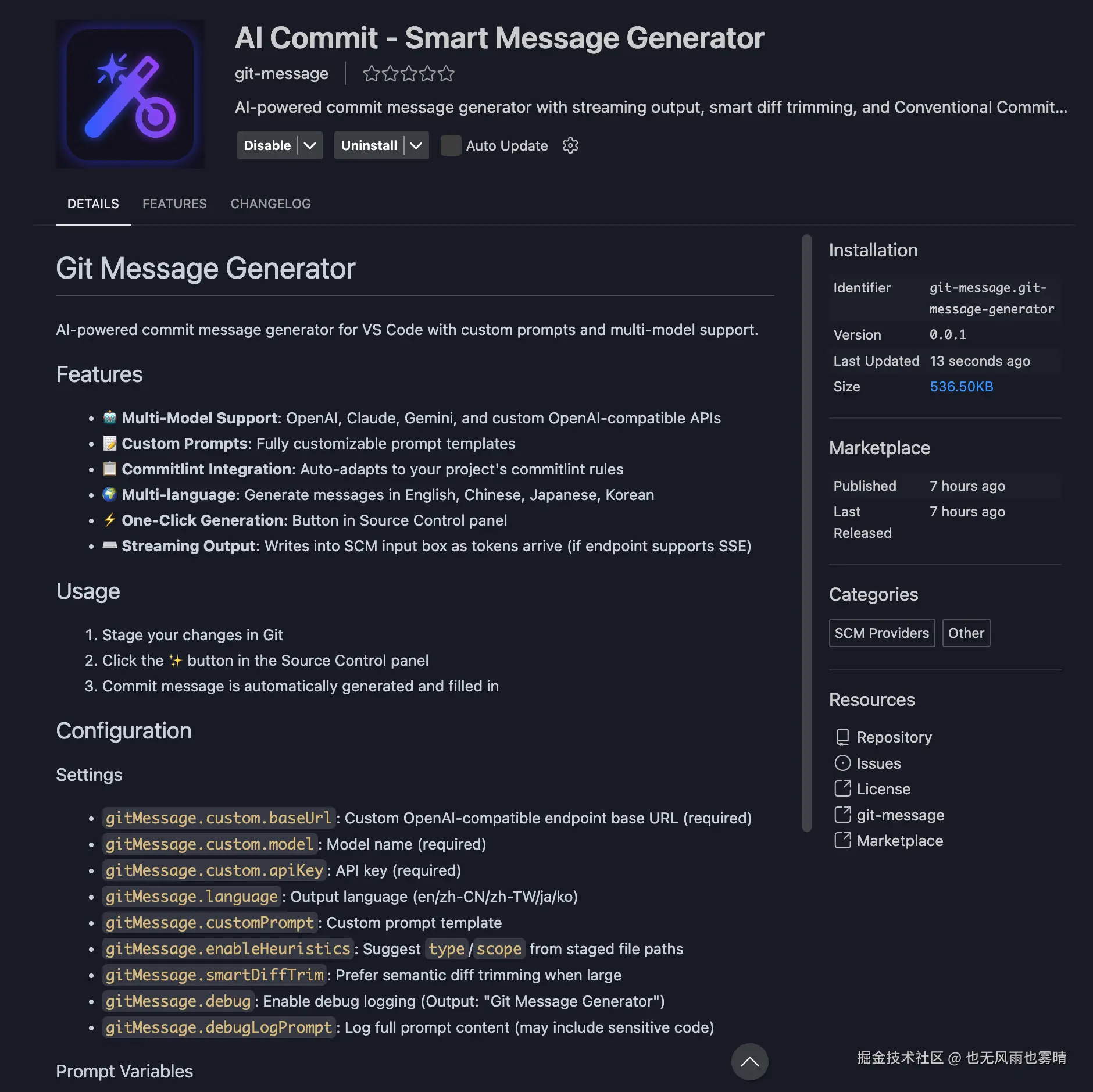
项目已开源:vscode-ai-commit
VS Code Marketplace 搜索 "AI Commit" 可以直接安装。
如果你觉得这篇文章有帮助,欢迎关注我的 GitHub,下面是我的一些开源项目:
Claude Code Skills(按需加载,意图自动识别,不浪费 token,介绍文章):
qwen/gemini/claude - cli 原理学习网站:
coding-cli-guide(学习网站)- 学习 qwen-cli 时整理的笔记,40+ 交互式动画演示 AI CLI 内部机制
prompt-vault - Prompt 管理器,用的都是最新的技术栈,适合用来学习了解最新的前端全栈开发范式:Next.js 15 + React 19 + tRPC 11 + Supabase 全栈示例,clone 下来配个免费 Supabase 就能跑
chat_edit - 双模式 AI 应用(聊天+富文本编辑),Vue 3.5 + TypeScript + Vite 5 + Quill 2.0 + IndexedDB

