




欢乐走免费领手机
24.13MB · 2025-11-10

博客配套代码发布于github:07 Rag进阶篇
本系列所有博客均配套Gihub开源代码,开箱即用,仅需配置API_KEY。
如果该Agent教学系列帮到了你,欢迎给我个Star⭐!
知识点:Chroma 持久化 | Reranker 精排 | RAG 工具化 | Langchain六大模块集成
上篇我们遗留了四个痛点:
综上,本篇会分别从 “强化Rag链条” 与 “扩展Rag应用能力” 两个场景来解决这四大痛点。
最终目标:打造一个“健壮”、“智能”、“集成” 的终极 RAG Agent。
实战数据升级:06 篇我们所用的是“教学大纲”的小文件。本篇作为进阶,我们将使用3.2MB的《战争与和平》(war_and_peace.txt)作为我们的知识库做测试。
对应的文本文件同样存放在Github仓库文件下。
(如不太明白上述术语,建议优先看我的上篇文章 [Ai Agent] 06 Rag基础篇:让你的 Agent 学会“开卷考试” 来加强对RAG的理解)
为什么从 FAISS 升级到 Chroma?
FAISS 本质上是一个内存向量索引库,虽然支持通过 save_local() 将索引保存到磁盘,但它的持久化能力非常有限:
这在需要持续迭代、动态扩展的 RAG 系统中是不可接受的。
相比之下,Chroma 是一个真正的轻量级向量数据库:
persist_directory将向量、原始文档和元数据统一持久化到磁盘;虽然 FAISS 在纯检索性能上可能略优,但 Chroma 在工程易用性、可维护性和扩展性上更适合实际 RAG 应用。通过拆分构建与查询阶段,我们不仅避免了重复向量化,还为未来功能扩展打下了坚实基础。
| 特性 | FAISS(如你的 03/04 代码) | Chroma |
|---|---|---|
| 能否保存? | 能(db.save_local()) | 能(persist_directory + 自动 .persist()) |
| 保存的是什么? | 一个静态快照:向量索引 + 嵌入时的文档副本 | 一个可读写的数据库目录,包含向量、文档、元数据、集合信息 |
| 能否后续增删改? | 不能(或极难) | 能:.add_documents(), .delete(ids=...), .update() |
| 是否自动持久化? | 需手动调 save_local() | 每次操作后可自动或手动 .persist() |
| 适合场景 | 一次性构建、只读检索 | 需要动态更新、长期维护的知识库 |
以下是build_index.py,在索引构建阶段创建好向量数据库,为后续rag流程做准备:
(该代码只需运行一次即可)
import os
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_chroma import Chroma
knowledge_base_file = "war_and_peace.txt"
# 持久化目录: Chroma会把所有数据(向量+文本+元数据)都存到这个文件夹
persist_directory = './chroma_db_war_and_peace_bge_small_en_v1.5'
embedding_model = 'BAAI/bge-small-en-v1.5' # 如果愿意等待,可以换成模型"BAAI/bge-m3",效果更好更适合长文,但下载时间也更久(2.2G)
chunk_size = 500
chunk_overlap = 75
# 检查是否已创建
if os.path.exists(persist_directory):
print(f"检测到已存在的向量数据库: {persist_directory}")
print("跳过索引构建。如需重新构建,请手动删除该目录。")
exit()
if not os.path.exists(knowledge_base_file):
print(f"错误: 知识库文件 {knowledge_base_file} 未找到。")
print("请从 https://www.gutenberg.org/ebooks/2600.txt.utf-8 下载")
print("并重命名为 war_and_peace.txt 放在当前目录。")
exit()
print('---正在构建索引---')
# 1. 加载
loader = TextLoader(knowledge_base_file,encoding='utf8')
docs = loader.load()
print('加载完成...n')
# 2. 分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
splits = text_splitter.split_documents(docs)
print('分割完成...n')
# 3. 向量化 -- 第一次运行会下载模型,预计耗时2分钟
embedding_model = HuggingFaceEmbeddings(
model_name=embedding_model,
model_kwargs={'device':'cpu'}, # 强制模型在cpu上运行
encode_kwargs={'batch_size':64} # 每次处理64个文本片段
)
print('Embedding模型加载完成...n')
# 4. 存储
print('正在构建Chroma索引...(注:此步耗时较久,预计要3min)n')
db = Chroma(
persist_directory=persist_directory,
embedding_function=embedding_model
)
# 分批添加切片chunks(每批不超过 5000)
batch_size = 5000 # 必须 < 5461
for i in range(0, len(splits), batch_size):
batch = splits[i:i + batch_size]
db.add_documents(batch)
print(f"已插入 {min(i + batch_size, len(splits))} / {len(splits)} 条")
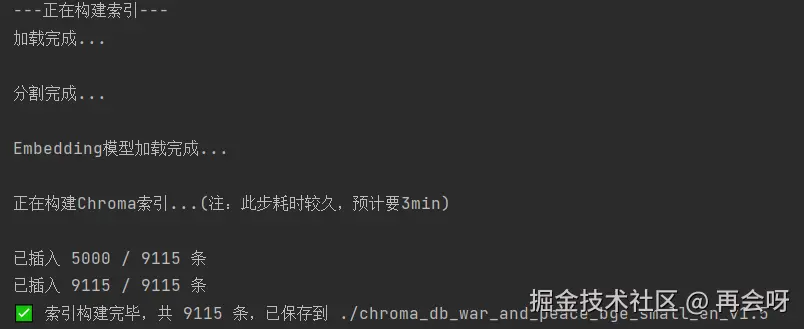
print(f' 索引构建完毕,共 {len(splits)} 条,已保存到 {persist_directory}')
注意:build_index.py 首次运行需下载模型并处理全文,耗时较长(约3–5分钟)。
为节省时间,项目已附带预构建好的向量数据库文件夹 chroma_db_war_and_peace_bge_small_en_v1.5,可直接使用,无需重复运行 build_index.py。
如需重建索引,请先手动删除该目录再运行脚本。
另外:
Langchain默认会一次性把所有chunk全部丢给Chroma,但Chroma一次只能接收至多5461条记录,所以我们得专门注意下分开传。本质是Langchain与Chroma的集成不太好。
编辑
编辑如上,向量数据库构建成功。
然后我们就可以实际用代码对接这个向量数据库,运行RAG链条,看效果如何:
import os
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_chroma import Chroma
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
Persist_directory = './chroma_db_war_and_peace_bge_small_en_v1.5'
Embedding_model = 'BAAI/bge-small-en-v1.5'
if not os.path.exists(Persist_directory):
print(f"错误: 知识库文件 {Persist_directory} 未找到。")
print("请先运行'build_index.py'生成向量数据库,再运行该文件")
exit()
print('---加载本地向量数据库---')
# 模块A:链接本地Chroma向量数据库
# 1. 加载 Embedding 模型
embedding_model = HuggingFaceEmbeddings(model_name=Embedding_model)
# 2. 从本地目录加载Chroma DB
db = Chroma(
persist_directory=Persist_directory,
embedding_function=embedding_model
)
print(f'Chroma数据库已从本地加载(共{db._collection.count()}条)nn')
# 模块B:R-A-G Flow
# 1. R-检索
retriever = db.as_retriever(search_kwargs={"k": 3}) # 召回3条相关数据
# 2. A-增强
sys_prompt = """
你是一个博学的历史学家和文学评论家。
请根据以下上下文回答问题。如果上下文**强烈暗示**了答案,即使未明说,也可推理回答。
如果完全无关,请回答“对不起,根据所提供的上下文我不知道”。
[上下文]: {context}
[问题]: {question}
"""
prompt = ChatPromptTemplate.from_messages([
('system', sys_prompt),
('human', '{question}')
])
# 3. G-生成
llm = ChatOpenAI(
model="deepseek-chat",
api_key=api_key,
base_url="https://api.deepseek.com"
)
# 4. 辅助函数
def format_docs(docs):
return "n".join(doc.page_content for doc in docs)
# 5. 组装RAG链条(LCEL)
rag_chain = (
{"context":retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 运行RAG链
print('---正在运行RAG链条---')
question = '莫斯科大火发生在小说的哪一部分?有哪些角色亲历了这场灾难?'
response = rag_chain.invoke(question)
print(f'提问:{question}')
print(f'回答:{response}')
运行完成,ai成功通过rag检索相关数据得到了我们想要的答案。
关于RAG运行的成功率,还要提及一个重点:
如果提示词写的非常死,它哪怕看到了很多关键信息,也会因为限制太死板不会正确输出。如果写的稍微松一点,LLM可以很轻松的通过相应内容判断出答案是什么。
可以看出,除了要在开头加载一下已构建好的向量数据库,其他操作几乎都用FAISS时相差不大。
但这个RAG链条的性能还是比较羸弱。比如这里如果我们问
“小说开篇的宴会是在谁家举办的?”、
“安德烈·博尔孔斯基第一次上战场是哪场战役?”等并非莫斯科大火这种强语义新号,文中反复提及的问题,这个RAG可能就检索不到。下面我们就来加强这个索引能力。
为何需要升级?
在基础 RAG 流程中,我们通常直接使用向量数据库的相似度检索结果:
# 1. R-检索
retriever = db.as_retriever(search_kwargs={"k": 3}) # 召回3条相关数据
这种做法存在明显局限:
为解决这一问题,我们需要在“粗召回”之后增加一个精排序(Re-ranking) 步骤。
我们将原始的单步检索拆解为以下三个阶段:
粗召回
扩大初始召回范围,获取更多候选文档:
base_retriever = db.as_retriever(search_kwargs={"k": 5}) # 海选 Top-5
精排序
引入交叉编码器(Cross-Encoder)对候选文档进行查询-文档对级别的相关性重打分:
encoder = HuggingFaceCrossEncoder(model_name="BAAI/bge-reranker-base")
reranker = CrossEncoderReranker(model=encoder, top_n=2) # 精选 Top-2
管道封装(Pipeline Integration)
使用将ContextualCompressionRetriever粗召回与精排序无缝串联:
compression_retriever = ContextualCompressionRetriever(
base_retriever=base_retriever, # 负责广度覆盖
base_compressor=reranker # 负责精度筛选
)
retriever = compression_retriever
R部分完整代码:(其他部分代码保持不变)
# 1. R (Retrieval - 检索)
# 1.1 基础检索器 (Base Retriever) - "粗召回"
base_retriever = db.as_retriever(search_kwargs={"k": 5}) # K 调大到 5
# 1.2 Reranker (重排器) - "精排序"
print("正在加载 Reranker 模型 (bge-reranker-base)...")
encoder = HuggingFaceCrossEncoder(model_name="BAAI/bge-reranker-base")
reranker = CrossEncoderReranker(model=encoder, top_n=2) # 只取精排后的 Top 2
# 1.3 【核心】创建“管道封装器”
compression_retriever = ContextualCompressionRetriever(
base_retriever=base_retriever, # 用Chroma做 海选
base_compressor=reranker # 用Reranker做 精选
)
retriever = compression_retriever
print("--- 检索器已升级为 Reranker 模式 ---")
提问:'皮埃尔是共济会成员吗?他在其中扮演什么角色?'
返回成功。
至此,RAG 的基础与进阶优化已基本完成。
作为 Agent 系统中最关键也最易被低估的模块之一,RAG 的构建质量直接决定了整个系统是否可用、可信、好用。
尤其需要注意:没有放之四海而皆准的 RAG 配置。
应根据文本规模、领域特性与查询复杂度,动态选择:
因此,在构建 Agent 时,请务必对 RAG 环节反复验证、持续调优。它不是一次性配置,而是需要随数据和任务演进的核心能力。
为何需要封装工具?
Agent 本身并不具备主动调用 RAG 的能力。
如果不加封装,RAG 只是一个固定的问答流程,无法融入 Agent 的自主决策循环。
通过将其封装为 Tool(工具) ,我们实现两个关键目标:
如何实现
这一步在代码上很简单,但思想上很重要。
我们把本篇第二章的“Chroma+Reranker”的强化版RAG链条,完整的封装成一个py函数search_war_and_peace(),然后用05篇学到的@tool装饰器把它注册给Agent即可。
核心代码处:
# (1) 构建一个可复用的 RAG链条 (P1+P2)
def build_rag_chain(llm_instance):
...
# 初始化RAG链
rag_chain_instance = build_rag_chain(llm)
# (2) 封装为标准 Langchain Tool
@tool
def search_war_and_peace(query):
"""查询《战争与和平》小说中的内容,包括人物、情节、历史事件等"""
print(f'n正在检索《战争与和平》:{query}')
return rag_chain_instance.invoke(query)
很明显能看出,我们这里并没有直接将其封装成@tool的工具,而是走了一个初始化链层。
这么做其实是出于性能考虑:
封装进@tool后,每次被llm调用时,这个tool都会运行一次。如果直接将整个rag链封装进去,那么每问一个问题都相当于重启一次RAG系统(加载embedding模型、打开Chroma数据库、初始化各种组件...),性能崩坏,延迟爆炸。
所以我们启动时,一次性构建完整RAG链;运行时,工具只调用已构建好的链即可。
完整代码如下:
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_chroma import Chroma
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain.retrievers import ContextualCompressionRetriever
from langchain_community.cross_encoders import HuggingFaceCrossEncoder
from langchain.retrievers.document_compressors import CrossEncoderReranker
from langchain_core.tools import tool
# 全局 LLM (供Agent和Rag共用)
llm = ChatOpenAI(
model="deepseek-chat",
api_key=api_key,
base_url="https://api.deepseek.com"
)
# (1) 构建一个可复用的 RAG链条 (P1+P2)
def build_rag_chain(llm_instance):
print('---正在构建RAG链条...---n')
Persist_directory = './chroma_db_war_and_peace_bge_small_en_v1.5'
Embedding_model = 'BAAI/bge-small-en-v1.5'
Encoder_model = "BAAI/bge-reranker-base"
if not os.path.exists(Persist_directory):
raise FileNotFoundError(f'索引目录{Persist_directory}未找到,请先运行 build_index.py')
embeddings_model = HuggingFaceEmbeddings(model_name=Embedding_model)
db = Chroma(
persist_directory=Persist_directory,
embedding_function=embeddings_model
)
# 1. R-检索--强化版
base_retriever = db.as_retriever(search_kwargs={"k":5})
encoder = HuggingFaceCrossEncoder(model_name=Encoder_model)
reranker = CrossEncoderReranker(model=encoder,top_n=2)
compression_retriever=ContextualCompressionRetriever(
base_retriever=base_retriever,
base_compressor=reranker
)
retriever = compression_retriever
# 2. A-增强
sys_prompt = """
你是一个博学的历史学家和文学评论家。
请根据以下上下文回答问题。如果上下文**强烈暗示**了答案,即使未明说,也可推理回答。
如果完全无关,请回答“对不起,根据所提供的上下文我不知道”。
[上下文]: {context}
[问题]: {question}
"""
prompt = ChatPromptTemplate.from_messages([
('system',sys_prompt),
('human','{question}')
])
# 3.G-生成(llm已在全局生成)
# 4. 辅助函数
def format_docs(docs):
return 'n'.join(doc.page_content for doc in docs)
# 5.组装RAG链条
rag_chain = (
{'context':retriever | format_docs, 'question': RunnablePassthrough()}
| prompt
| llm_instance
| StrOutputParser()
)
print('---RAG链条构建完毕!---n')
return rag_chain
# 初始化RAG链
rag_chain_instance = build_rag_chain(llm)
# (2) 封装为标准 Langchain Tool
@tool
def search_war_and_peace(query):
"""查询《战争与和平》小说中的内容,包括人物、情节、历史事件等"""
print(f'n正在检索《战争与和平》:{query}')
return rag_chain_instance.invoke(query)
# 也可以与其他工具并列使用
@tool
def get_weather(location):
"""模拟获得天气信息"""
return f"{location}当前天气:23℃,晴,风力2级"
tools = [search_war_and_peace,get_weather]
# 运行
if __name__ == '__main__':
question = "皮埃尔是共济会成员吗?他在其中扮演什么角色?"
res = search_war_and_peace.invoke(question)
print(f'问题:{question}')
print(f'回答:{res}')
运行成功。
RAG至此已可以被完整封装进tool工具内了。接下来我们就可以尝试真正构建一个涵盖六大模块的智能体。
为何要整合?
这是本系列第 02–07 篇内容的集大成之作。
在这个脚本中,我们首次将 LangChain 的 六大核心模块 完整融合到一个统一的智能体(Agent)实例中:
ChatOpenAI 作为 Agent 的“大脑”,负责推理与生成。ChatPromptTemplate 与 MessagesPlaceholder 精准控制 Agent 的行为逻辑。AgentExecutor 和 RunnableWithMessageHistory 本质上都是 Chain(即 Runnable),我们借助 LCEL(LangChain Expression Language)思想将它们无缝串联。RunnableWithMessageHistory 与 ChatMessageHistory 实现对话历史的记忆能力。create_tool_calling_agent 与 AgentExecutor 构建完整的 ReAct 循环,支持工具自动调用。search_war_and_peace)注入 Agent,使其具备访问私有知识库的能力。我们复用了第 05 篇中已验证的 带记忆的 Agent 框架(基于 RunnableWithMessageHistory),一举解决了两个关键痛点:
LLM 在 ReAct 的“思考”阶段,结合对话历史,自主决定如何调用工具,并生成一个更精准、语义完整、适合检索的查询字符串。该字符串作为工具参数传递给 RAG 工具,从而实现对上下文敏感的知识检索。
我们只需在原有 Agent 框架中注入 RAG 工具即可—— build_rag_chain 函数保持不变,其余结构沿用第 05 篇的记忆型 Agent:
def create_agent_with_memory():
# LLm
llm = ChatOpenAI(
model="deepseek-chat",
api_key=api_key,
base_url="https://api.deepseek.com"
)
# Prompt
prompt = ChatPromptTemplate.from_messages([
('system','你是一个强大的助手。你能查天气,也能查《战争与和平》。请尽力回答用户所提的所有问题。'),
MessagesPlaceholder(variable_name="history"), # 05篇所学:记忆占位符
('human','{input}'),
MessagesPlaceholder(variable_name="agent_scratchpad") # 05篇所学:ReAct 思考链,为其
])
# Tool
rag_chain_instance = build_rag_chain(llm_instance=llm)
@tool
def search_war_and_peace(query):
"""查询《战争与和平》小说中的内容,包括人物、情节、历史事件等"""
print(f'n正在检索《战争与和平》:{query}')
return rag_chain_instance.invoke(query)
@tool
def get_weather(location):
"""模拟获得天气信息"""
return f"{location}当前天气:23℃,晴,风力2级"
tools = [get_weather,search_war_and_peace]
# 创建Agent
agent = create_tool_calling_agent(llm=llm,tools=tools,prompt=prompt)
agent_executor = AgentExecutor(agent=agent,tools=tools,verbose=False)
# 封装Memory
store = {}
def get_session_history(session_id:int):
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
# 添加记忆功能
agent_with_memory = RunnableWithMessageHistory(
runnable=agent_executor,
get_session_history=get_session_history,
input_messages_key="input",
history_messages_key="history"
)
return agent_with_memory
# 测试
if __name__ == '__main__':
session_id = 'user123'
agent = create_agent_with_memory()
while 1:
user_input = input('n你:')
if user_input=='quit':
print('拜拜~')
exit()
response = agent.invoke(
{'input':user_input},
config={'configurable':{'session_id':session_id}}
)
print(f"AI:{response['output']}")
仅需极少改动,我们就将 RAG 能力无缝嵌入了具备长期记忆的智能体中。
运行测试:
编辑
Agent 不仅能调用外部工具(如天气),还能结合历史上下文精准查询私有知识库(如《战争与和平》),真正实现了 “通用能力 + 领域知识 + 对话记忆” 的统一。
这,就是 LangChain 六大模块协同工作的终极形态。
知识点概括:Chroma 持久化 | Reranker 精排 | RAG 工具化 | Langchain六大模块集成
本篇完成了 RAG 的“史诗级”升级:
这套“持久化 + 精排序 + Agent 工具化”的 RAG 架构,已足够健壮,可应对绝大多数 Agent 全栈开发的实战需求。
当前使用的 AgentExecutor 像一个“黑盒”——即使开启 verbose=True,我们也只能旁观 ReAct 循环,无法干预其流程。
想在工具调用后强制总结?想插入人工审核节点?它无能为力。
第 08 篇,我们将用 LangGraph 彻底打开这个黑盒!
不再依赖 AgentExecutor,而是亲手构建完全可控的 Agent 循环——
从使用者,变为创造者。

