
书城小说阅读器软件手机版
47.18MB · 2025-11-06

在AI的星辰大海中,总有那么几颗星光璀璨,让人不禁驻足仰望。最近,360集团便在多模态领域点亮了一颗耀眼的新星——FG-CLIP2。这款被360人工智能研究院倾力打造的视觉语言模型,不仅以开源之姿震撼登场,更在性能上实现了令人瞩目的飞跃,据称其综合实力已全面超越谷歌和Meta的同类别模型,为全球AI圈投下了一枚重磅炸弹。
传统CLIP模型,虽能在图文跨模态理解上大放异彩,却也常被戏称为AI的“近视眼”——能看清宏观轮廓,却对微观细节力不从心。例如,它能识别出一张“猫”的图片,却很难分辨出是“一只狸花猫和屏幕中的英短相互对视”,更别提区分“白色蕾丝边、袖口有珍珠装饰的连衣裙”和普通的白色连衣裙了。
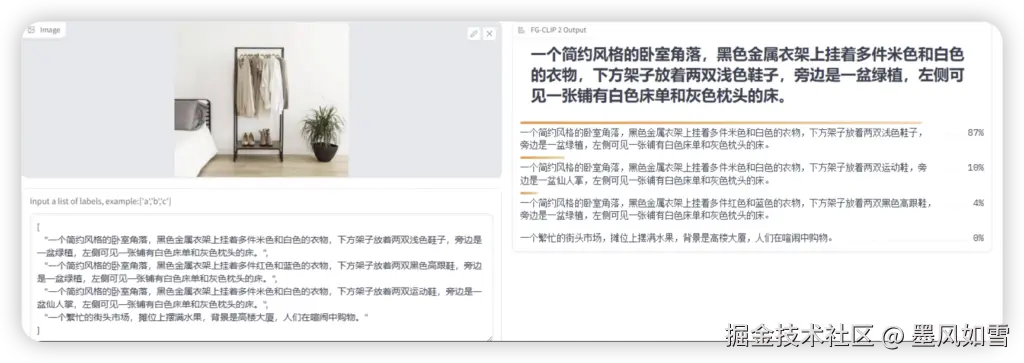
而FG-CLIP2的核心突破,正是要彻底治愈AI的“近视”,让它真正拥有“火眼金睛”。它不再满足于宏观语义的匹配,而是致力于捕捉图像中的每一个像素级细节,理解物体属性、空间关系,甚至是细微的情绪表达。这不仅仅是性能的提升,更是AI认知能力的一次根本性飞跃,从“看得见”迈向了“看得清”,彻底颠覆了我们对视觉语言模型的想象。
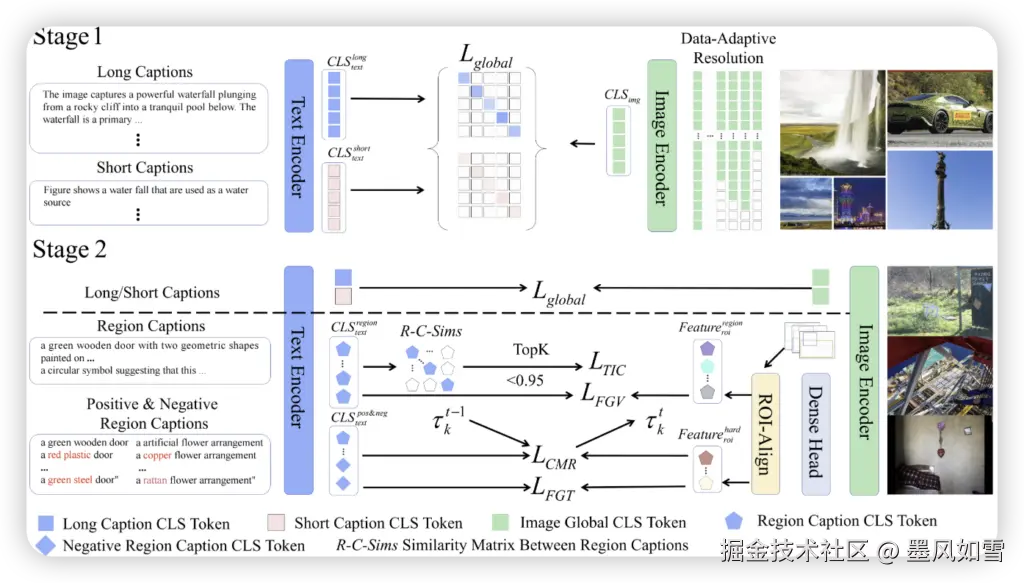
FG-CLIP2这双“火眼金睛”并非凭空出现,而是基于一系列深度的技术创新和精心的训练策略打磨而成。
首先是其核心创新点:
而在幕后,是360自研的超大规模高质量数据集FineHARD的默默支撑。这个数据集不仅包含详尽的全局与局部区域描述,更创新性地引入了千万级由大模型生成的“难负样本”,它们往往只有毫厘之差,却能极大地锤炼模型的辨别力,让它在细微之处也能洞察秋毫。
训练方法上,FG-CLIP2采用了精妙的两阶段策略。第一阶段,模型学习图像与文本的全局语义对齐,打下坚实基础;而真正实现细粒度理解的“点睛之笔”,则发生在第二阶段——模型摒弃了传统的“整体对整体”对齐,大胆升级为“局部对局部”的精细对齐,将文本中的具体词汇与图像中的特定区域精准关联起来,如同给每一个细节都找到了专属的“身份证”。
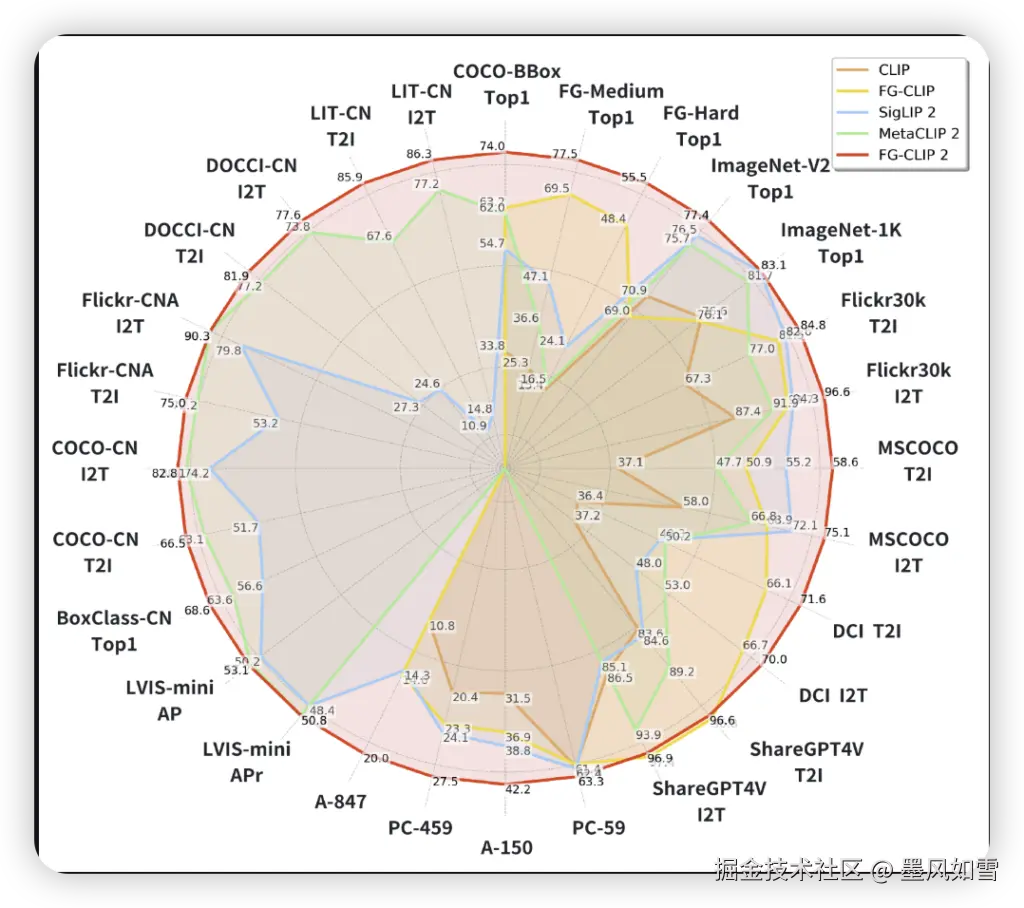
而所有这些努力,最终都转化为了令人信服的成绩单。在涵盖图文检索、零样本图像分类、开放词汇目标检测等8大类任务的29个全球公开基准测试中,FG-CLIP2如同开挂一般,全面超越了谷歌的SigLIP 2和Meta的MetaCLIP 2,实力登顶,成为当前性能最佳的双语视觉语言模型。无论是在英文任务的平均性能,还是在细粒度理解和中文图文检索上的卓越表现,都足以证明其领先地位。
FG-CLIP2的“细粒度”视觉理解能力,不仅仅停留在实验室的辉煌,更拥有改变世界的巨大潜力:
360 FG-CLIP2的开源,不仅是360的技术里程碑,更是中国AI乃至全球多模态领域的一大步。它预示着多模态基础模型的发展,正从追求规模转向了追求精度与实用性。未来,我们有理由相信,这双“火眼金睛”将赋能更多行业,开启AI应用的新篇章。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!
公众号:墨风如雪小站

