先发制人2026
72.36M · 2026-03-22

对于 Apache Doris 这样的高性能分析型数据库而言,高效、稳定的数据导入是保障实时分析能力的生命线。然而,在海量数据持续写入的场景下,如何平衡导入延迟与吞吐、如何避免性能瓶颈,是开发者面临的核心挑战。本文将深入剖析 Doris 数据导入的核心原理,涵盖关键流程、组件、事务管理等,探讨影响导入性能的因素,并提供实用的优化方法和最佳实践,有助于用户选择合适的导入策略,优化导入性能。
Doris 的数据导入原理建立在其分布式架构之上,主要涉及前端节点(Frontend, FE)和后端节点(Backend, BE)。FE 负责元数据管理、查询解析、任务调度和事务协调,而 BE 则处理实际的数据存储、计算和写入操作。Doris 的数据导入设计旨在满足多样化的业务需求,包括实时写入、流式同步、批量加载和外部数据源集成。其核心理念包括:
Doris 的数据导入遵循一个标准化的核心流程,主要包括以下几个阶段:
1、提交导入任务
2、任务分配与协调
3、数据读取与分发
4、数据写入
Doris 的高吞吐写入得益于其独特的数据模型与 LSM Tree(Log-Structured Merge-Tree)存储结构的结合。LSM Tree 是一种高效的磁盘写入优化结构,通过将写操作分为内存和磁盘两个阶段,显著提升了写入性能。其核心思想是将随机写转换为顺序写,减少磁盘 I/O 开销,同时通过多级合并(Compaction)维护数据的有序性和查询效率。
数据首先分发到多个 BE(Backend)节点,写入内存表(MemTable),并按 Key 列进行排序。对于 Aggregate 或 Unique Key 数据模型,Doris 会根据 Key 执行聚合或去重操作(如 SUM、REPLACE),减少数据冗余,提升查询性能。
当 MemTable 写满(默认 200MB)或任务结束时,数据会异步写入磁盘,形成列式存储的 Segment 文件,并组成 Rowset。LSM Tree 的内存写入和异步刷盘机制确保了高吞吐量,同时通过后台的 Compaction 过程定期合并 Segment 文件,优化存储结构和查询效率。
每个 BE 节点独立处理分配的数据,写入完成后向 Coordinator 报告状态,确保分布式环境下写入操作的可靠性和一致性。
5、事务提交与发布
6、结果返回
在冲突解决方面, 经典的写写冲突会导致写入无法并行,从而显著降低写入吞吐量。Doris 提供了基于业务语义的冲突机制,可很好避免该问题(参考文档)。而 Redshift、Snowflake、Iceberg 和 Hudi 等则采用了文件级别的冲突处理,因而不具备实时更新的能力。
MemTable 前移是 Apache Doris 2.1.0 版本引入的优化机制,针对 INSERT INTO…SELECT 导入方式显著提升性能,官方测试显示该优化使得单副本导入耗时缩短约 64%(为原先的 36%),三副本导入耗时缩短约 46%(为原先的 54%),传统流程中,Sink 节点需将数据编码为 Block 格式,通过 Ping-pong RPC 传输到下游节点,涉及多次编码和解码,增加开销。Memtable 前移优化了这一过程:Sink 节点直接处理 MemTable,生成 Segment 数据后通过 Streaming RPC 传输,减少编码解码和传输等待,同时提供更准确的内存反压。目前该功能只支持存算一体部署模式。
在存算分离架构下,导入优化聚焦数据存储和事务管理解耦:
Doris 提供多种导入方式,共享上述原理,但针对不同场景优化。用户可根据数据源和业务需求选择:
Doris 的导入性能受其分布式架构与存储机制影响,核心涉及 FE 元数据管理、BE 并行处理、MemTable 缓存刷盘及事务管理等环节。以下从表结构设计、攒批策略、分桶配置、内存管理和并发控制等维度,结合导入原理说明优化策略及其有效性。
Doris 的导入流程中,数据需经 FE 解析后,按表的分区和分桶规则分发至 BE 节点的 Tablet(数据分片),并在 BE 内存中通过 MemTable 缓存、排序后刷盘生成 Segment 文件。表结构(分区、模型、索引)直接影响数据分发效率、计算负载和存储碎片。
通过按业务查询模式(如时间、区域)划分分区,导入时数据仅分发至目标分区,避免处理无关分区的元数据和文件。同时写入多个分区会导致大量 Tablet 活跃,每个 Tablet 占用独立的 MemTable,显著增加 BE 内存压力,可能触发提前 Flush,生成大量小 Segment 文件。这不仅增加磁盘或对象存储的 I/O 开销,还因小文件引发频繁 Compaction 和写放大,降低性能。通过限制活跃分区数量(如逐天导入),可减少同时活跃的 Tablet 数,缓解内存紧张,生成更大的 Segment 文件,降低 Compaction 负担,从而提升并行写入效率和后续查询性能。
明细模型(Duplicate Key)仅存储原始数据,无需聚合或去重计算;而 Aggregate 模型需按 Key 列聚合,Unique Key 模型需去重,均会增加 CPU 和内存消耗。对于无需去重或聚合的场景,优先使用明细模型,可避免 BE 节点在 MemTable 阶段的额外计算(如排序、去重),降低内存占用和 CPU 压力,进而加速数据写入流程。
索引(如位图索引、倒排索引)需在导入时同步更新,否则会增加写入时的维护成本。仅为高频查询字段创建索引,避免冗余索引,可减少 BE 写入时的索引更新操作(如索引构建、校验),降低 CPU 和内存占用,来提升导入吞吐量。
Doris 的每个导入任务为独立事务,涉及 FE 的 Edit Log 写入(记录元数据变更)和 BE 的 MemTable 刷盘(生成 Segment 文件)。高频小批量导入(如 KB 级别)会导致 Edit Log 频繁写入(增加 FE 磁盘 I/O)、MemTable 频繁刷盘(生成大量小 Segment 文件,触发 Compaction 写放大),显著降低性能。
客户端将数据攒至数百 MB 到数 GB 后一次性导入,减少事务次数。单次大事务替代多次小事务,可降低 FE 的 Edit Log 写入频率(减少元数据操作)及 BE 的 MemTable 刷盘次数(减少小文件生成),避免存储碎片和后续 Compaction 的资源消耗。
开启 Group Commit 后,服务端将短时间内的多个小批量导入合并为单一事务,减少 Edit Log 写入次数和 MemTable 刷盘频率。合并后的大事务生成更大的 Segment 文件(减少小文件),减轻后台 Compaction 压力,特别适用于高频小批量场景(如日志、IoT 数据写入)。
分桶数决定 Tablet 数量(每个桶对应一个 Tablet),直接影响数据在 BE 节点的分布。过少分桶易导致数据倾斜(单 BE 负载过高),过多分桶会增加元数据管理和分发开销(BE 需处理更多 Tablet 的 MemTable 和 Segment 文件)。
分桶数需根据 BE 节点数量和数据量设置,推荐单 Tablet 压缩后的数据大小为 1-10GB(计算公式:分桶数=总数据量/(1-10GB))。同时,调整分桶键(如随机数列)避免数据倾斜。合理分桶可平衡 BE 节点负载,避免单节点过载或多节点资源浪费,提升并行写入效率。
在随机分桶场景中,启用load_to_single_tablet=true,可将数据直接写入单一 Tablet,绕过分发到多个 Tablet 的过程。这消除了计算 Tablet 分布的 CPU 开销和 BE 间的 RPC 传输开销,显著提升写入速度。同时,集中写入单一 Tablet 减少了小 Segment 文件的生成,避免频繁 Compaction 带来的写放大,降低减少 BE 的资源消耗和存储碎片,提升导入和查询效率。
数据导入时,BE 先将数据写入内存的 MemTable(默认 200MB),写满后异步刷盘生成 Segment 文件(触发磁盘 I/O)。高频刷盘会增加磁盘或对象存储(存算分离场景)的 I/O 压力;内存不足则导致 MemTable 分散(多分区/分桶时),易触发频繁刷盘或 OOM。
按分区顺序(如逐天)导入,集中数据写入单一分区,减少 MemTable 分散(多分区需为每个分区分配 MemTable)和刷盘次数,降低内存碎片和 I/O 压力。
对大文件或多文件导入(如 Broker Load),建议分批(每批≤100GB),避免导入出错后带来过大的重试代价过大,同时减少对 BE 内存和磁盘的集中占用。本地大文件可使用streamloader工具自动分批导入。
Doris 的分布式架构支持多 BE 并行写入,增加并发可提升吞吐量,但过高并发会导致 CPU、内存或对象存储 QPS 争抢(存算分离场景需考虑 S3 等 API 的 QPS 限制),会增加事务冲突和延迟。
结合 BE 节点数和硬件资源(CPU、内存、磁盘 I/O)设置并发线程。适度并发可充分利用 BE 并行处理能力,提升吞吐量;过高并发则因资源争抢降低效率。
对低时延要求场景(如实时监控),需降低并发数(避免资源竞争),并结合 Group Commit 的异步模式(async_mode)合并小事务,减少事务提交延迟。
在使用 Apache Doris 时,数据导入的 延迟(Latency) 与 吞吐量(Throughput) 往往需要在实际业务场景中进行平衡:
因此,建议用户在满足业务时延要求的前提下,尽量增大单次导入写入的数据量,以提升吞吐并减少系统开销。
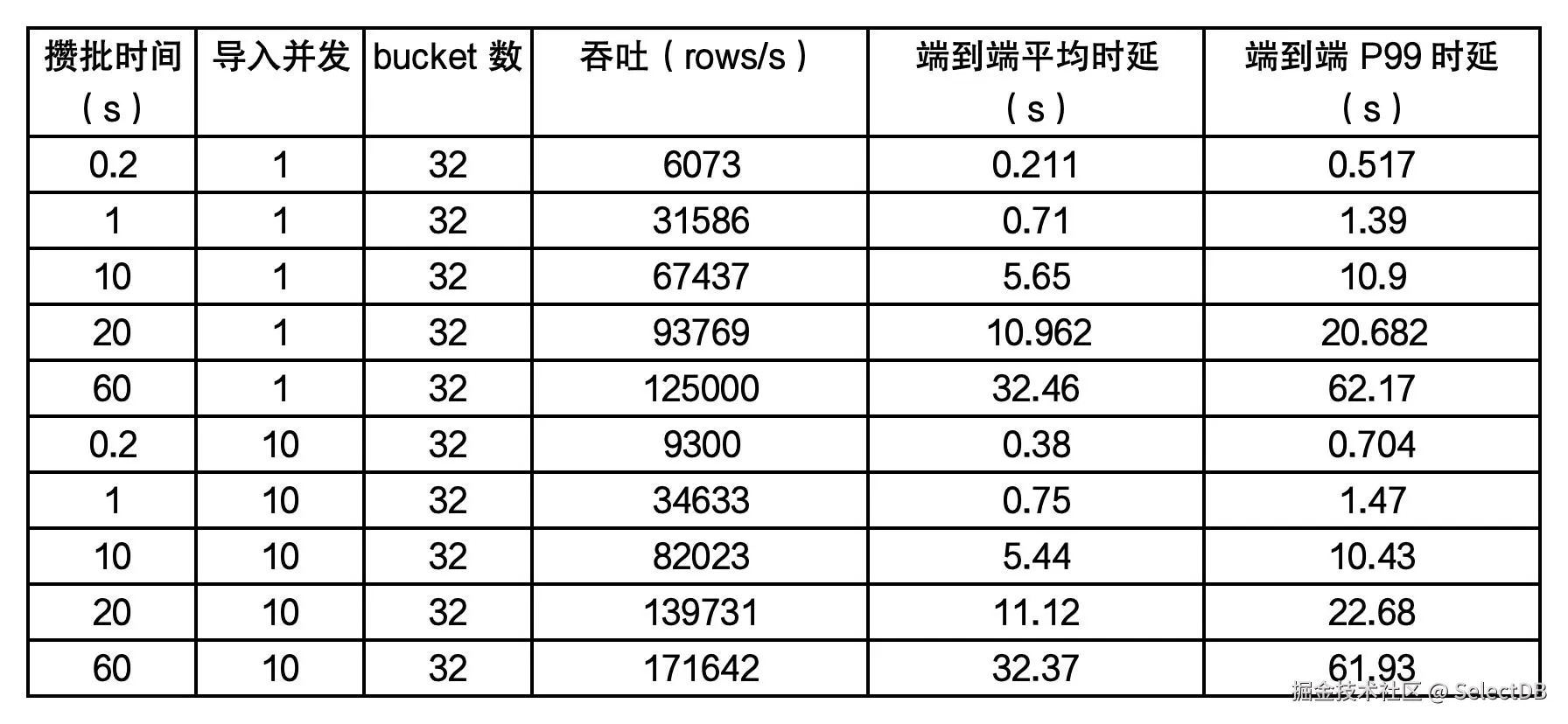
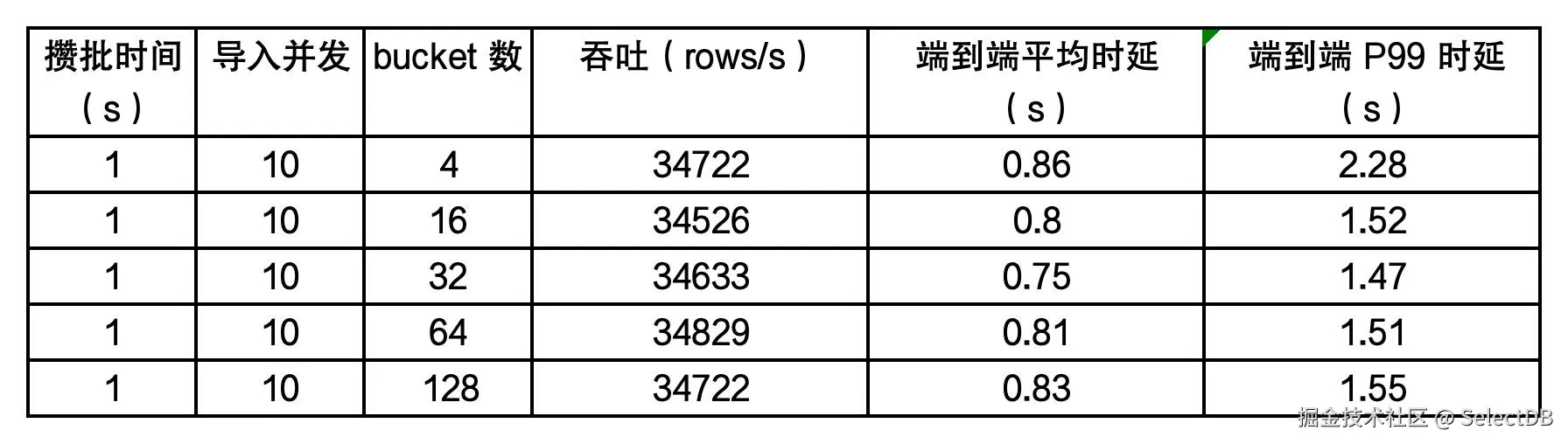
采用 Flink Connector 使用攒批模式进行写入,主要关注数据端到端的时延和导入吞吐。攒批时间通过 flink Connector 的 sink.buffer-flush.interval 参数来控制的,Flink Connector 的详细使用参考:doris.apache.org/docs/3.0/ec…
机器配置:
数据集:
不同攒批时间和不同并发下的导入性能,测试结果如下:
不同 bucket 数对导入性能的影响,测试结果如下:
性能测试数据参考:doris.apache.org/zh-CN/docs/…
Apache Doris 的数据导入优化并非单一参数的调整,而是一个涉及表结构设计、写入策略、资源配置与业务场景的系统性工程。 数据导入机制依托 FE 和 BE 的分布式协作,结合事务管理和轻量 ETL 功能,来确保高效、可靠的数据写入。频繁小批量导入会增加事务开销、存储碎片和 Compaction 压力,可以通过以下优化策略来有效缓解:
用户可根据业务场景(如实时日志、批量 ETL)结合这些策略,优化表设计、参数配置和资源分配,可以显著提升导入性能。

