爱奇艺pps影音通用版
98.3MB · 2025-10-28

本文涵盖 AI 基础设施的方方面面,从硬件加速、模型服务到监控与安全,提供了经过生产环境验证的工具、模式及策略。
构建稳健的 AI 基础设施,需要理解跨多个技术层级的理论基础与实际实现细节。本综合指南为各类规模 AI 系统的架构设计、部署及管理提供了权威参考——无论是实验性原型,还是服务数百万用户的企业级生产部署均可适用。
现代 AI 应用对基础设施提出了严苛要求:需承载大型语言模型的计算强度、多智能体系统的复杂性,以及交互式应用的实时性需求。核心挑战不仅在于选择合适的工具,更在于理解这些工具如何在整个技术栈中协同集成,从而交付可靠、可扩展且经济高效的解决方案。
本文涵盖 AI 基础设施的全维度内容,从硬件加速、模型服务到监控与安全,详细解析了经过生产环境验证的开源工具、架构模式及实施策略。
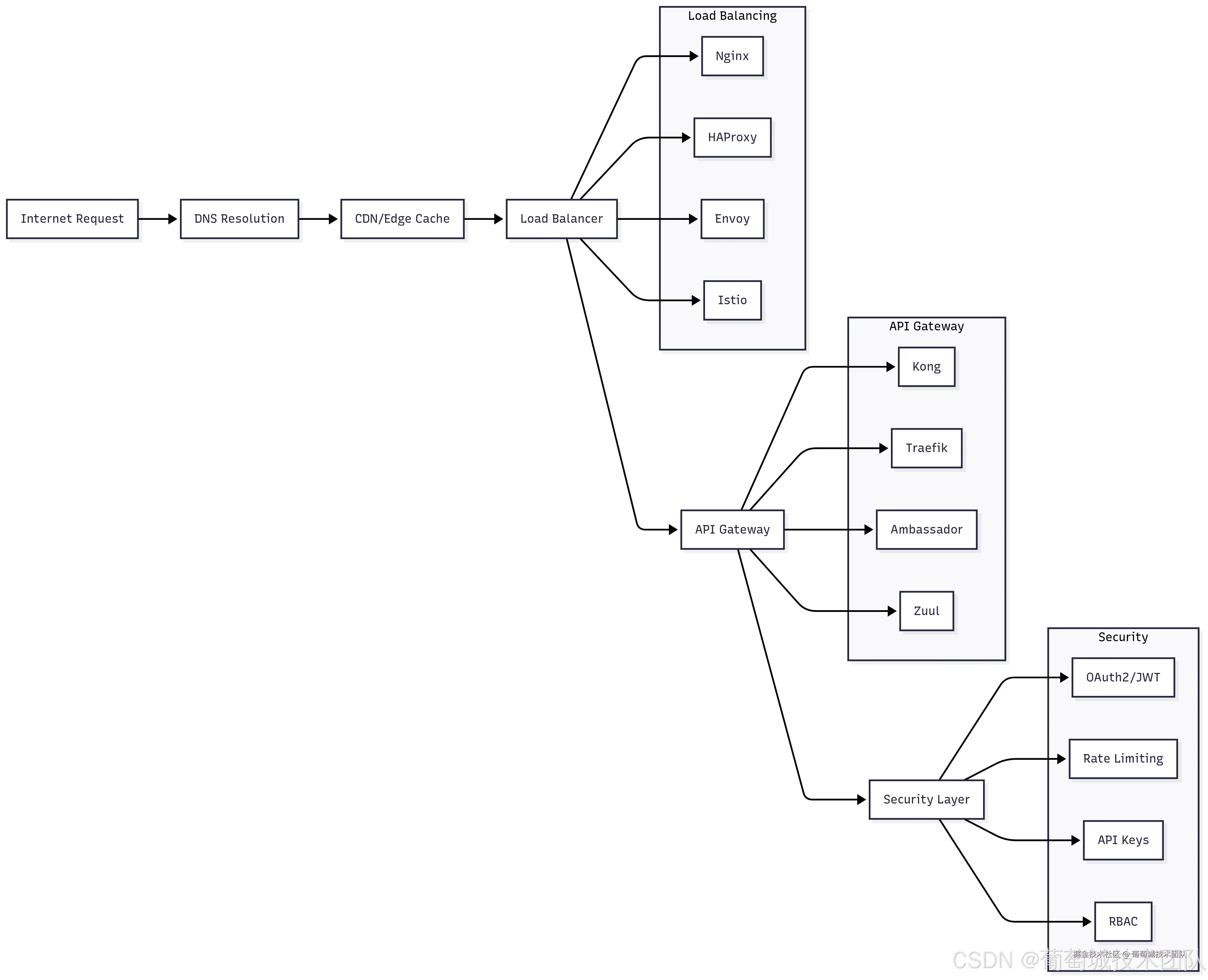
应用网关层是 AI 基础设施的“前门”,负责处理所有外部流量,并提供安全、限流、负载均衡等核心横切关注点。该层对生产部署至关重要——既能作为抵御恶意流量的第一道防线,又能确保合法请求的优化分发。
Nginx 凭借其成熟的稳定性、详尽的文档及强大的配置能力,仍是负载均衡的首选工具。针对 AI 工作负载,Nginx 能高效处理其多样化的流量模式——从短时长的 API 调用到长时运行的流式响应。其上游模块支持复杂的健康检查,可精准检测 AI 服务是否过载或出现高推理延迟。
AI 模型服务配置示例:
upstream ai_models {
server model-server-1:8000 weight=3 max_fails=3 fail_timeout=30s;
server model-server-2:8000 weight=3 max_fails=3 fail_timeout=30s;
server model-server-3:8000 weight=2 max_fails=3 fail_timeout=30s;
}
server {
location /v1/chat/completions {
proxy_pass http://ai_models;
proxy_read_timeout 300s; # AI 推理的长超时设置
proxy_buffering off; # 启用流式响应
}
}
HAProxy 提供了对 AI 应用尤为实用的高级特性,包括连接池、熔断器,以及可监控推理延迟、队列深度等 AI 专属指标的复杂健康检查。其统计界面能实时展示流量分布及后端服务健康状态。
Envoy 在云原生环境中备受青睐,得益于其丰富的功能集及与服务网格技术的深度集成。针对 AI 应用,Envoy 的动态配置能力极具价值——可基于模型性能或容量变化实时调整路由规则。
Kong 因丰富的插件生态在 AI 应用中脱颖而出,其插件包括专为 AI 工作负载设计的令牌计数限流、多模型 API 的请求/响应转换,以及 AI 指标的全面分析功能。Kong 的声明式配置方式,便于跨多个 AI 服务管理复杂的路由规则和安全策略。
Traefik 在容器化环境中表现卓越,具备自动服务发现能力。对于部署在 Kubernetes 中的 AI 应用,Traefik 可自动发现新的模型服务,并基于标签和注解配置路由规则,大幅降低运维开销。
AI API 网关的核心考量因素:
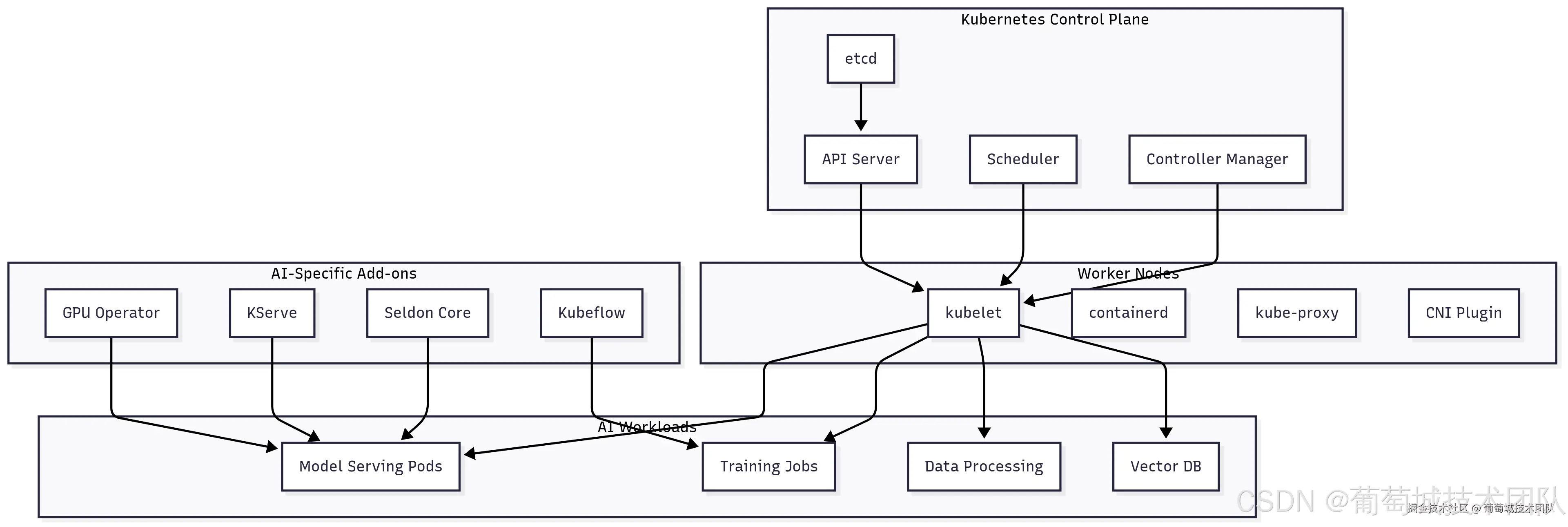
服务编排层负责管理 AI 服务的复杂生命周期,涵盖从初始部署到自动扩缩容、滚动更新的全流程。该层对 AI 应用尤为关键,因其具有独特特性:高资源需求、长启动时间,以及基于推理需求(而非传统 Web 流量模式)的动态扩缩容需求。
Kubernetes 控制平面组件:etcd、API 服务器、调度器、控制器管理器 AI 专属插件:GPU 操作员(GPU Operator)、KServe、Seldon Core、Kubeflow 工作节点组件:kubelet、containerd、kube-proxy、CNI 插件 AI 工作负载:模型服务 Pod、训练任务、数据处理、向量数据库
Kubernetes 凭借强大的调度能力、丰富的生态系统及活跃的社区支持,已成为 AI 工作负载编排的事实标准。然而,AI 工作负载面临独特挑战,需在资源管理、调度策略及运维实践方面重点考量。
NVIDIA GPU Operator 简化了 Kubernetes 集群中的 GPU 管理——可自动安装和管理必要的驱动程序、运行时及监控工具。其支持 GPU 共享等高级特性,允许多个容器共享单个 GPU,这对未充分利用 GPU 容量的推理工作负载尤为实用。
核心配置示例:
apiVersion: v1
kind: Pod
spec:
containers:
- name: ai-inference
image: ai-model:latest
resources:
limits:
nvidia.com/gpu: 1
memory: 32Gi
requests:
nvidia.com/gpu: 1
memory: 16Gi
env:
- name: CUDA_VISIBLE_DEVICES
value: "0"
AI 工作负载需要超越简单 CPU/内存限制的复杂资源管理策略,关键考量包括:
KServe 提供了 Kubernetes 原生的机器学习模型部署与管理平台,支持金丝雀部署、A/B 测试及基于推理指标的自动扩缩容等高级特性。其抽象层使数据科学家无需深入掌握 Kubernetes 知识即可部署模型,同时为平台工程师提供资源分配和扩缩容策略的精细化控制能力。
Seldon Core 提供企业级模型服务能力,支持复杂推理图、可解释性分析及漂移检测。其架构支持多模型链式部署,可基于实时性能指标或业务规则做出路由决策。
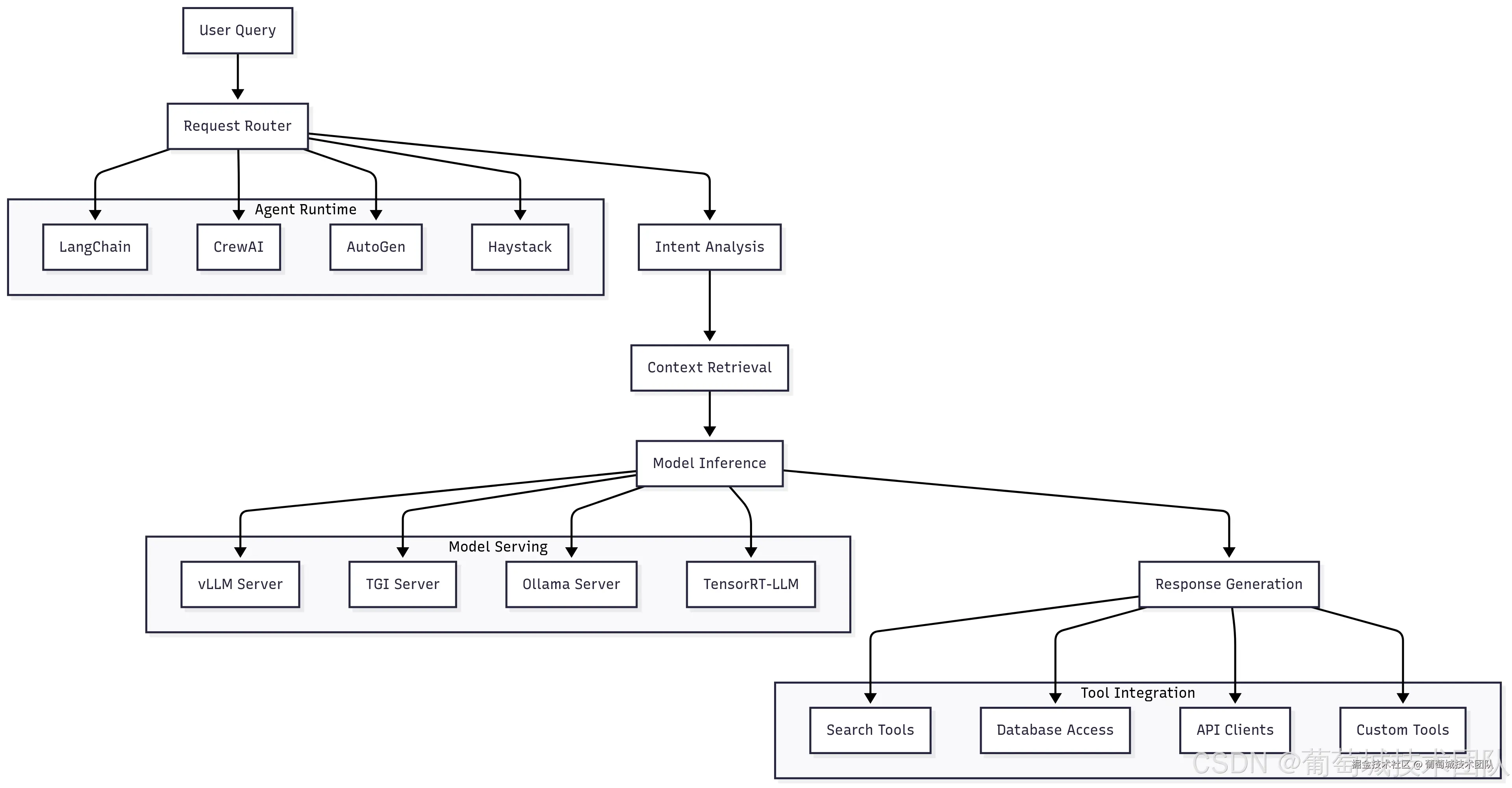
AI 服务层是 AI 基础设施的核心,承载着实际的智能能力。该层包含模型服务引擎、智能体编排系统及工具集成框架,支撑复杂 AI 工作流的运行。其架构直接影响 AI 应用的用户体验、系统性能及运维复杂度。
vLLM 凭借创新的分页注意力(PagedAttention)算法和连续批处理能力,已成为高吞吐量 LLM 推理的首选方案。分页注意力通过将注意力键值对存储在非连续内存块中(类似操作系统管理虚拟内存的方式),消除了内存碎片,相比传统方法可减少高达 50% 的内存占用,从而支持更大批处理量和更高的 GPU 利用率。
连续批处理特性允许请求到达后立即处理,而非等待固定批大小,在保持高吞吐量的同时显著降低平均延迟。对于生产部署,vLLM 支持跨多 GPU 的张量并行,可服务单 GPU 内存无法容纳的大型模型。
配置示例:
from vllm import LLM, SamplingParams
llm = LLM(
model="meta-llama/Llama-2-70b-chat-hf",
tensor_parallel_size=4, # 使用 4 块 GPU
max_model_len=4096,
gpu_memory_utilization=0.9
)
sampling_params = SamplingParams(
temperature=0.8,
top_p=0.95,
max_tokens=512
)
Hugging Face 的文本生成推理(TGI)提供生产级模型服务,具备全面监控、流式响应及兼容 OpenAI 的 API 等企业级特性。TGI 在运维简化和监控需求优先的环境中表现突出,内置指标采集、健康检查功能,并支持与主流可观测性工具集成。
Ollama 因其简洁性和全面的模型管理能力,在边缘部署和开发环境中广受青睐。它可自动处理模型下载、量化及优化,非常适合易用性优先于极致性能的场景。
LangChain 为构建 AI 智能体提供了最全面的生态系统,支持与工具、数据源及模型提供商的广泛集成。其模块化架构允许开发者通过可复用组件构建复杂工作流,同时详尽的文档和社区支持降低了不同 AI 专业水平开发者的使用门槛。
生产部署中的核心 LangChain 组件:
CrewAI 专注于多智能体场景,支持不同 AI 智能体协作解决复杂问题。其基于角色的设计支持复杂团队协作模式——智能体具备专业能力,可相互委派任务,这对需要多领域专家参与的复杂企业级工作流尤为重要。
微软的 AutoGen 提供了对话式 AI 系统框架,支持多智能体通过双向对话解决问题。其优势在于需要不同 AI 视角进行协商、辩论或协作解决问题的场景。
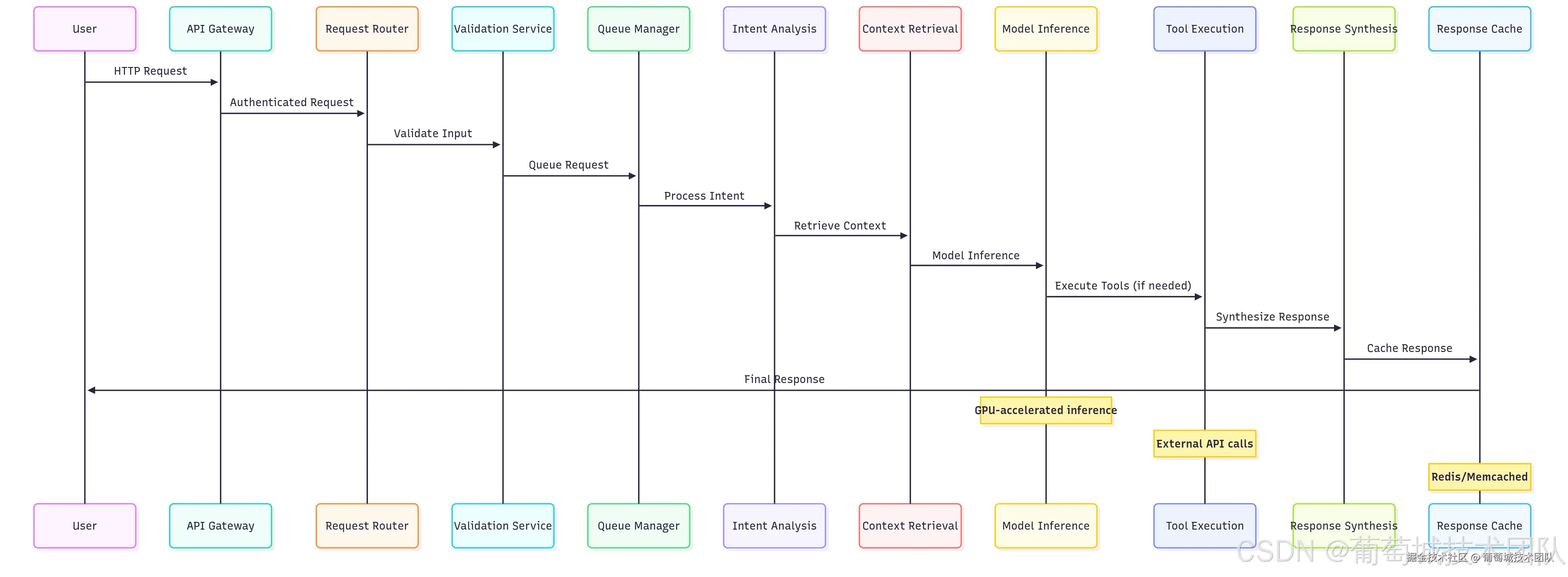
理解完整的推理流程对于优化性能、调试问题及设计稳健的 AI 系统至关重要。该流程涵盖从请求验证到响应交付的全链路,每个阶段均存在性能优化空间。
用户请求流程:API 网关 → 请求路由器 → 验证服务 → 队列管理器 → 意图分析 → 上下文检索 → 模型推理 → 工具执行(如需)→ 响应合成 → 响应缓存 → 最终响应 关键组件:GPU 加速推理、外部 API 调用、Redis / Memcached 缓存
输入验证阶段对安全性和性能均至关重要。对于 AI 应用,验证不仅涵盖传统 Web 应用的关注点,还包括:
Pydantic 凭借强大的类型系统和验证规则,为 AI 应用提供了出色的验证支持:
from pydantic import BaseModel, Field, validator
from typing import List, Optional
class ChatRequest(BaseModel):
messages: List[dict] = Field(..., min_items=1, max_items=100)
max_tokens: Optional[int] = Field(512, gt=0, le=4096)
temperature: float = Field(0.7, ge=0.0, le=2.0)
@validator('messages')
def validate_messages(cls, v):
total_tokens = estimate_tokens(v)
if total_tokens > 8000:
raise ValueError('消息总令牌数超出限制')
return v
检索增强生成(RAG)已成为生产级 AI 应用的核心组件,使模型能够访问最新信息和领域专属知识。上下文检索阶段涉及多项复杂操作:
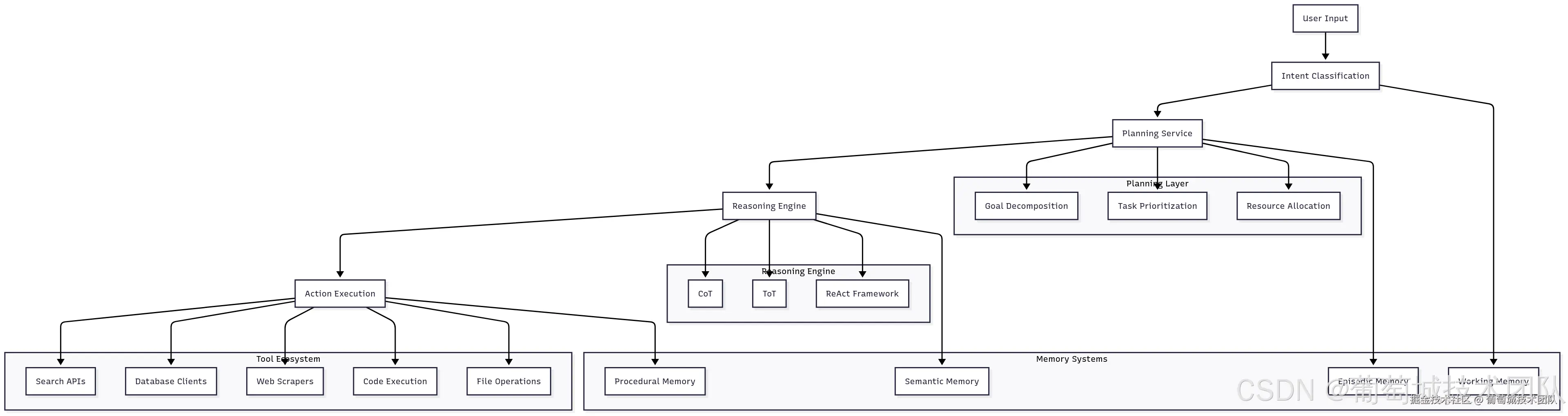
AI 智能体代表了 AI 应用的下一代演进——超越简单问答,迈向具备复杂推理和行动能力的系统。智能体的基础设施需求比传统模型服务更为复杂,因其需要编排多个服务、维护长对话状态,并与外部系统集成。
用户输入流程:用户输入 → 意图分类 → 规划服务 → 智能体执行 → 响应输出
规划服务负责将复杂用户请求分解为可执行的子任务,包括理解用户意图、识别达成目标所需步骤,以及创建考虑可用资源和潜在故障模式的执行计划。
现代规划系统采用融合经典 AI 规划技术与 LLM 推理的复杂算法,需重点考量:
推理引擎采用不同的认知架构解决问题:
本文作为 AI 基础设施系列文章的第二篇,详细解析了 AI 基础设施栈的部分核心层级——从 AI 网关、负载均衡、服务编排,到 AI 服务层架构,再到推理流程与智能体架构流程。系列后续文章将聚焦 AI 基础设施的计算、存储和可观测性栈,涵盖遥测、合规性、安全性、性能优化等关键主题,并提供更深入的优化解析。

