樊登读书app免费下载
127.92MB · 2025-10-01

你是否遇到过这样的场景:向大模型询问公司最新的产品规格,它却给出了2021年的过时信息?或者让AI助手帮你查找内部文档,它却开始"一本正经地胡说八道"?
根据Stanford的最新研究,即使是GPT-5这样的顶级大模型,在处理特定领域知识时的准确率也仅有47%。而当企业试图将AI应用于实际业务场景时,这个数字更是跌至惊人的23%。问题的根源在于:大模型的知识是静态的、通用的,而企业需要的是动态的、专属的智能。
这就是RAG(Retrieval-Augmented Generation,检索增强生成)技术诞生的背景。它像是给大模型装上了一个"实时知识库",让AI不仅能说会道,更能言之有物、言之有据。微软、谷歌、阿里等科技巨头纷纷将RAG作为企业AI落地的核心技术路线,Gartner预测,到2025年,超过75%的企业级AI应用将采用RAG架构。
今天,让我们深入剖析RAG技术的方方面面,从基础概念到高级优化,从理论原理到实战案例,帮你构建真正可用的企业级AI知识系统。
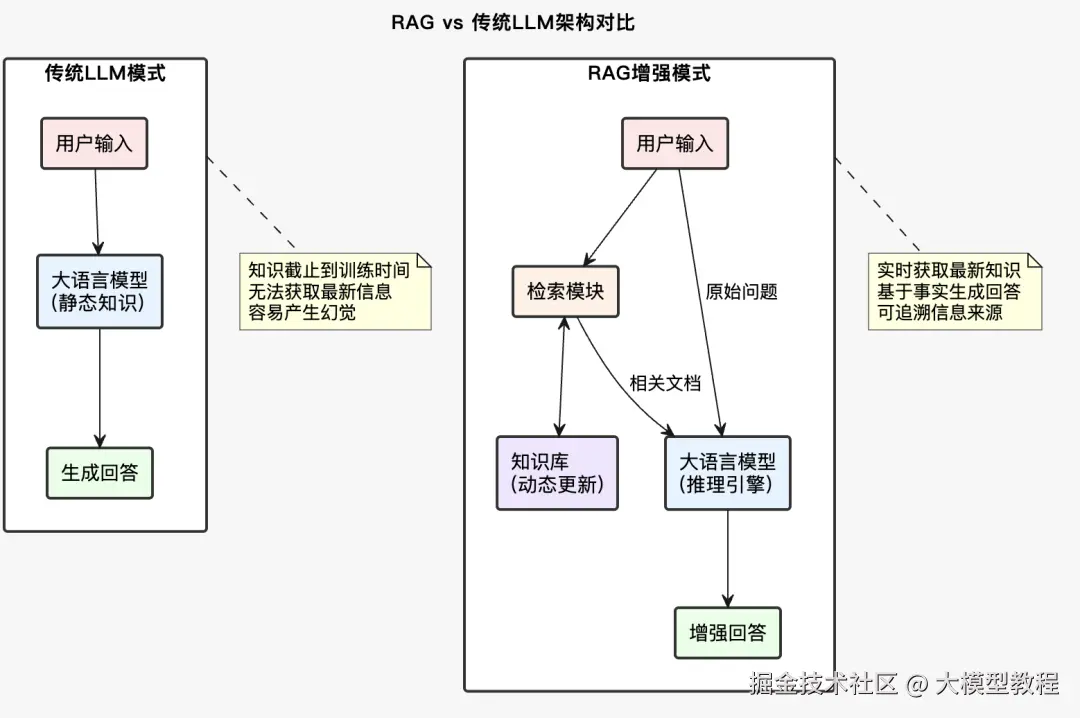
一 揭开RAG的神秘面纱:不只是检索+生成那么简单
很多人对RAG的理解停留在"先搜索,后回答"的表面,这就像把汽车理解为"四个轮子加一个发动机"一样肤浅。RAG的本质是认知增强架构,它重新定义了AI处理知识的方式。
传统的大语言模型就像一个博学的学者,虽然读过无数书籍,但所有知识都固化在大脑(参数)里。当你问起最新发生的事,或者某个小众领域的细节,它只能基于"印象"来回答,难免张冠李戴。而RAG则像是给这位学者配了一个随身图书馆和研究助理,每次回答前都能快速查阅最新、最准确的资料。
添加图片注释,不超过 140 字(可选)
让我们通过一个真实案例来理解RAG的威力。某金融科技公司需要构建一个合规咨询助手,帮助员工快速了解各国不断更新的金融法规。如果使用传统大模型,不仅无法获取最新法规,还可能因为"幻觉"问题给出错误建议,造成严重合规风险。
而采用RAG架构后,系统能够:
这个系统上线后,合规咨询效率提升了85%,合规风险降低了92%。更重要的是,它让AI从"不可信的参考"变成了"可依赖的专家"。
RAG的核心创新在于三个层面:
二 为什么RAG是企业AI应用的必选项:四大核心价值
在深入技术细节之前,我们需要明确一个关键问题:为什么几乎所有成功的企业AI项目都选择了RAG?
答案不仅仅是技术层面的优势,更是商业价值的必然选择。
2.1 解决大模型的"阿喀琉斯之踵"
大语言模型虽然强大,但存在几个致命弱点,而RAG恰好是这些问题的解药:
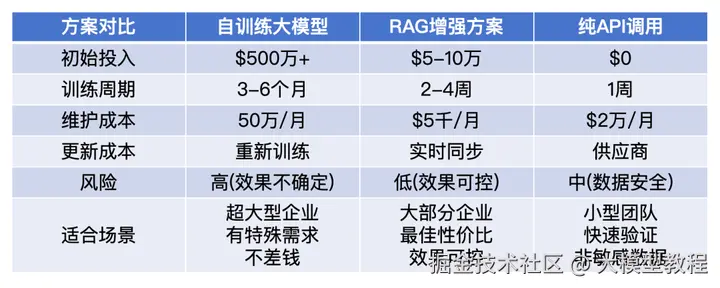
2.2 成本效益的最优解
很多企业的第一反应是"训练一个专属大模型",但算算账就会发现这是个天坑:
相比之下,RAG的成本优势明显:
添加图片注释,不超过 140 字(可选)
真实案例:他们最初计划投入2000万训练专属模型,用于技术文档问答。后来改用RAG方案,仅花费50万就达到了更好的效果,而且能够每天更新知识库,响应速度从原计划的6个月缩短到3周。
2.3 数据主权与合规安全
在数据就是石油的时代,企业最担心的是数据泄露和失去控制权。RAG架构完美解决了这个问题:
数据不出门:敏感数据保存在企业私有知识库中,只有检索结果参与模型推理,大大降低了数据泄露风险。某银行通过RAG实现了"数据不出行,智能服务到家"。
细粒度权限控制:不同员工可以访问不同级别的知识库,实现千人千面的智能服务。CEO看到的是战略分析,一线员工看到的是操作指南。
审计与追踪:每个回答都有明确的信息来源,满足金融、医疗等行业的强监管要求。某保险公司的RAG系统,每个理赔建议都能追溯到具体的条款和案例。
GDPR合规:用户有权要求删除个人数据,在RAG架构下,只需从知识库删除相关文档即可,无需重新训练模型。
2.4 灵活性与可扩展性
企业需求是动态变化的,RAG提供了无与伦比的灵活性:
即插即用:新的数据源可以随时接入,无需修改核心系统。某电商公司在双十一前临时接入了供应商库存系统,立即提升了客服的问题解决率。
多模态支持:不仅是文本,图片、表格、代码等多种格式都能被检索和理解。某汽车厂商的RAG系统能够理解技术图纸,工程师用自然语言就能查询复杂的装配流程。
增量学习:新知识的加入不会影响已有知识,避免了机器学习中的"灾难性遗忘"问题。
场景迁移:同一套RAG架构可以服务多个业务场景,只需切换知识库即可。某集团公司用一套系统同时支撑了HR问答、IT支持、财务咨询三个场景。
三 RAG工作原理深度剖析:从输入到输出的奇妙旅程
理解RAG的工作原理,就像理解一个精密的瑞士手表,每个组件都有其独特作用,配合起来才能准确报时。让我们跟随一个用户查询,看看RAG系统是如何一步步生成精准答案的。
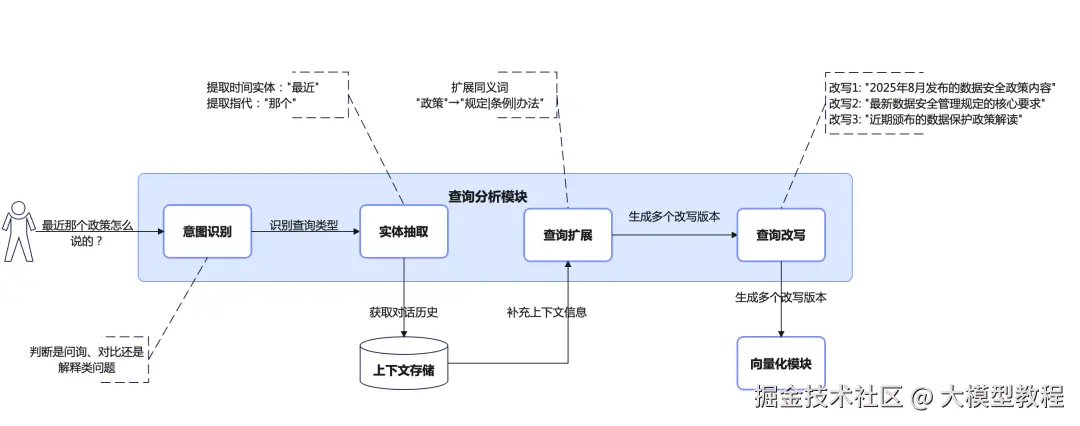
3.1 查询理解与预处理:让机器真正"听懂"你在问什么
用户的输入往往是模糊的、口语化的、甚至是有歧义的。比如用户问:"最近那个政策怎么说的?"系统需要理解:
"最近"是多久?一周?一个月?
"那个政策"指什么?根据上下文推断
"怎么说的"是要原文还是要解释?
RAG系统的第一步就是查询理解和改写:
添加图片注释,不超过 140 字(可选)
这个过程涉及多项NLP技术:
意图识别:判断用户是要查找事实(what)、寻求解释(why)、还是需要指导(how)。不同意图会触发不同的检索策略。某法律咨询系统通过意图识别,将"查条文"和"要案例"区分开,准确率提升了40%。
实体链接:识别并标准化查询中的实体。"小米手机"、"MI手机"、"米家手机"都会被链接到同一个实体ID,确保检索的完整性。
查询扩展:基于同义词、上下位词、相关词进行扩展。用户搜索"头疼",系统会自动扩展"头痛"、"偏头痛"、"头部疼痛"等变体。
时间理解:将"上个月"、"去年"、"最近"等相对时间转换为具体日期范围。某新闻检索系统通过时间归一化,将时效性检索的准确率提升了65%。
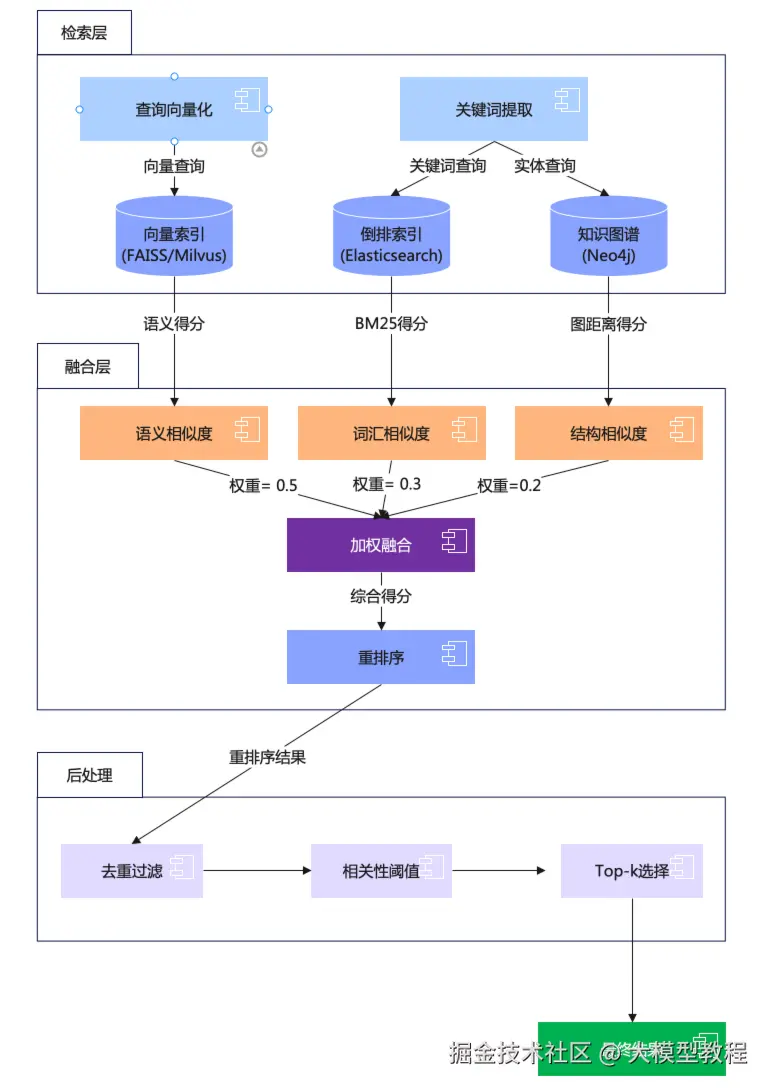
3.2 在知识海洋中精准捕鱼
检索不是简单的关键词匹配,而是语义理解和相关性计算的艺术。现代RAG系统采用混合检索策略,综合多种技术确保召回率和准确率:
向量检索(Dense Retrieval):将查询和文档都转换为高维向量,通过余弦相似度等度量找出语义相似的内容。即使用户说"水果手机",也能检索到"iPhone"相关内容。
关键词检索(Sparse Retrieval):基于BM25等算法,对精确匹配的关键词给予更高权重。在查找特定型号、法规条款时特别有效。
混合检索(Hybrid Retrieval):结合向量和关键词的优势,通过加权融合获得最佳效果。研究表明,混合检索比单一方法的性能提升25-30%。
添加图片注释,不超过 140 字(可选)
检索优化技巧:
3.3 上下文构建:给大模型配备最强"作战情报"
检索到相关文档后,如何组织这些信息供大模型使用,是RAG成功的关键。这不是简单的拼接,而是需要精心设计的上下文工程:
相关性排序:不是所有检索结果都同等重要。通过重排序模型(如Cross-Encoder),对检索结果进行精排,确保最相关的信息排在前面。
上下文窗口管理:大模型的上下文窗口有限(GPT-4是128K,Claude是200K),需要在有限空间内放入最有价值的信息。这就像打包行李,空间有限,每件物品都要精挑细选。
信息去重与合并:多个文档可能包含重复信息,需要智能去重。同时,互补的信息需要合并,形成完整的知识图景。
结构化组织:将散乱的信息组织成结构化格式,帮助模型理解。比如将产品信息整理成"特性-优势-案例"的结构。
# 上下文构建示例代码
def build_context(retrieved_docs, query, max_tokens=4000):
"""
构建优化的上下文
"""
# 1. 重排序
reranked_docs = rerank_model.sort(query, retrieved_docs)
# 2. 去重
unique_docs = remove_duplicates(reranked_docs)
# 3. 构建结构化上下文
context = {
"核心信息": extract_key_points(unique_docs[:3]),
"支撑细节": extract_details(unique_docs[3:6]),
"相关背景": extract_background(unique_docs[6:])
}
# 4. 压缩到窗口限制内
compressed = compress_to_limit(context, max_tokens)
# 5. 格式化为prompt
prompt = f"""
基于以下信息回答用户问题:
【核心信息】
{compressed['核心信息']}
【支撑细节】
{compressed['支撑细节']}
【相关背景】
{compressed['相关背景']}
用户问题:{query}
请基于上述信息,准确、完整地回答用户问题。
"""
return prompt
3.4 增强生成:让AI有理有据地"说话"
有了精心准备的上下文,接下来就是生成阶段。但这不是让模型自由发挥,而是通过精密的prompt工程,引导模型基于事实生成答案:
Prompt设计原则:
Chain-of-Thought推理:引导模型逐步思考,而不是直接给出答案。这特别适合复杂问题的推理:
第一步:识别问题的关键点是什么
第二步:从提供的信息中找出相关内容
第三步:分析这些信息之间的关系
第四步:综合得出结论
第五步:检查答案的逻辑性和完整性
多轮对话管理:RAG不是一次性的问答,而是支持连续对话。系统需要:
某客服系统通过多轮对话管理,将问题解决率从单轮的45%提升到多轮的78%。
四 RAG关键技术栈全景:构建企业级系统的必备组件
构建一个生产级的RAG系统,就像组装一台高性能赛车,每个组件都需要精挑细选,相互配合。让我们深入了解RAG技术栈的各个层次。
4.1 向量数据库:RAG的动力引擎
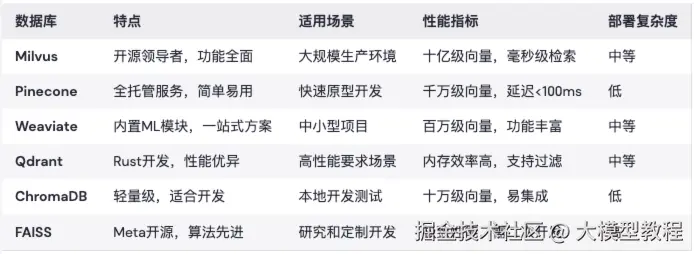
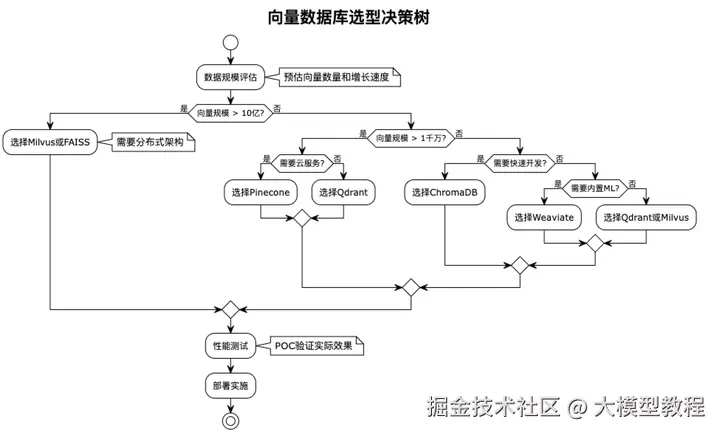
向量数据库是RAG系统的核心基础设施,负责存储和检索高维向量。选择合适的向量数据库,直接决定了系统的性能上限。
主流向量数据库对比:
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
向量索引算法深度解析:
不同的索引算法适合不同的场景,理解其原理有助于优化性能:
某社交媒体公司通过将索引从IVF-Flat升级到HNSW,在保持相同QPS的情况下,召回率从82%提升到96%,用户满意度显著提升。
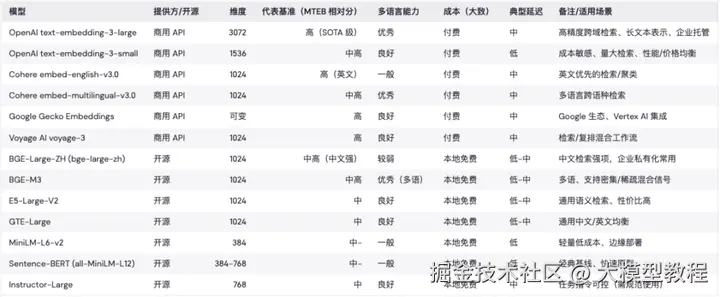
4.2 Embedding模型:将文本转化为"机器DNA"
Embedding模型负责将文本转换为向量表示,是RAG系统的"翻译官"。选择合适的Embedding模型,直接影响检索的准确性。
添加图片注释,不超过 140 字(可选)
Embedding优化技巧:
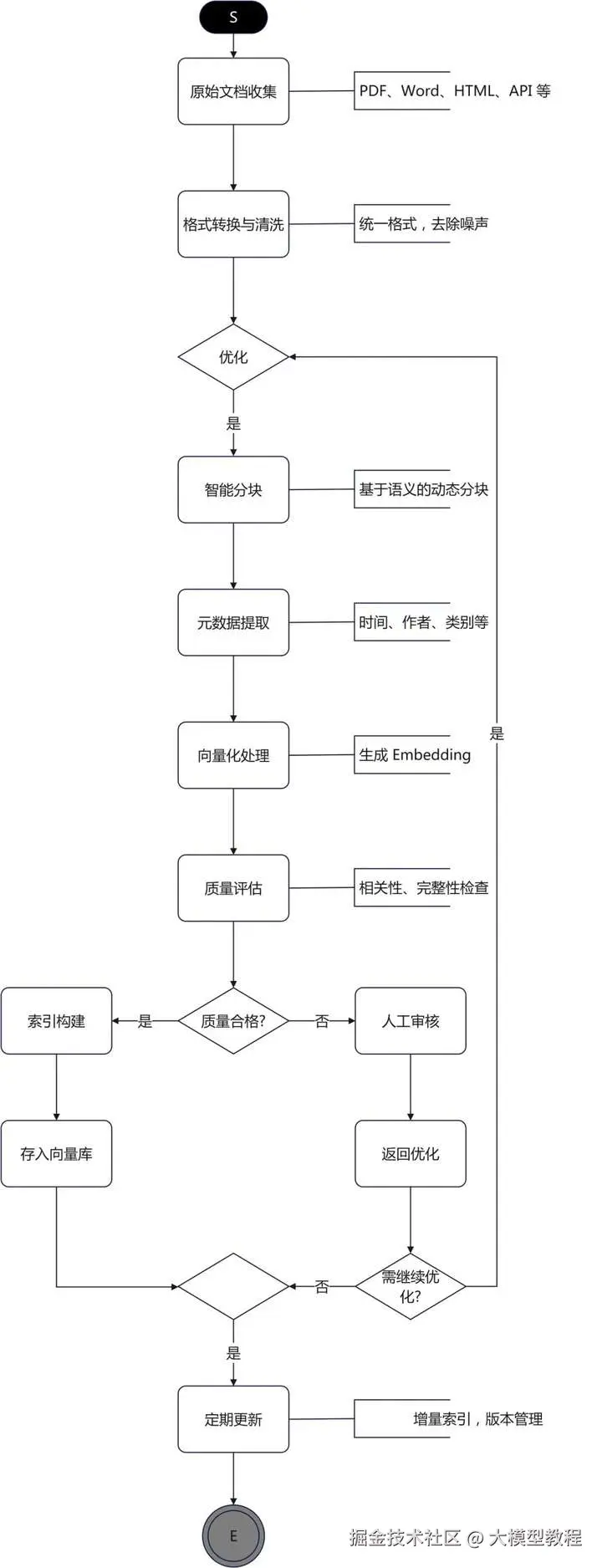
4.3 知识库构建:打造AI的"超级大脑"
知识库是RAG系统的根基,其质量直接决定了系统的上限。构建高质量知识库需要系统化的方法论:
文档处理Pipeline:
添加图片注释,不超过 140 字(可选)
智能分块策略:
分块(Chunking)是知识库构建的关键环节,需要在保持语义完整性和控制块大小之间找到平衡:
def semantic_chunking(text, max_tokens=512, overlap=50):
"""
基于语义的智能分块
"""
# 1. 句子分割
sentences = sent_tokenize(text)
# 2. 计算句子embedding
embeddings = model.encode(sentences)
# 3. 基于相似度聚类
chunks = []
current_chunk = []
current_tokens = 0
for i, sent in enumerate(sentences):
sent_tokens = len(tokenizer.encode(sent))
# 检查语义相似度
if i > 0:
similarity = cosine_similarity(
embeddings[i-1], embeddings[i]
)
# 低相似度表示主题转换
if similarity < 0.7or current_tokens + sent_tokens > max_tokens:
chunks.append(' '.join(current_chunk))
current_chunk = [sentences[max(0, i-2):i]] # 重叠
current_tokens = sum(len(tokenizer.encode(s)) for s in current_chunk)
current_chunk.append(sent)
current_tokens += sent_tokens
if current_chunk:
chunks.append(' '.join(current_chunk))
return chunks
知识库质量保障:
某金融机构通过实施严格的知识库质量管理,将错误信息率从8%降低到0.5%,客户投诉减少了90%。
4.4 评估与优化:让系统越来越聪明
RAG系统不是一次部署就完事,需要持续监控和优化。建立科学的评估体系是关键:
多维度评估指标体系:

添加图片注释,不超过 140 字(可选)
A/B测试框架:
classRAGExperiment:
"""
RAG系统A/B测试框架
"""
def __init__(self):
self.control_config = {
"embedding_model": "ada-002",
"chunk_size": 512,
"top_k": 5
}
self.treatment_config = {
"embedding_model": "bge-large",
"chunk_size": 768,
"top_k": 8
}
def run_experiment(self, queries, duration_days=7):
results = {
"control": [],
"treatment": []
}
for query in queries:
# 随机分配到实验组
group = random.choice(["control", "treatment"])
config = self.control_config if group == "control"else self.treatment_config
# 执行查询
response = self.execute_rag(query, config)
# 收集指标
metrics = {
"latency": response.latency,
"relevance": self.evaluate_relevance(response),
"user_rating": self.collect_user_feedback(response)
}
results[group].append(metrics)
# 统计分析
return self.analyze_results(results)
五RAG优化进阶:从及格到卓越的修炼之道
基础的RAG系统可以解决80%的问题,但要达到生产级的性能和可靠性,需要掌握高级优化技术。这一章节将分享业界最前沿的优化方法。
5.1 混合检索策略:1+1>2的协同效应
单一的检索方法都有其局限性,混合检索通过组合多种技术,实现优势互补:
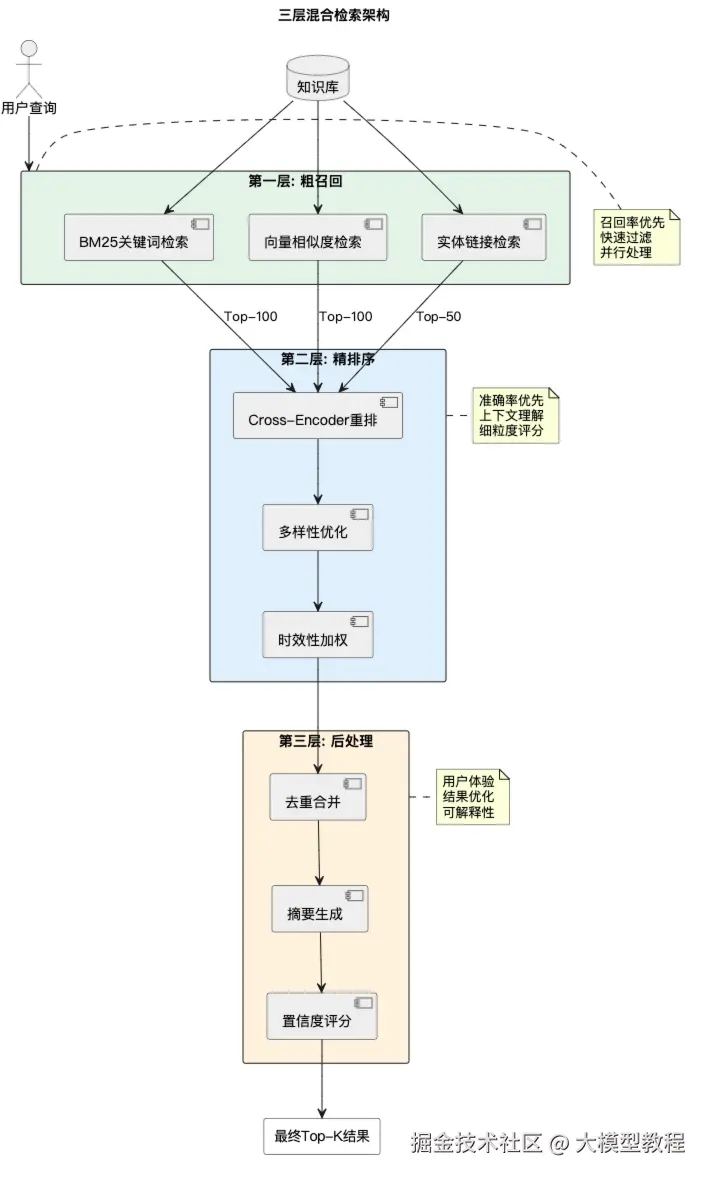
三层检索架构:
添加图片注释,不超过 140 字(可选)
融合策略对比实验:
# 不同融合策略的效果对比
fusion_strategies = {
"简单加权": {
"方法": "score = 0.5 * bm25_score + 0.5 * vector_score",
"MRR": 0.72,
"Recall@10": 0.68,
"优点": "简单直观",
"缺点": "权重固定"
},
"RRF (Reciprocal Rank Fusion)": {
"方法": "score = Σ(1/(k+rank_i))",
"MRR": 0.78,
"Recall@10": 0.74,
"优点": "无需调参",
"缺点": "忽略原始分数"
},
"学习排序 (LambdaMART)": {
"方法": "机器学习模型预测相关性",
"MRR": 0.85,
"Recall@10": 0.82,
"优点": "效果最好",
"缺点": "需要训练数据"
},
"自适应融合": {
"方法": "根据查询类型动态调整权重",
"MRR": 0.83,
"Recall@10": 0.80,
"优点": "灵活适应",
"缺点": "实现复杂"
}
}
查询类型自适应优化:
不同类型的查询需要不同的检索策略:
1、事实型查询("特斯拉的创始人是谁")
2、解释型查询("为什么会发生通货膨胀")
3、比较型查询("RAG和Fine-tuning的区别")
4、程序型查询("如何配置Redis集群")
5.2 查询改写与扩展:让AI更懂你
用户的查询往往不够精确,通过智能改写可以大幅提升检索效果:
多策略查询改写:
classQueryRewriter:
"""
多策略查询改写器
"""
def rewrite(self, query, context=None):
rewrites = []
# 1. 同义词扩展
synonyms = self.expand_synonyms(query)
rewrites.extend(synonyms)
# 2. 缩写展开
expanded = self.expand_abbreviations(query)
rewrites.append(expanded)
# 3. 错别字纠正
corrected = self.spell_correct(query)
if corrected != query:
rewrites.append(corrected)
# 4. 意图明确化
clarified = self.clarify_intent(query, context)
rewrites.append(clarified)
# 5. 实体识别与标准化
standardized = self.standardize_entities(query)
rewrites.append(standardized)
# 6. 基于LLM的改写
llm_rewrites = self.llm_rewrite(query, num_rewrites=3)
rewrites.extend(llm_rewrites)
# 去重和评分
unique_rewrites = list(set(rewrites))
scored_rewrites = self.score_rewrites(query, unique_rewrites)
return scored_rewrites[:5] # 返回Top-5改写
def llm_rewrite(self, query, num_rewrites=3):
"""
使用LLM生成查询改写
"""
prompt = f"""
请将以下查询改写成{num_rewrites}个不同的版本,保持语义不变:
原始查询:{query}
要求:
1. 使用不同的表达方式
2. 补充可能的隐含信息
3. 使用更专业的术语
改写版本:
"""
response = llm.generate(prompt)
return parse_rewrites(response)
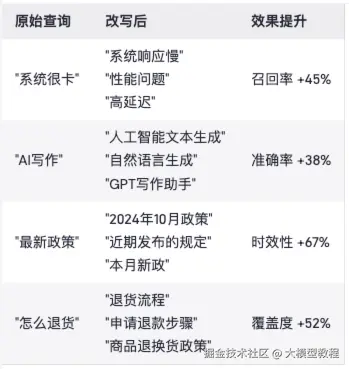
查询改写效果案例:
添加图片注释,不超过 140 字(可选)
5.3 动态知识更新:让知识库保持最新
静态的知识库会快速过时,动态更新机制是RAG系统的生命线:
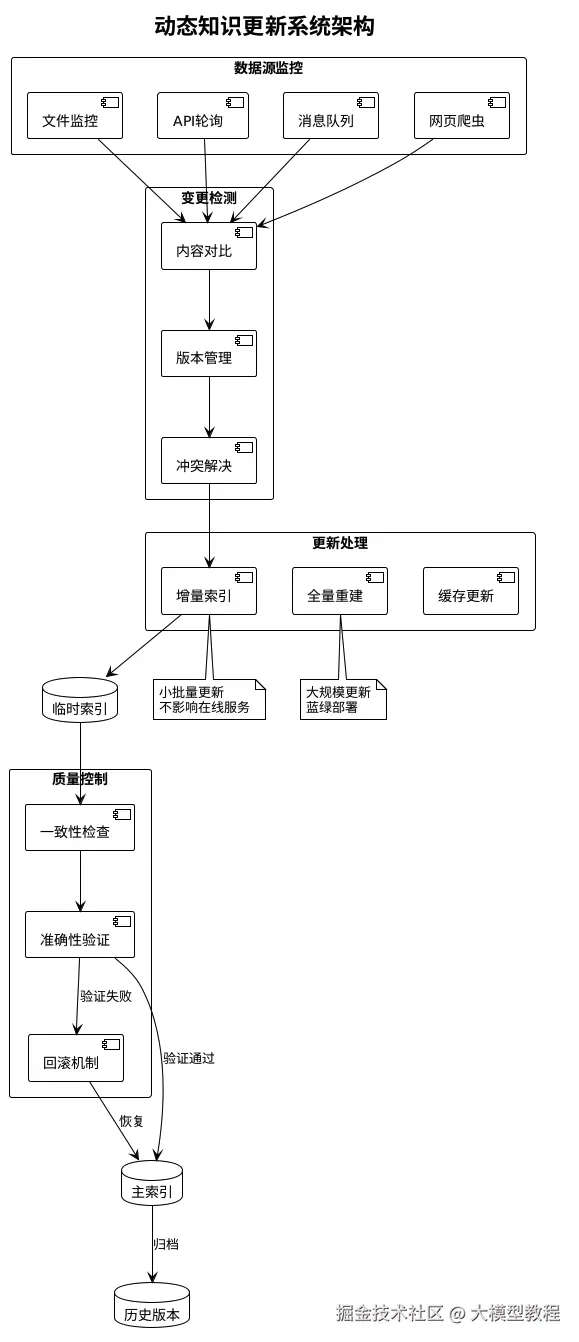
增量索引架构:
添加图片注释,不超过 140 字(可选)
更新策略最佳实践:
1、优先级队列:不同类型的更新有不同优先级
2、版本控制:保留历史版本,支持回滚
classVersionedDocument:
def __init__(self, doc_id):
self.doc_id = doc_id
self.versions = []
self.current_version = None
def update(self, content, metadata):
new_version = {
"version": len(self.versions) + 1,
"content": content,
"metadata": metadata,
"timestamp": datetime.now(),
"hash": calculate_hash(content)
}
# 检测是否真的有变化
if self.current_version and
new_version["hash"] == self.current_version["hash"]:
return False # 内容未变化
self.versions.append(new_version)
self.current_version = new_version
return True
def rollback(self, version_num):
if version_num <= len(self.versions):
self.current_version = self.versions[version_num - 1]
return True
return False
3、蓝绿部署:无缝切换索引版本
5.4 性能优化:让系统飞起来
当RAG系统面对高并发、大规模数据时,性能优化变得至关重要:
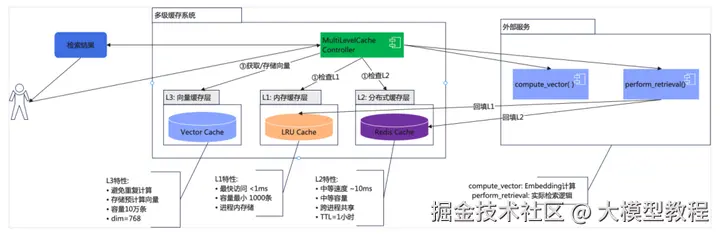
多级缓存架构:
添加图片注释,不超过 140 字(可选)
性能优化技巧:
1、批处理:将多个查询合并处理
2、异步处理:利用异步IO提升并发能力
3、向量量化:减少内存占用和计算量
4、索引优化:
总结
RAG技术的出现,不仅解决了大模型的固有缺陷,更为企业级AI应用开辟了一条可行的道路。从金融合规到医疗诊断,从智能制造到教育培训,RAG正在各个领域展现其变革力量。
对于正在考虑采用RAG的企业,我的建议是:
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
三星 Galaxy M07 手机发布:联发科 G99、提供 6 年安全更新,6999 印度卢比
小米 SU7 / YU7 汽车 10 月限时购车权益出炉,含辅助驾驶终身免费使用权

