欧易OTC专业交易所
280.71MB · 2025-09-17

在传统机器学习中,准确率、精确率和F1分数等指标是基石。它们在有有限正确答案的任务中表现出色。然而,对于生成式AI和智能体系统而言,输出空间极为广阔,简单地将输出与单一**“正确”**答案进行字符串匹配已不再足够。
如果没有明确的评估方法,改进大语言模型(LLM)系统往往只能靠猜测。
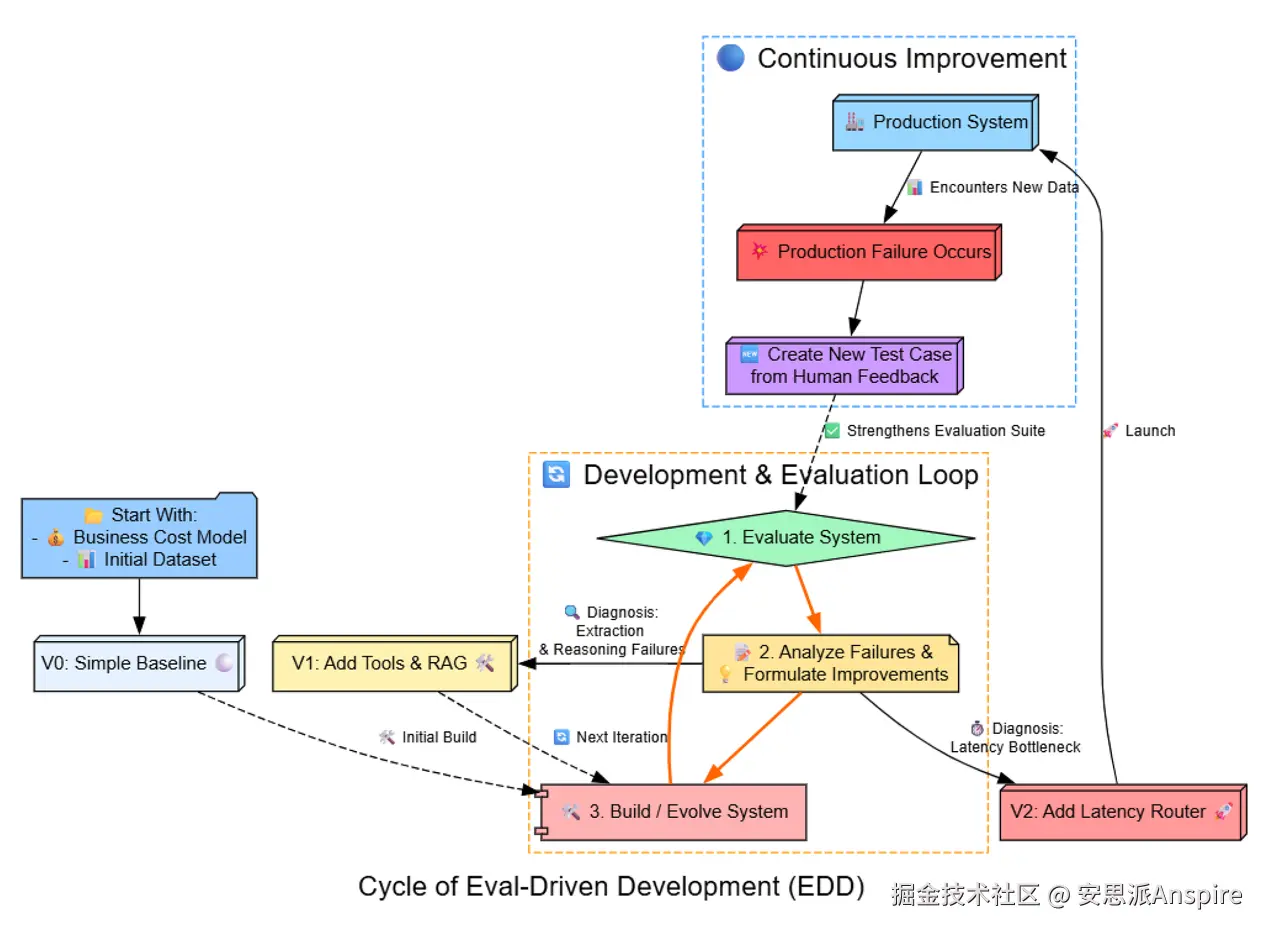
EDD方法评估驱动系统
这就是我们所说的 “试错工程”:微调提示词,观察一些输出,然后主观判断它是否更好。这种方法速度慢、不可靠,而且无法量化进展或防止倒退。
**评估驱动开发(EDD)**是一种更好的构建方式。它不是仅仅检查输出是否正确,而是使用一组可重复的测试来衡量诸如质量、速度、成本和一致性等方面,从而将更多科学步骤引入到这个过程中。
EDD是一个富有成效的周期,在这个周期中我们……
**测试:**使用全面的评估套件对当前系统进行测试。
**分析:**深入研究结果,以确定具体的故障模式。
**改进:**提出假设并实施有针对性的改进。
**重复:**重新运行评估,以确认你的假设并找出下一个瓶颈。
在本指南中,我将使用**评估驱动开发(EDD)**方法,创建一个构建多组件、使用工具的智能体的完整生命周期。我们将从一个简单的基线开始,使用一套精密的评估套件来指导每一个架构决策,将我们的系统从一个脆弱的原型逐步演变为一个健壮的、可投入生产的智能体。
以这一理念为指导,让我们搭建好环境并选择合适的工具来开展工作。首先,让我们安装好所需的依赖项。
%pip install --upgrade openai pydantic pandas scikit-learn python-dotenv rich -qqq
接下来,我们将设置客户端。对于这个项目,我使用Nebius AI来访问一系列强大的开源模型,但代码的结构设计使其能够与任何兼容OpenAI的API一起工作,包括本地Ollama实例。
import os # 用于环境变量和文件路径
import json # 用于处理JSON数据
import asyncio # 用于异步事件循环和async/await支持
from pathlib import Path # 用于处理文件系统路径
from typing import List, Optional # 用于类型提示(列表、可选类型)
import pandas as pd # 用于数据分析/表格数据
from openai import AsyncOpenAI # Nebius/OpenAI异步客户端
从 pydantic 导入 BaseModel, Field # 用于数据验证 / 模型
从 rich 导入 打印 # 用于丰富的终端输出(颜色、样式)
从 dotenv 导入 load_dotenv # 用于加载.env 环境变量
# 从.env 文件加载环境变量。
# 创建一个名为.env 的文件,并像这样添加你的 API 密钥:
# NEBIUS_API_KEY="your_api_key_here"
load_dotenv()
# 从环境变量中获取 API 密钥
api_key = os.environ.get("NEBIUS_API_KEY")
# 配置客户端指向 Nebius AI API 端点。
# 所有后续的 API 调用都将通过这个自定义的基础 URL 进行路由。
client = AsyncOpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=api_key
)
如果你是一名开发者,你会很容易理解这段代码,它只是通过 API 调用和初始化大语言模型(LLM),你也可以将其适配到类似 Ollama 的工具上。唯一的区别是我使用了AsyncOpenAI,因为它有助于处理异步任务和非阻塞请求。
目前我们战略的一个关键部分是针对不同任务使用不同的模型。强大而昂贵的模型对于简单任务来说是大材小用,而小模型可能缺乏处理复杂任务的推理能力。因此,我们将针对两个关键角色做出有原则的选择:
基线 / 简单任务(V0系统): Llama-3.1-8B这是一个现代的、功能强大的小型模型。它极具成本效益且速度快,非常适合作为我们的首版系统。它将作为我们的gpt-4o-mini等效模型。
高级/评分任务(V1系统和评估): Qwen/Qwen3-235B-A22B-Instruct-2507,这是目前可用的性能最高的开源模型之一。其大尺寸以及对推理、数学和结构化JSON输出的明确支持,使其成为我们高级V1代理的理想选择,更重要的是,也适合作为我们基于模型的评分器。一个强大、公正的评判者对于高质量的评估至关重要。它将作为我们的gpt-4o等效模型。
在完成环境配置和模型选择后,我们现在可以定义我们旨在解决的具体业务问题了。
有了我们的理念和环境,现在我们可以进入任何成功的AI项目的第一步,即深入理解并量化我们试图解决的业务问题。
**现在让我们来了解一下我们的场景:**一家公司每月要处理数千张员工费用报销单。人工审核流程缓慢、成本高且容易出现人为错误。我们的任务是构建一个AI智能体,自动执行这个工作流程,仅智能标记出需要最终人工审核的必要报销单。
我们确实知道,真正的企业需要的不仅仅是准确性,一个可投入生产的系统必须从多个因素进行评估……
**正确性:**我们必须将遗漏的不合规收据(假阴性)和错误标记的有效收据(假阳性)都降至最低。
成本效益: AI系统的总成本,包括其运营费用和任何错误成本,必须显著低于当前的人工流程。
**速度:**系统必须足够快,以避免延误员工报销。
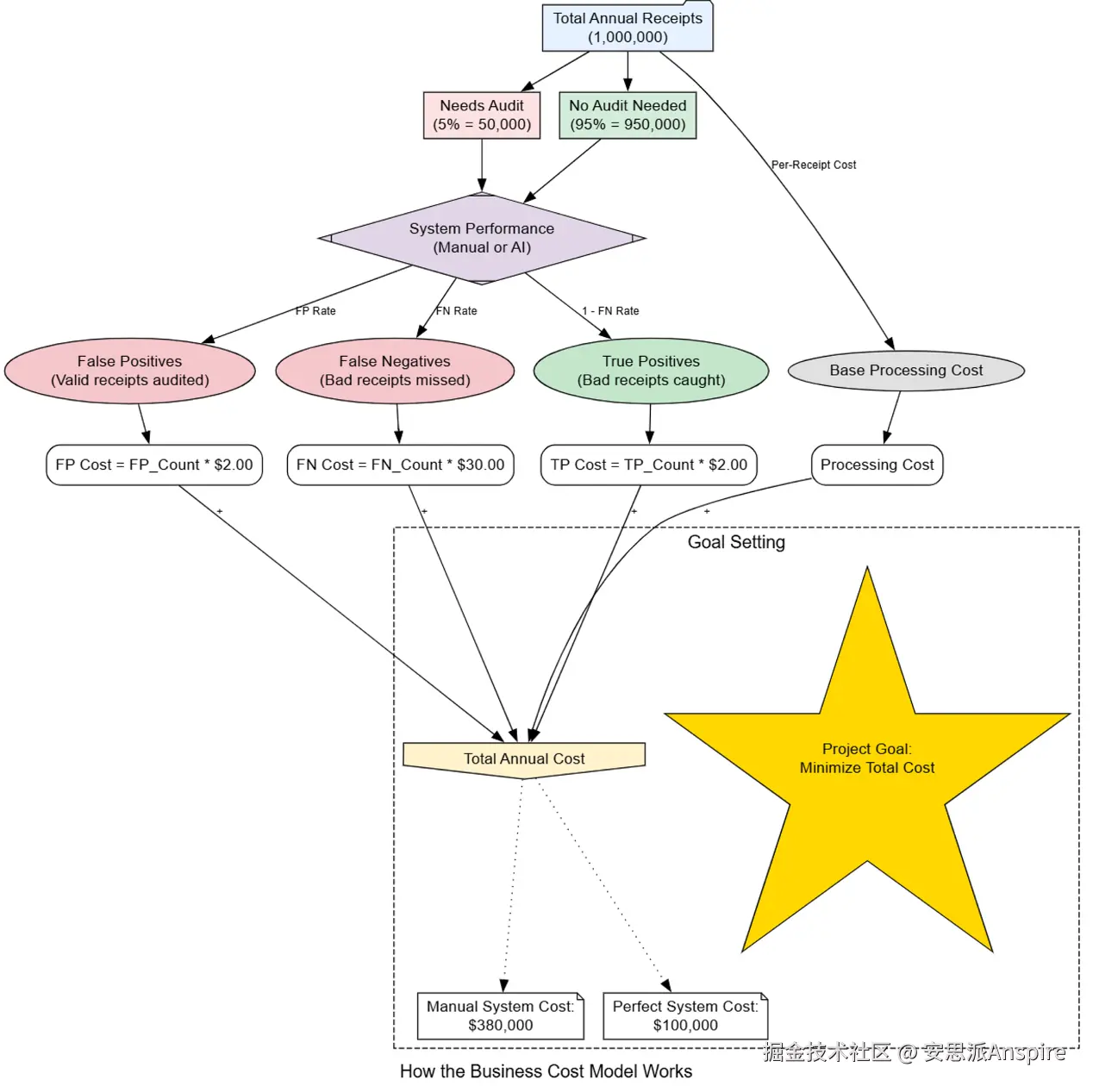
商业模式流程
为了就我们的智能体架构做出理性的、基于数据的决策,我们必须首先构建一个业务成本模型。
在编码之前,我们会衡量业务影响。该模型将性能(误报和漏报)转化为货币价值,为我们指明了清晰的方向。
我们的假设:
每年收据数量:1,000,000
每张收据的人工审核成本:2.00美元
遗漏不合规收据(假阴性)造成的平均损失:30.00美元
真正需要审计的收据百分比:5%
当前人工流程的成本(每张收据,审计成本之前):0.20美元
我们的AI系统成本(每张收据):我们稍后将根据令牌使用情况进行估算。
让我们将这些假设转化为一个Python函数,该函数可以计算任何给定系统的年度总成本,无论是我们当前的人工系统还是未来的AI智能体。
def calculate_business_cost(
fp_rate: float,
fn_rate: float,
per_receipt_processing_cost: float,
receipt_count: int = 1_000_000,
audit_fraction: float = 0.05,
human_audit_cost: float = 2.0,
missed_audit_loss: float = 30.0
) -> float:
"""对费用审计系统的年度总成本进行建模。"""
needs_audit_count = receipt_count * audit_fraction
no_audit_needed_count = receipt_count * (1 - audit_fraction)
#误报成本:被发送给人工审核的有效收据
误报数量 = 无需审核的数量 * 误报率
误报成本 = 误报数量 * 人工审核成本
#漏报成本:被遗漏的不良收据
漏报数量 = 需要审核的数量 * 漏报率
漏报成本 = 漏报数量 * 遗漏审核损失
#真阳性成本:正确识别的审核
真阳性数量 = 需要审核的数量 * (1 - 漏报率)
真阳性成本 = 真阳性数量 * 人工审核成本
# AI系统或人工处理的总处理成本
processing_cost = receipt_count * per_receipt_processing_cost
total_cost = fp_cost + fn_cost + tp_cost + processing_cost
return total_cost
# 基线:我们当前的人工驱动流程(假设FP为2%,FN为3%)
current_system_cost = calculate_business_cost(fp_rate=0.02, fn_rate=0.03, per_receipt_processing_cost=0.20)
perfect_system_cost = calculate_business_cost(fp_rate=0, fn_rate=0, per_receipt_processing_cost=0)
print(f"当前人工系统成本: ${current_system_cost:,.2f}")print(f"理论上完美系统的成本: ${perfect_system_cost:,.2f}")
这个calculate_business_cost函数是我们业务案例的核心。它将总成本分解为其关键组成部分:错误决策的成本(误报和漏报)、正确决策的成本(审核真阳性)以及基线处理成本。
通过运行这个模型,我们可以确立两个最重要的基准:
我们当前流程的成本……
以及理论最低成本。
当前人工系统的成本:100,000.00
这个输出立即为我们提供了一个明确且有说服力的目标。
一个理论上完美的系统,即一个不会出错且处理成本为零的系统,每年仍需花费100,000美元,因为5%的收据确实需要审计,而且仍需为此付费。
我们现在的目标是构建一个尽可能接近这个100,000美元基线的AI系统,同时保持其自身的处理成本较低。这个财务框架将使我们能够客观地衡量我们所做的每一项改进的价值。
在确定并量化了我们的任务范围后,我们现在需要数据来训练和测试我们的智能体。让我们来准备这些数据。
对于这个项目,为确保我们的工作流程完全自包含且可复现,我们将通过编程方式创建一个小型、高质量的模拟数据集。
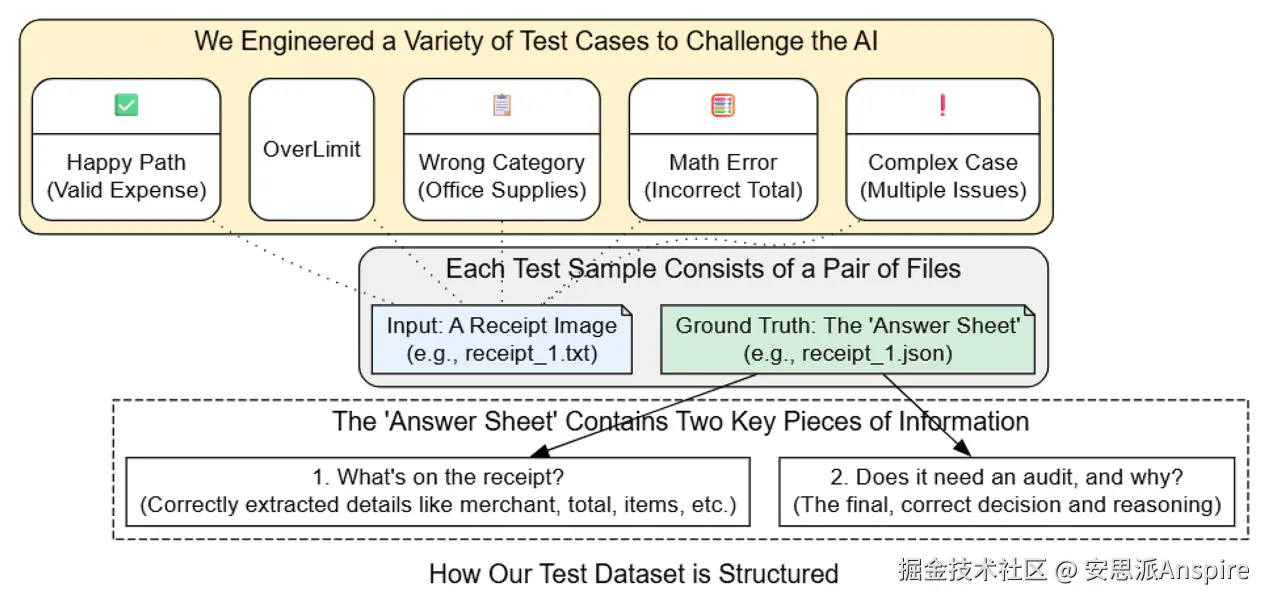
我们的真实世界模拟数据
在现实场景中,这一步骤将涉及收集数千张真实的收据图像,并让领域专家(如会计师)对其进行细致标注,以创建我们的地面实况。
我们的数据集将被设计用于测试我们的智能体应对各种常见挑战的能力。首先,我们需要定义从收据中提取的信息以及最终审计决策的数据结构。
我们将使用Pydantic来实现这一点。Pydantic模式不仅仅是数据容器,它们本质上是一种契约。它们提供了一种自文档化且类型安全的结构,我们可以用它来约束大语言模型(LLM)的输出,这是一种构建可靠系统的技术。
让我们从定义数据结构中最小、最基本的部分开始:收据上的位置和单个行项目。
class Location(BaseModel):
# 可选字段允许模型在收据上没有相关信息时返回 None。
city: Optional[str] = None
state: Optional[str] = None
class LineItem(BaseModel):
description: str
quantity: float
price: float # 每件商品的价格
total: float
在这里,我们创建了两个简单的类。Location类很简单,但请注意,我们将其字段设为可选。这是一个实际的考虑,因为并非所有收据都有城市或州信息,这告诉我们的系统(以及大语言模型),这些信息缺失是可以接受的。LineItem类捕获单个购买商品的基本细节。
现在,我们可以将这些构建块组合成一个更大的结构,该结构代表一张完整的收据。
class ReceiptDetails(BaseModel):
merchant: str
location: Location
items: List[LineItem]
subtotal: Optional[float] = None
tax: float
total: float
handwritten_notes: List[str] = []
我们的ReceiptDetails模型将所有内容整合在一起。它包含商家名称、嵌套的Location对象,以及LineItem对象的列表。这种层次结构是呈现真实收据上复杂数据的简洁方式。
最后,我们为我们的代理最重要的输出——最终审计决策——定义了模式。
class AuditDecision(BaseModel):
# 我们使用 Field(description=...) 为大语言模型(LLM)提供每个布尔标志含义的额外上下文。
# 这在数据模式中直接起到了提示工程的作用。
not_travel_related: bool = Field(description="如果收据不是用于旅行(例如办公用品),则为 True")
amount_over_limit: bool = Field(description="如果总金额超过 75 美元,则为 True")
math_error:bool=字段(描述="如果行项目+税金不与总数相加,则为真")
handwritten_x:bool=字段(描述="如果手写笔记中有'X',则为真,表示项目无效")
推理:str
needs_audit:布尔
这个 AuditDecision 类是我们将业务逻辑直接嵌入到模式中的地方。 Field (description=...) 是一种强大的技术。这个描述不仅仅是给我们开发者的注释,它作为工具模式的一部分传递给大语言模型(LLM),为其提供每个布尔标志代表什么的明确指示。这显著提高了最终结构化输出的可靠性。
在定义好数据模式后,我们现在可以创建一个函数来生成并保存模拟数据。这个函数将创建文本文件来模拟我们的收据“图像”,并创建对应的JSON文件来存储地面实况标签。
# --- 创建模拟数据的函数 ---
def setup_mock_dataset():
"""生成一个小型的本地数据集,用于演示目的。"""
data_dir = Path("temp_data")
img_dir = data_dir / "images"
gt_dir = data_dir / "ground_truth"
img_dir.mkdir(parents=True, exist_ok=True)
gt_dir.mkdir(parents=True, exist_ok=True)
# 这个字典定义了我们的测试用例,涵盖了各种场景。
mock_data = {
"receipt_1": { # 简单、有效的差旅费
"image_content": "壳牌加油站n休斯顿燃料路123号,TXn无铅汽油:10加仑,每加仑3.50美元 = 35.00美元n税费:2.80美元n总计:37.80美元",
"ground_truth": {
"details": ReceiptDetails(merchant="Shell", location=Location(city="Houston", state="TX"), items=[LineItem(description="Unleaded Gasoline", quantity=10, price=3.5, total=35.0)], tax=2.8, total=37.8).model_dump(),
"audit": AuditDecision(not_travel_related=False, amount_over_limit=False, math_error=False, handwritten_x=False, reasoning="Standard travel expenses are within the limit.", needs_audit=False).model_dump()
}
},
"receipt_2": { # Over limit
"image_content": "豪华酒店n纽约市公园大道456号n客房服务:1份,85美元 = 85美元n税费:7.5美元n总计:92.5美元",
"ground_truth": {
"details": ReceiptDetails(merchant="豪华酒店", location=Location(city="纽约", state="NY"), items=[LineItem(description="客房服务", quantity=1, price=85.0, total=85.0)], tax=7.5, total=92.5).model_dump(),
"audit": AuditDecision(not_travel_related=False, amount_over_limit=True, math_error=False, handwritten_x=False, reasoning="总金额超过75美元的限额。", needs_audit=True).model_dump()
}
},
"receipt_3": { # 非旅行相关
"image_content": "办公用品公司n芝加哥市办公桌大道789号,ILn打印纸:2份 @ 15.00美元 = 30.00美元n税:2.40美元n总计:32.40美元",
"ground_truth": {
"details": ReceiptDetails(商家="办公用品公司", 地点=Location(城市="芝加哥", 州="IL"), 商品=[LineItem(描述="打印纸", 数量=2, 单价=15.0, 总价=30.0)], 税=2.4, 总价=32.4).model_dump(),
"audit": AuditDecision(not_travel_related=True, amount_over_limit=False, math_error=False, handwritten_x=False, reasoning="办公用品不属于与差旅相关的费用。", needs_audit=True).model_dump()
}
},
"receipt_4": { # 数学错误
"image_content": "Corner Cafen101 Error Ln, San Francisco, CAn三明治: 1 @ $10.00 = $10.00n咖啡: 1 @ $4.00 = $4.00n税: $1.00n总计: $16.00 <--- 应该是 $15.00",
"ground_truth": {
"详情": 收据详情(商家="街角咖啡馆", 位置=地点(城市="旧金山", 州="CA"), 商品=[商品项目(描述="三明治", 数量=1, 价格=10.0, 总价=10.0), 商品项目(描述="咖啡", 数量=1, 价格=4.0, 总价=4.0)], 小计=14.0, 税=1.0, 总价=16.0).model_dump(),
"audit": AuditDecision(not_travel_related=False, amount_over_limit=False, math_error=True, handwritten_x=False, reasoning="小计 ($14) + 税 ($1) 不等于总计 ($16)。", needs_audit=True).model_dump()
}
},
"receipt_5": { # 手写备注且与差旅无关
"image_content": "五金店n202工具街,奥斯汀,TXn锤子:1个 @ 20.00美元 = 20.00美元n税:1.60美元n总计:21.60美元nn手写备注:n- 用于办公室维修n- X 请勿使用此笔",
"ground_truth": {
"详情": 收据详情(商家="五金店", 位置=地点(城市="奥斯汀", 州="TX"), 商品=[商品项目(描述="锤子", 数量=1, 价格=20.0, 总价=20.0)], 税=1.6, 总价=21.6, 手写备注=["用于办公室维修", "X 请勿使用此张"]).model_dump(),
"audit": AuditDecision(not_travel_related=True, amount_over_limit=False, math_error=False, handwritten_x=True, reasoning="与差旅无关且包含作废 'X' 标记。", needs_audit=True).model_dump()
}
}
}
print(f"模拟数据集创建于:{data_dir}")
for name, data in mock_data.items():
# 在本笔记本中,我们使用纯文本文件模拟图像。
img_path = img_dir / f"{name}.txt"
gt_path = gt_dir / f"{name}.json"
img_path.write_text(data["image_content"])
gt_path.write_text(json.dumps(data["ground_truth"], indent=2))
print(f" - {img_path}")
print(f" - {gt_path}")
return data_dir
# 创建数据集到磁盘,供我们的笔记本使用。
DATA_DIR = setup_mock_dataset()
IMAGE_DIR = DATA_DIR / "images"
GROUND_TRUTH_DIR = DATA_DIR / "ground_truth"
setup_mock_dataset函数是我们数据准备的引擎。mock_data字典是我们精心设计测试用例的地方。每个键(receipt_1,receipt_2等)代表一个独特的场景,旨在测试特定的审计规则:
receipt_1是我们的“理想情况”,即一笔干净、合规的费用。
receipt_2测试“金额超限”规则。
receipt_3测试“非旅行相关”规则。
receipt_4测试是否存在明显的数学错误。
receipt_5是我们复杂的边缘案例,它结合了多个失败点(不符合规定和手写的无效标记)。
这种多样性对于构建有意义的评估至关重要。一个仅在理想情况下有效的系统还未准备好投入生产。
######## 上述代码的输出 ##########
模拟数据集创建于:temp_data
- temp_data/images/receipt_1.txt
- temp_data/ground_truth/receipt_1.json
- temp_data/images/receipt_2.txt
- temp_data/ground_truth/receipt_2.json
- temp_data/images/receipt_3.txt
- temp_data/ground_truth/receipt_3.json
- temp_data/images/receipt_4.txt
- temp_data/ground_truth/receipt_4.json
- temp_data/images/receipt_5.txt
- temp_data/ground_truth/receipt_5.json
输出结果证实,我们的测试数据已成功创建并保存到磁盘。现在我们有了 “图像”(.txt 文件,包含原始收据文本)和专家标注的答案(.json 文件,包含地面实况ReceiptDetails 和AuditDecision)。
既然我们的业务问题已经量化,数据集也已准备好,现在我们可以构建并评估我们的第一个系统,我们可以称之为V0基线。
280.71MB · 2025-09-17
283.16MB · 2025-09-16
286.59MB · 2025-09-16

