

天诺思手环(天天手环)
35.97MB · 2025-11-09

AI 驱动的视频和音频内容创作正迎来爆发式增长,中国科技巨头阿里巴巴和腾讯的最新开源模型,正共同定义这一领域的全新范式。
阿里巴巴已开源其 14B 音频驱动视频模型 Wan2.2-S2V,标志着 AI 视频生成领域的又一个“通义时刻”。
这款模型仅需一张图片和一段音频,便能生成具有自然面部表情、口型高度一致且动作流畅的电影级数字人视频。
它的核心亮点在于:
Wan2.2-S2V 基于通义万相视频生成基础模型,通过超过 60 万个音视频片段的混合并行训练构建。
它巧妙融合了文本引导的全局运动控制和音频驱动的细粒度局部运动,并引入 AdaIN+CrossAttention 机制确保音画同步。
为实现长视频生成,模型采用层次化帧压缩技术,将历史参考帧长度扩展至 73 帧,同时支持多分辨率训练和推理以适应不同视频场景。
该模型的发布,无疑让阿里巴巴通义的视频生成“全家桶”更为完善,其模型家族在开源社区和第三方平台下载量已超 2000 万,进一步巩固了其在 AI 视频生成领域的领先地位。
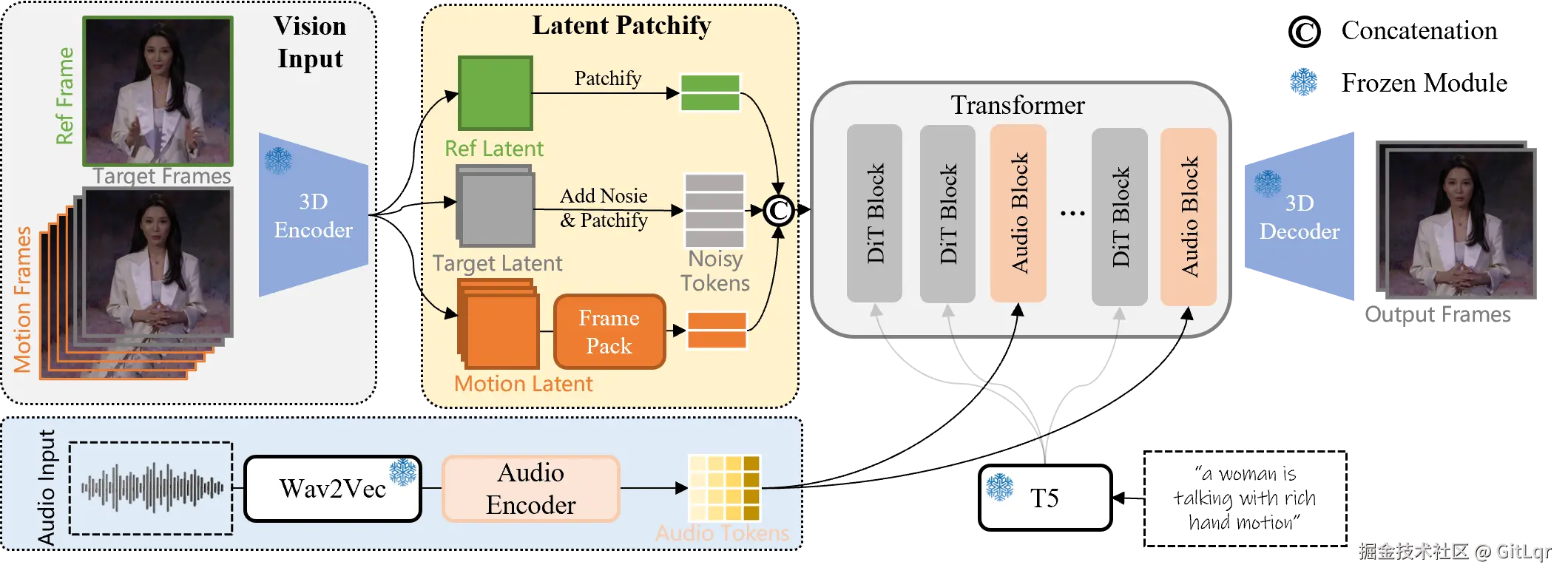
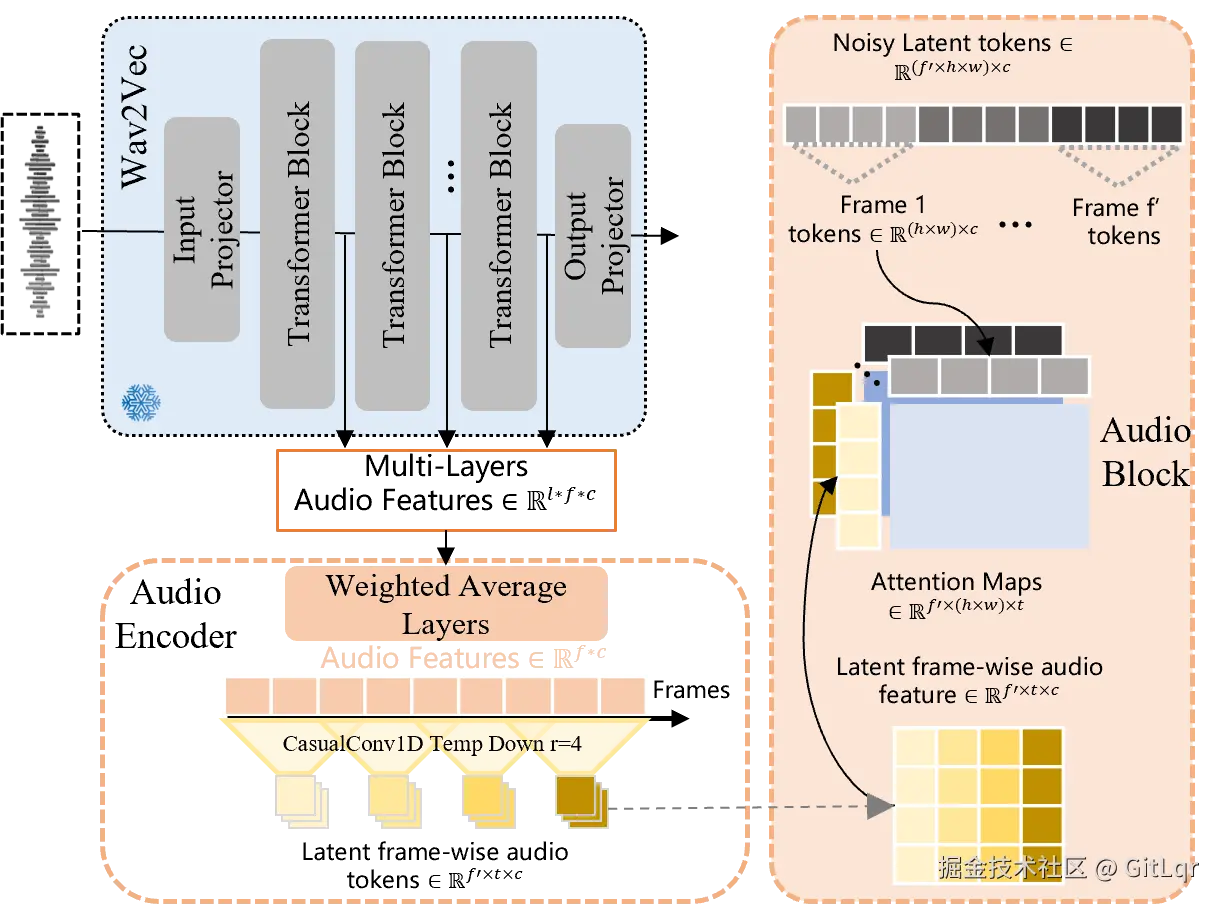
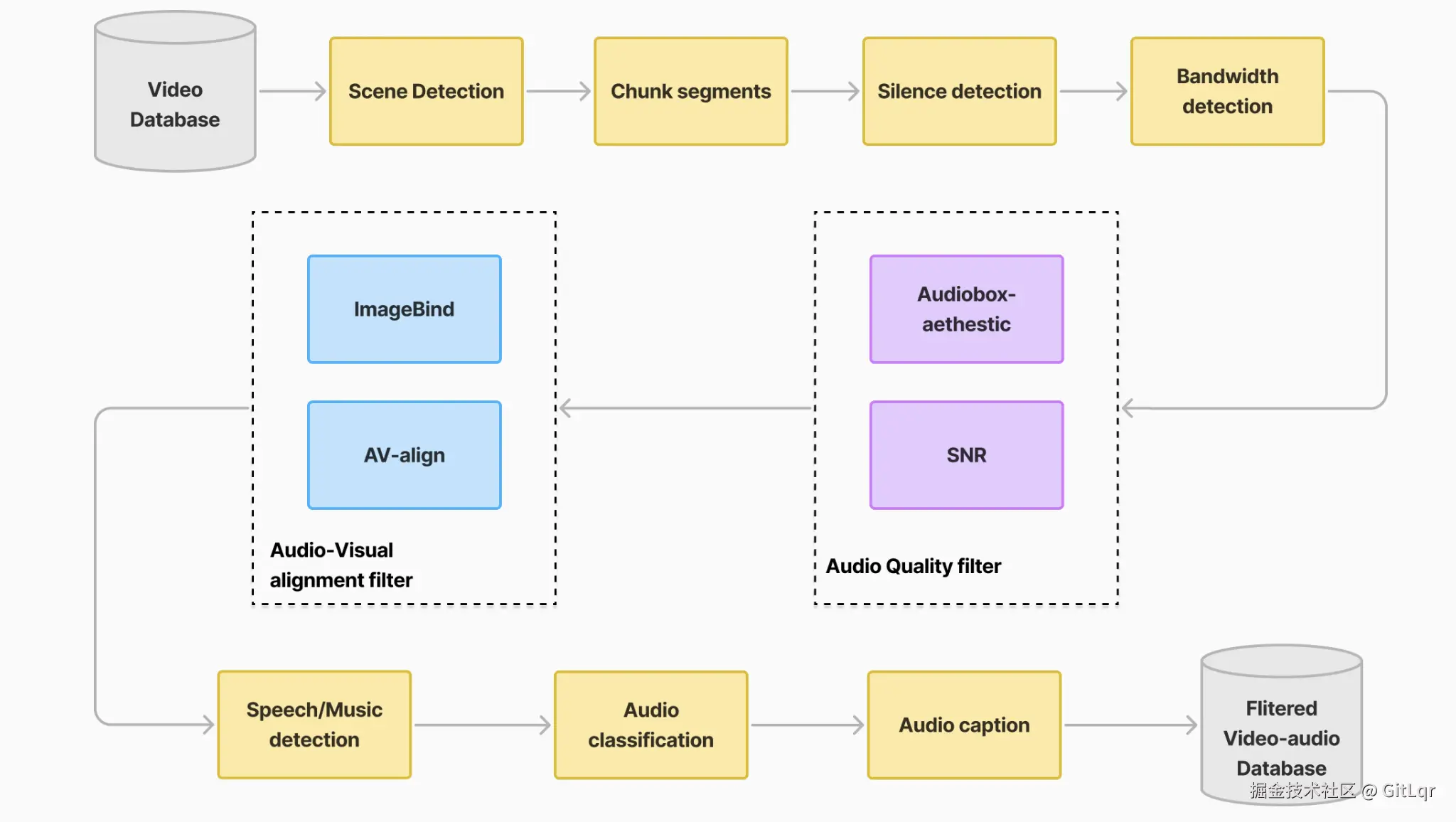
在 AI 视频生成领域,一个长期存在的痛点是“有画面无声音”。腾讯混元开源的端到端视频音效生成模型 HunyuanVideo-Foley,正是为此而来。该模型能通过输入视频和文本,为视频自动匹配电影级音效,彻底打破了这一壁垒。
HunyuanVideo-Foley 解决了现有音频生成技术的三大难题:
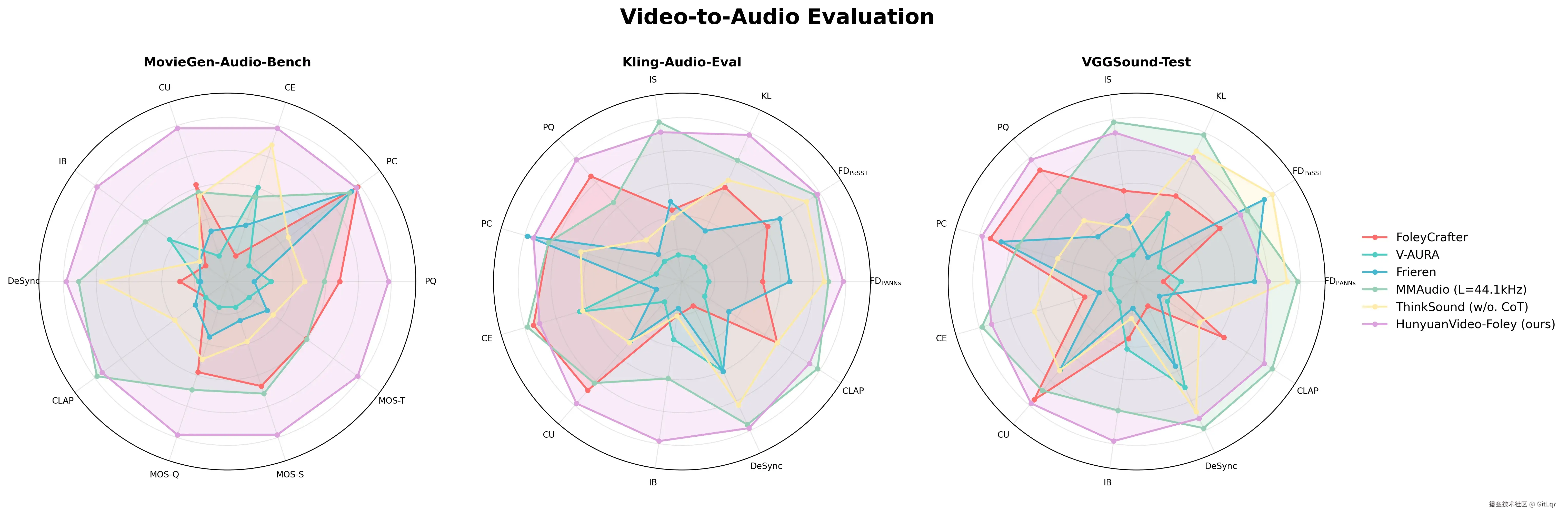
HunyuanVideo-Foley 在多项权威评测基准上均达到了新的 SOTA 水平,其音频质量、视觉语义对齐和时序对齐指标均表现出色,并在主观评测中获得接近专业水准的高分。
该模型的开源为多模态 AI 在内容创作领域的应用提供了可复用的技术范式,将极大赋能短视频创作者、电影制作团队和游戏开发者,帮助他们高效生成场景化音效、完成环境音设计和构建沉浸式听觉体验。
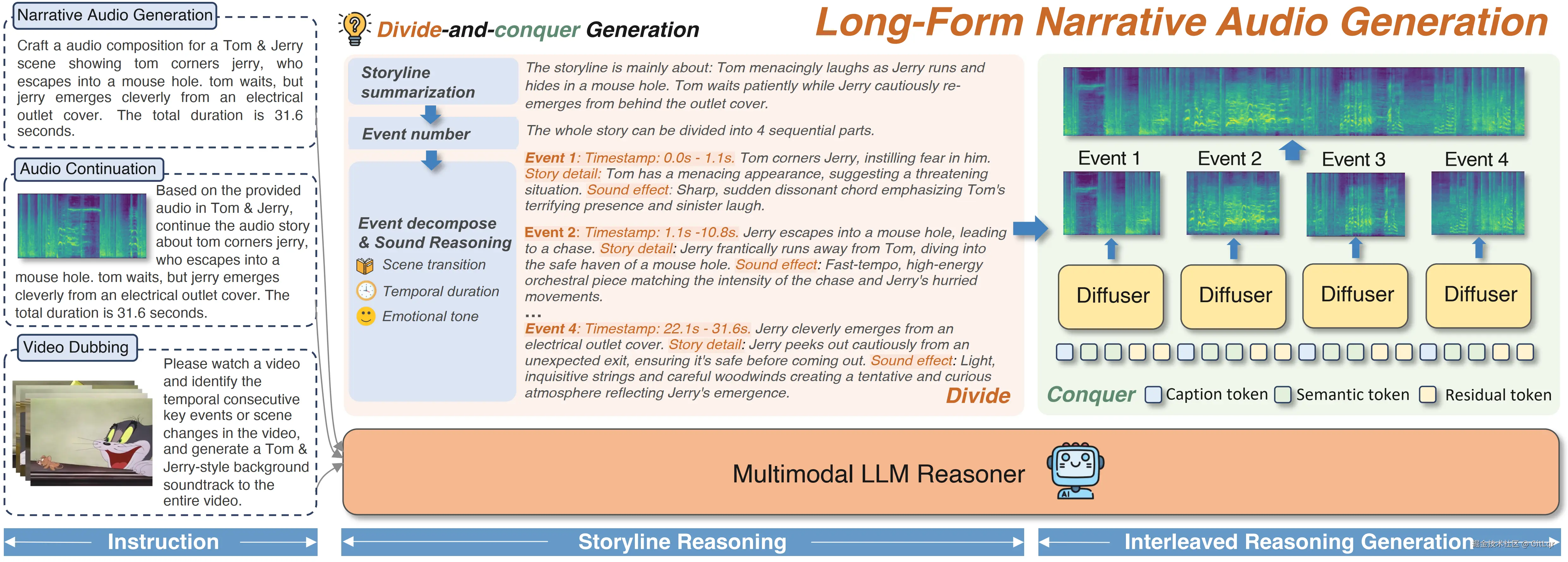
腾讯 ARC 实验室推出的 AudioStory 技术,代表着 AI 音频生成领域的又一重大突破。它使机器能够从文本描述中生成复杂、电影级的叙事音频,超越了传统模型仅能生成单一音效的局限。
这项技术旨在将文本描述转化为丰富而有层次的听觉体验,如同为故事配上电影原声。
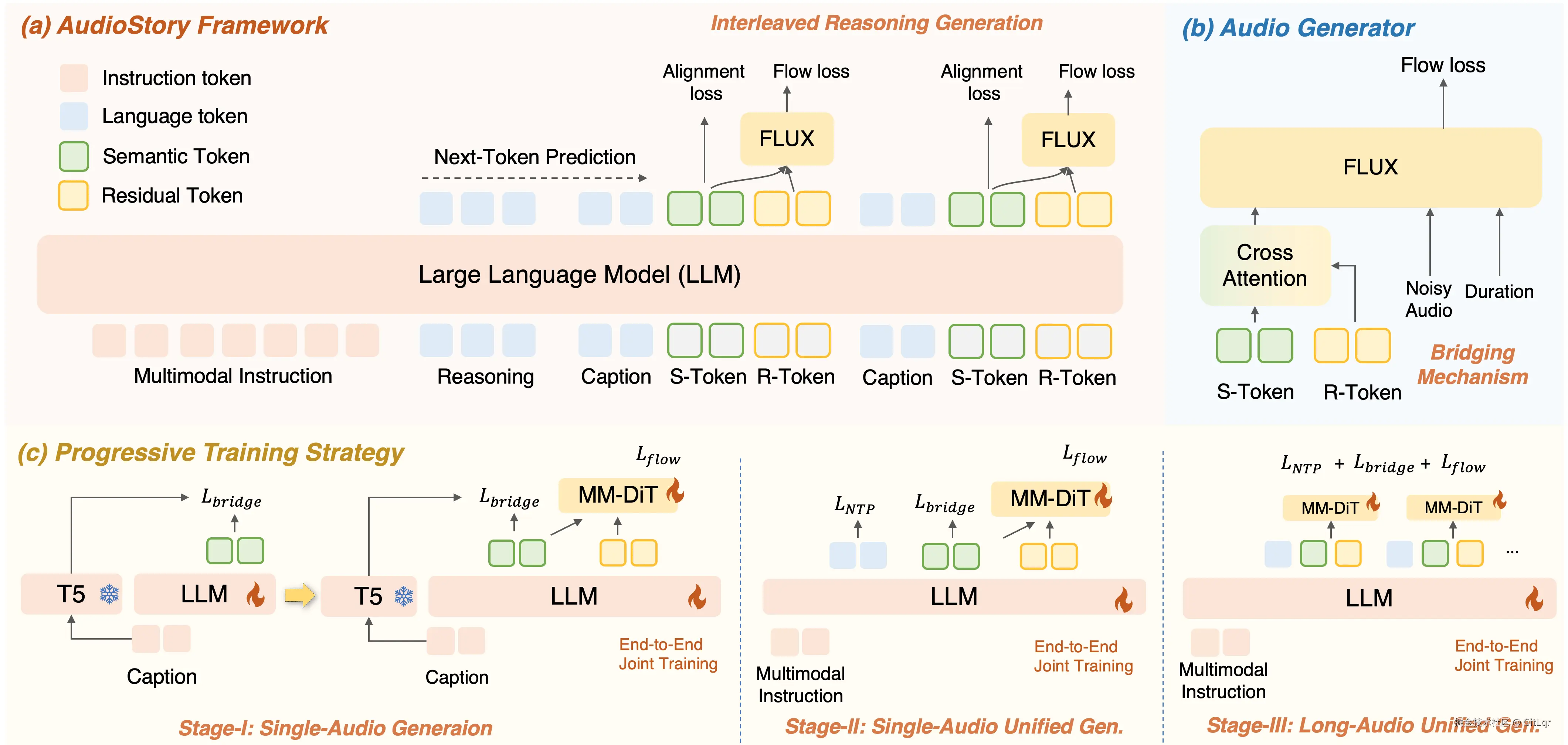
AudioStory 的核心创新在于:
经过三阶段渐进式训练,AudioStory 在 AudioStory-10K 基准数据集上展现出卓越的指令遵循能力、音频质量和一致性,性能全面超越现有竞品。
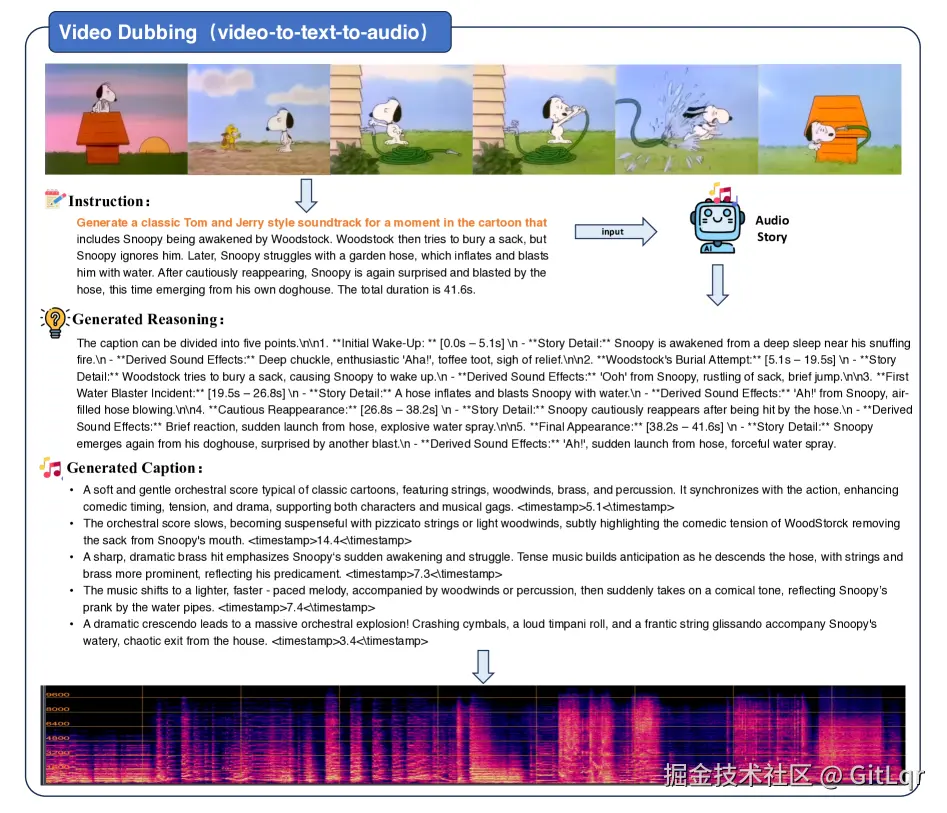
这项技术具有广泛的应用前景,包括自动为视频配音,以及智能推断并续写音频场景等,为 AI 有声书、智能播客和沉浸式游戏音效等领域铺平了道路,标志着 AI 在创意表达和艺术化叙事方面实现了质的飞跃。
?往期推荐:

