扫描王OCR
44M · 2026-04-08

学完 LangChain 第一阶段之后,如果你脑子里留下的只是 ChatModel、PromptTemplate、OutputParser、tool、memory、RAG、LCEL 这些 API 名字,其实还不算真正学会。
因为工程里最难的,从来不是“记住有哪些类”,而是搞清楚:
如果把这一阶段的内容压缩成一句话,我的判断是:
LangChain 的价值,也正在这里。
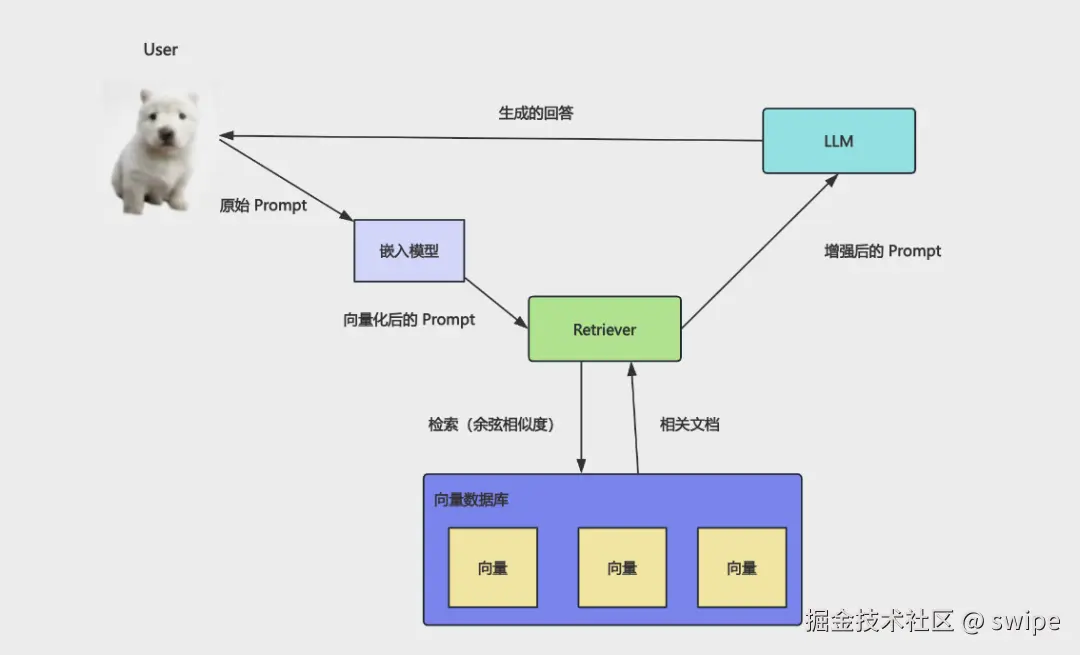
它不是单纯的“大模型 SDK 集合”,更像是一层 AI 应用运行时:上层面向业务,下层适配模型、工具、向量库和执行链路。
这篇文章不打算按 API 清单来回顾,而是从工程视角给出我对 LangChain 第一阶段的 6 个核心判断。你只要把这 6 件事想明白,后面继续学 LangGraph、LangSmith、MCP、RAG 优化,都会更顺。
很多人一开始会觉得,直接调 OpenAI、Claude、Gemini 的官方 SDK 不就行了,为什么还要加一层 LangChain?
如果你只是做一次性的 demo,这个问题成立。
但只要进入真实项目,它很快就不成立。
原因很简单,不同大模型提供商虽然都叫“聊天模型”,但接口细节并不统一。
比如系统提示词的位置就不一样:
messages 里system 字段system_instruction这还只是最表面的差异。
更实际的差异还包括:
如果业务代码直接绑定某一家接口,后果通常有两个:
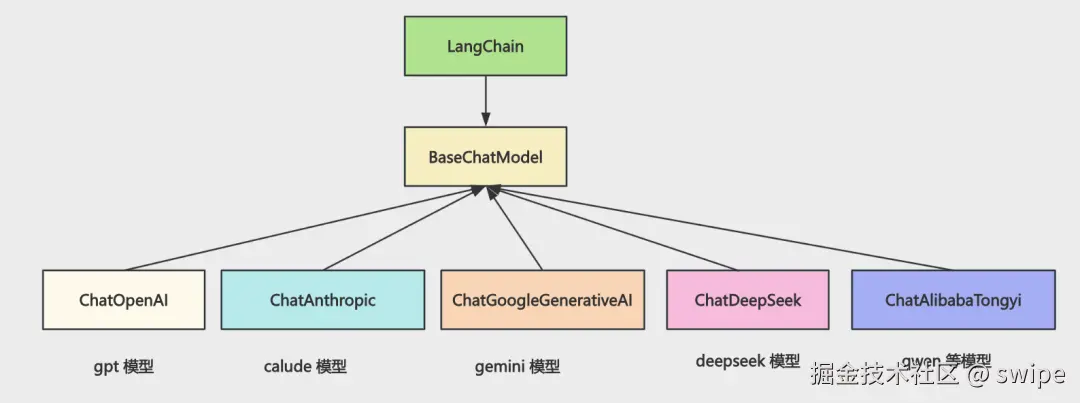
LangChain 在这里做的第一件事,就是把不同模型适配成统一的 BaseChatModel 抽象。
也就是说,你真正依赖的不是某一家模型的原生请求格式,而是 LangChain 统一后的调用语义。
这件事的工程价值非常大。
import "dotenv/config";
import { ChatOpenAI } from "@langchain/openai";
const model = new ChatOpenAI({
modelName: process.env.MODEL_NAME,
apiKey: process.env.OPENAI_API_KEY,
configuration: {
baseURL: process.env.OPENAI_BASE_URL,
},
});
const result = await model.invoke("解释一下什么是 RAG");
console.log(result.content);
这段代码本身很普通,但它的意义不在“成功调到了一个模型”,而在于你的业务侧只面向统一的 ChatModel 调用方式。
很多国产模型兼容 OpenAI 协议,所以用 ChatOpenAI 也能调,比如 Qwen、DeepSeek 的某些服务都支持这种方式。
但这不代表“有兼容协议就不需要专用适配类”。
原因是:
如果你只是跑基础文本对话,用兼容接口没问题。
如果你需要充分利用某个模型的专有特性,比如更细粒度的工具调用、多模态、特殊采样参数,那专用适配类通常更稳。
所以我的建议很明确:
这不是“写法偏好”,而是为了给模型切换和能力扩展留下余地。
很多团队一开始做 AI 功能,最先做的是拼字符串:
const prompt = `
你是企业知识库助手。
用户问题:
${question}
检索资料:
${docs}
历史对话:
${history}
`;
这段代码能跑,但只适合 demo。
因为真实项目里,Prompt 不是一段静态文本,而是一层持续演化的上下文组织系统。它至少会同时承载这些信息:
如果这些东西全都混在一个大字符串里,早晚会出事:
这也是为什么我更推荐把 Prompt 看成“上下文组装层”,而不是“提示词文本”。
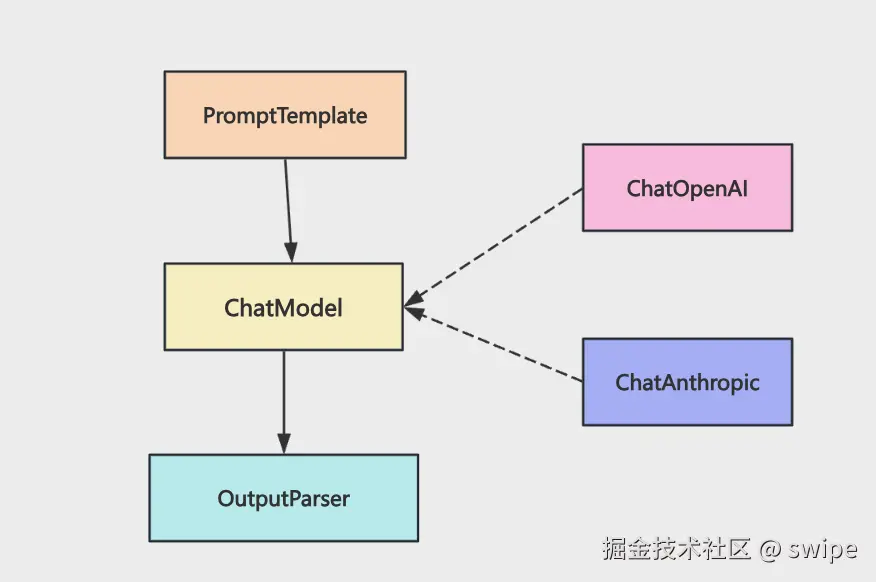
ChatPromptTemplate 解决的核心问题如果你用的是聊天模型,默认就应该优先考虑 ChatPromptTemplate。
import { ChatPromptTemplate, MessagesPlaceholder } from "@langchain/core/prompts";
const qaPrompt = ChatPromptTemplate.fromMessages([
[
"system",
`你是企业内部知识库助手。
1. 优先依据资料回答
2. 资料不足时明确说明不知道
3. 不要编造流程细节`,
],
new MessagesPlaceholder("history"),
[
"human",
`问题:{question}
资料:
{context}`,
],
]);
这段代码的价值不是“写法更优雅”,而是上下文来源被明确分层了:
system 放角色和高优先级规则history 放会话记忆human 放当前问题和动态上下文这让 Prompt 从“大字符串”变成了“可维护结构”。
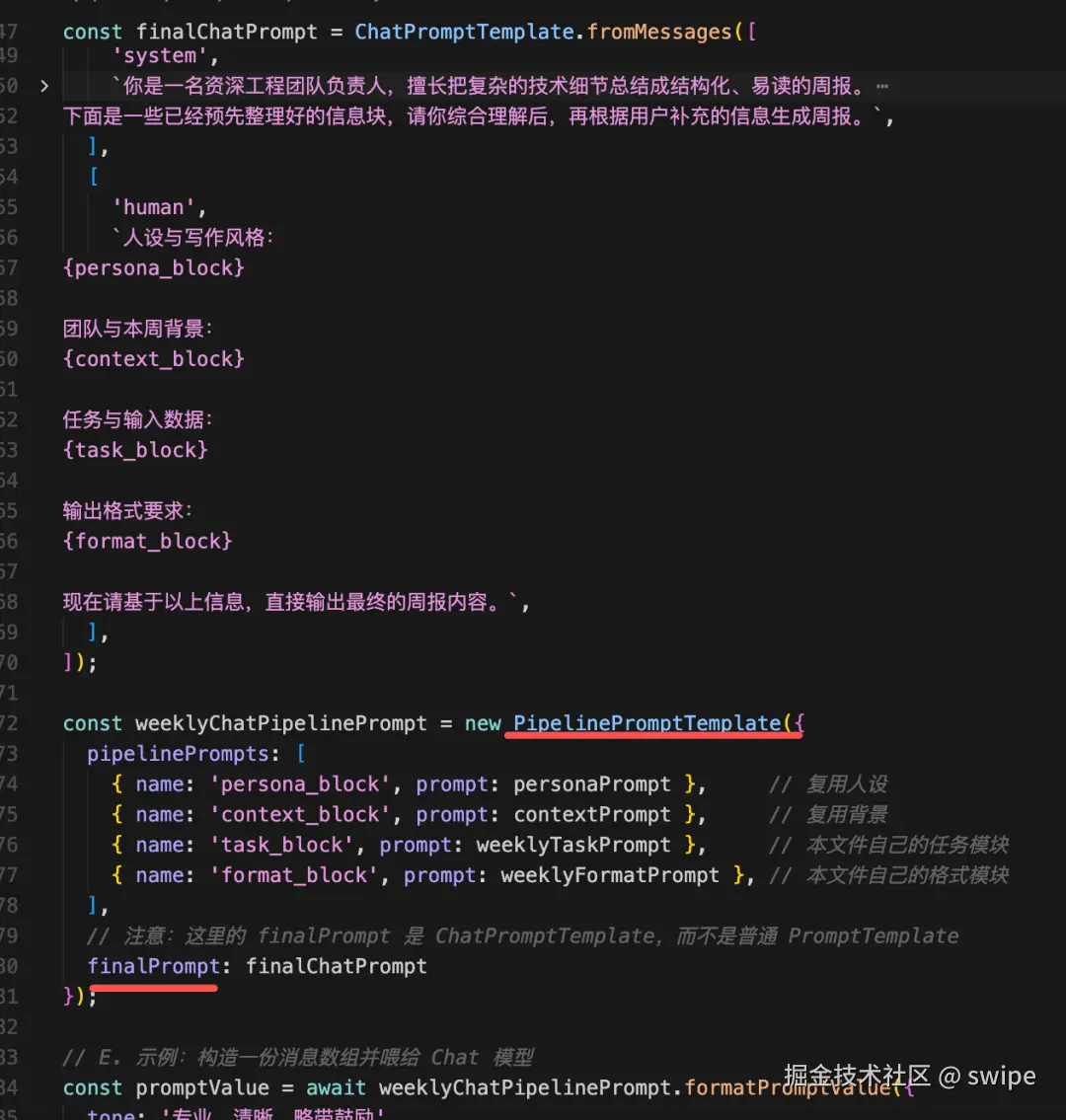
PipelinePromptTemplate一旦 Prompt 开始模块化,比如你要把下面这些块拆开复用:
这时 PipelinePromptTemplate 就有价值了。
它不是为了让模型“更聪明”,而是为了让 Prompt 资产可以像代码一样复用。
Few-shot 很常见,但也最容易被滥用。
适合 Few-shot 的场景:
不适合滥加 Few-shot 的场景:
因为 Few-shot 的本质是用上下文换模型行为一致性。
它不是免费的,代价就是上下文窗口和推理成本。
所以我的判断是:
AI 应用一旦进入业务系统,模型输出就不能一直停留在“自然语言挺像那么回事”的阶段。
因为你最终很可能要把结果继续交给:
这时“能看懂”不够,必须“结构稳定”。
LangChain 第一阶段里,输出控制这块非常关键。
我认为最值得建立的认知是:
withStructuredOutput如果模型支持 tool calling 或 JSON schema,优先用模型原生能力约束输出。
import { z } from "zod";
import { ChatOpenAI } from "@langchain/openai";
const model = new ChatOpenAI({
modelName: process.env.MODEL_NAME,
apiKey: process.env.OPENAI_API_KEY,
configuration: {
baseURL: process.env.OPENAI_BASE_URL,
},
});
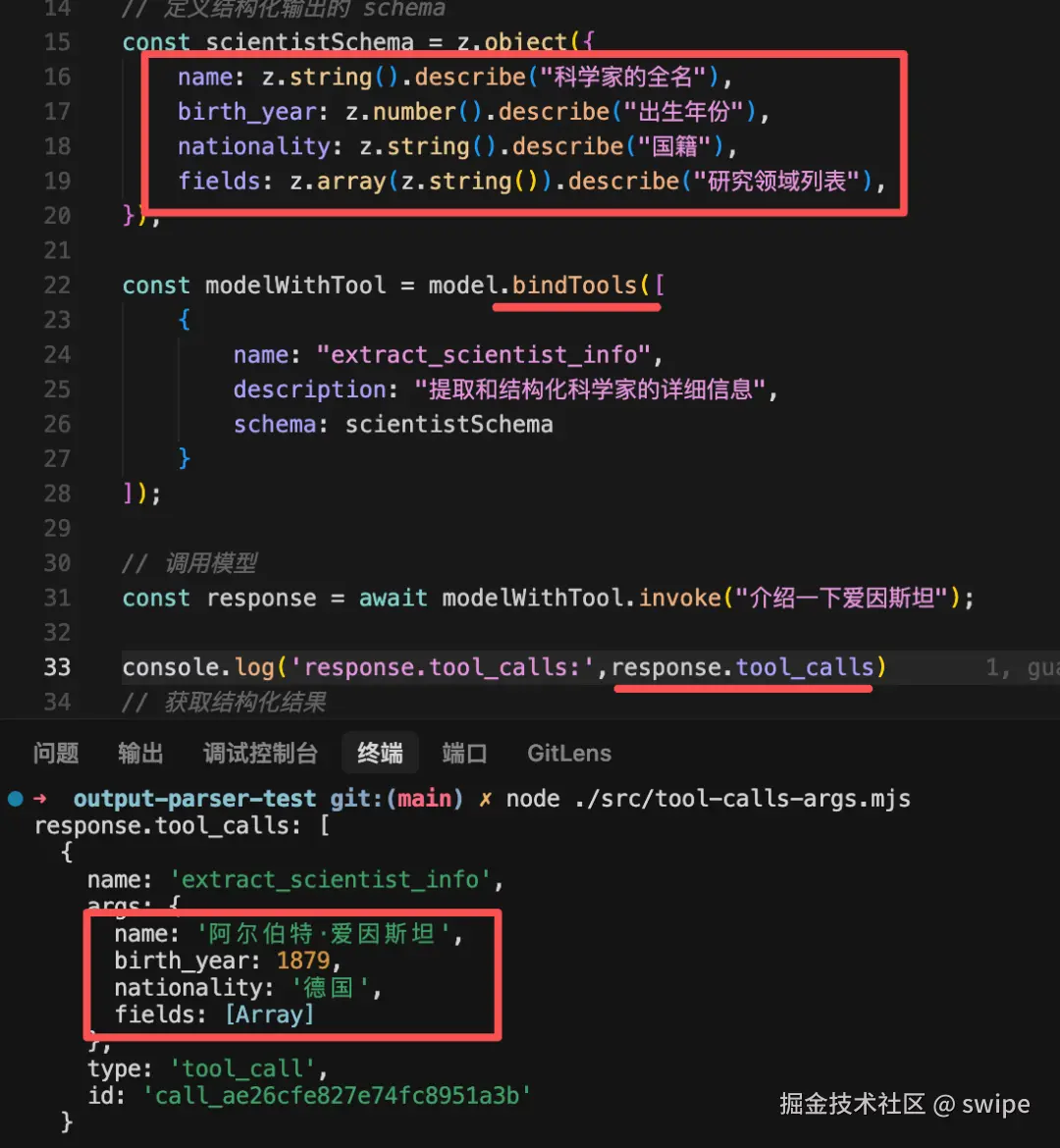
const ticketExtractor = model.withStructuredOutput(
z.object({
title: z.string().describe("工单标题"),
category: z.enum(["bug", "feature", "question"]).describe("工单类型"),
priority: z.enum(["low", "medium", "high"]).describe("优先级"),
})
);
const result = await ticketExtractor.invoke(
"用户反馈订单页面在手机端无法滚动,影响下单,优先处理。"
);
这样做的默认好处是:
有,而且在两个场景下很重要:
这时你就要退回到“Prompt 里写格式要求 + Parser 解析”的方案。
这在 Agent 场景里尤其常见。
比如流式工具调用时,参数往往会被拆成很多碎片返回,自己手动拼 JSON 很麻烦,这时像 JsonOutputToolsParser 这样的工具就很有价值。
StringOutputParser:你只要最终文本StructuredOutputParser:你要一个稳定 JSON 结构,但模型不一定原生支持XMLOutputParser:输出必须是 XML 之类的指定格式JsonOutputToolsParser:重点不是一般文本,而是 tool call 的结构化片段,尤其适合流式很多人分不清“结构化输出”和“工具调用”的边界。
这两个虽然都可能产生结构化 JSON,但不是一回事:
如果你的需求只是“把用户输入抽成对象”,优先用结构化输出。
如果你的需求是“让模型决定要不要触发外部能力”,那才是 tool call。
这是一个很典型的选型边界。
很多人学到 tool call 时会非常兴奋,因为它看起来像是大模型“终于可以干活了”。
这个感觉没错,但如果要说得更准确一点,我会这样定义:
模型不再只是返回一段答案,而是可以输出一个结构化动作意图:
这就是 Agent 的起点。
import { z } from "zod";
import { tool } from "@langchain/core/tools";
const searchPolicy = tool(
async ({ keyword }) => {
return `检索结果:关于「${keyword}」的制度文档共 3 篇。`;
},
{
name: "search_policy",
description: "检索企业制度文档",
schema: z.object({
keyword: z.string().describe("检索关键词"),
}),
}
);
const modelWithTools = model.bindTools([searchPolicy]);
这时模型就具备了调用 search_policy 的能力。
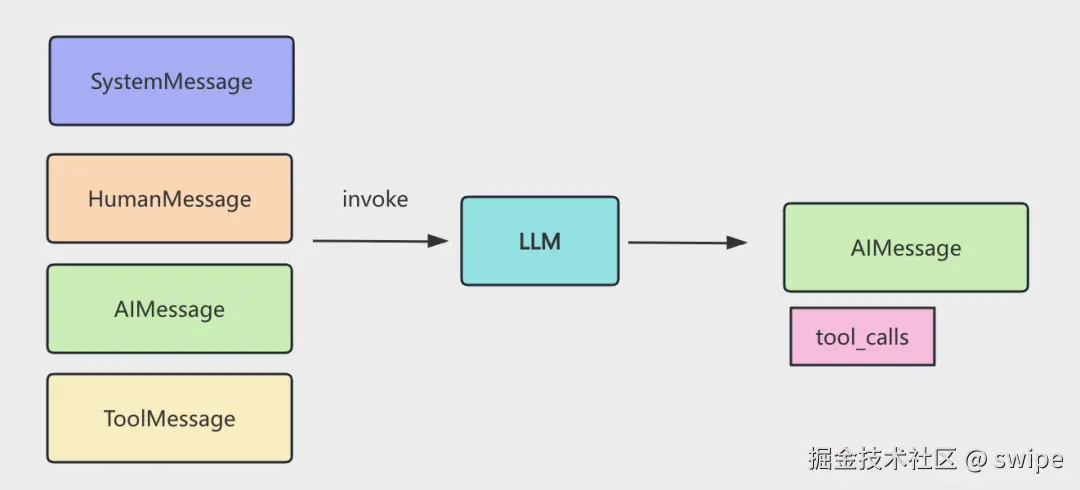
但真正重要的不是 bindTools 这一步,而是后面的执行闭环:
tool_callsToolMessage也就是说,tool call 不是“一次函数调用”,而是一个闭环过程。
因为模型并不真正理解你的函数实现,它只看两样东西:
所以很多 tool 调不准,不是模型太笨,而是工具契约写得不清楚。
一个很实用的经验是:
name 要明确,不要太抽象description 要写清楚何时该用、不该用自己定义 tool 解决的是“我手里已有的本地能力”。
MCP 解决的是“别人已经实现好的能力,我能不能标准化接进来”。
这件事对 Agent 生态特别关键。
因为现实里很多高价值能力并不是你自己写的,而是已经由:
这些外部系统提供出来。
MCP 相当于给“外部可调用能力”建立了一套统一接入方式。
在 LangChain 里,@langchain/mcp-adapters 则把这层能力转成了可以被模型绑定和调用的工具集合。
我的建议很简单:
Tool 是局部能力封装。
MCP 是跨进程、跨系统、可复用的能力接口。
它们不是互斥,而是同一层动作系统的两种接入方式。
很多初学者容易把 memory 和 RAG 理解成“给模型加更多内容”。
这个理解太粗了。
它们真正解决的问题是:
这是一个上下文选择问题,而不是简单堆料问题。
messages因为上下文窗口不是无限的。
对话一长,就会遇到这些问题:
这也是为什么 Claude Code、Cursor 这类产品一旦上下文变长,就会开始做总结、压缩或选择性保留。
最简单,保留最近几轮,丢掉更早的。
适合:
不适合:
把旧消息压缩成摘要,再带进上下文。
适合:
代价是:
把历史对话向量化,在当前 query 来时再召回相关部分。
这才是真正更接近“长时记忆”的方案。
因为它不是把所有历史都塞进来,而是按语义相关性选。
RAG 的核心流程可以压缩成两段:
离线阶段通常包含:
在线阶段通常包含:
因为实际效果受很多前置因素影响:
比如 k 就不是越大越好。
再比如 chunkSize 也没有绝对标准。
因为无论对象是:
本质上都在回答同一个问题:
只要问题是“按语义相关性挑上下文”,向量检索就是非常自然的手段。
所以我对 memory 和 RAG 的统一理解是:
它们不是两门完全不同的技术,而是同一类上下文选择问题在不同数据源上的应用。
如果只学前面的组件,LangChain 更像一套 AI 开发工具箱:
这样当然能写功能,但一旦系统复杂,问题就来了:
这就是为什么我认为 LCEL 是第一阶段里真正的分水岭。
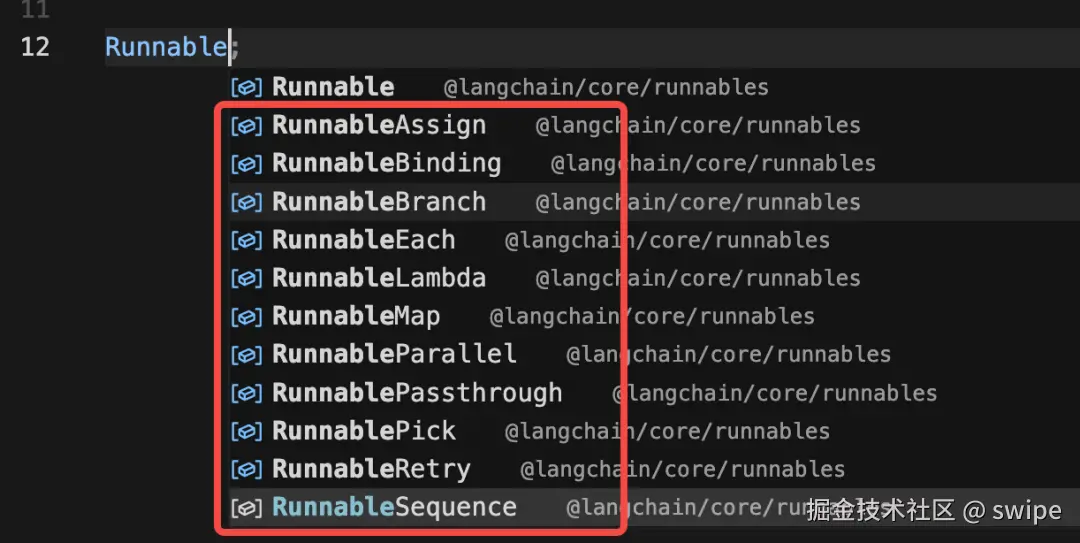
LCEL 的底层是 Runnable 抽象。
很多组件都实现了 Runnable:
一旦它们都能被当成 Runnable,你就可以用统一方式把它们编排起来。
import { RunnableSequence } from "@langchain/core/runnables";
const chain = RunnableSequence.from([
prompt,
model,
parser,
]);
const result = await chain.invoke(input);
这看起来像是“少写了几行代码”,但它真正改变的是程序结构:
invoke / stream / batch因为 AI 系统最难维护的,通常不是单个节点,而是节点之间的关系。
比如这些典型场景:
RunnableSequenceRunnableBranchRunnableMapRunnableLambdaRunnablePassthroughRunnableWithMessageHistory这套东西拼起来后,AI 应用才从“多个 API 调用”变成“一个工作流”。
原始资料里提到的几个能力,我认为都非常重要:
withRetrywithFallbackswithConfigcallbacks它们之所以关键,是因为它们说明了一件事:
这就很像工业流水线上的每一道工位:
一旦你理解到这一步,就会明白为什么后面的 LangSmith 会建立在 Runnable 和 callbacks 之上。
因为只有当链路被声明出来、节点边界清晰,监控和追踪才有抓手。
const chain = RunnableSequence.from([
normalizeQuestion,
retrieveContext,
buildPrompt,
model,
parser,
]).withRetry({
stopAfterAttempt: 3,
});
这条链背后的工程意义比代码本身更重要:
之后如果你想:
streambatchcallbackswithRetry都不需要重写主流程结构。
这就是 LCEL 的价值。
如果把这一阶段所有内容重新压缩,我会这样总结:
它让你不用把业务逻辑写死在某一家模型的原生协议上。
它让 Prompt 从字符串,变成可维护的上下文组装层。
它让模型结果能更稳定地进入业务系统,而不是停留在“看起来像对了”的自然语言层面。
它让模型从“会回答”升级成“会决策并调用外部能力”。
它们都在回答:当前这一轮,到底该给模型看哪些信息。
它把前面这些能力真正连接成一条可控、可观测、可扩展的工作流。
这 6 件事拼起来,才是一个完整 AI Agent 系统的骨架。
学完 LangChain 第一阶段后,我最大的感受不是“又学会了几个库”,而是对 AI Agent 开发这件事有了更稳定的结构化理解。
过去很多人把 AI 应用理解成:
但只要你真正做过一点项目,就会知道远不止如此。
你真正要解决的是这几个层面的问题:
LangChain 这套体系,正好对应了这几个层面。
所以我现在对 LangChain 的判断很简单:
这也是为什么我认为,第一阶段学完之后,最值得带走的不是 API 记忆,而是这套“把 AI 系统拆成输入、输出、动作、记忆、知识和流程”的工程认知。
后面继续学 LangGraph、LangSmith,或者自己做更复杂的 Agent,真正会反复用到的,也正是这套认知框架,而不是某一个具体类名。
Windows + RTX 5090 + ComfyUI 桌面版 安装 SageAttention 完全手册
08-Java工程师的Python第八课-框架入门

