


影趣
76.13M · 2026-04-11

随着大模型应用从“能用”走向“好用”,Agentic RAG(智能体化检索增强生成) 已成为解决复杂业务场景的核心架构。相比传统RAG的“一次检索、一次生成”,Agentic RAG通过引入自主规划、多轮迭代、工具调用的智能体能力,让系统能处理拆解复杂问题、自我校验信息、动态补充检索,准确率大幅提升。
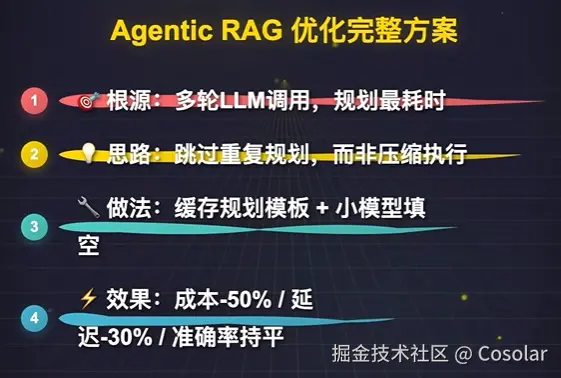
但生产环境的实测数据给我们泼了冷水:从传统RAG升级到Agentic RAG后,平均响应时间从3秒暴增至14秒。根源在于Agentic RAG的多轮LLM调用——分析问题、规划步骤、判断信息充足性、多轮检索,每一步都要耗时1-3秒,累计下来延迟高得难以接受。
更棘手的是,简单限制迭代次数、用小模型替代中间步骤等“治标”方案,都会直接导致准确率跳水,违背升级Agentic架构的初衷。如何在保住Agentic RAG高准确率的同时,把延迟打回3秒内、成本砍半?
本文将深度拆解Agentic RAG规划缓存这一生产级核心优化方案,从原理、实战步骤、代码实现到避坑指南全流程覆盖,帮你落地“高准确+低延迟+低成本”的Agentic RAG系统。
传统RAG(Naive RAG) 是线性的“被动响应”流程:
用户提问 → 向量检索 → 上下文拼接 → LLM单次生成 → 返回答案
Agentic RAG 是“主动思考”的闭环架构:
用户提问 → 规划Agent(LLM)分析意图 → 拆解任务 → 首轮检索 → 校验信息 → 不足则二次检索 → ... → 信息充足 → 生成答案
Agentic RAG慢,慢在“重复规划”。
观察业务场景会发现:80%的用户问题属于有限的几类任务模式。比如:
这些同类问题的“处理逻辑(规划步骤)完全一致”,只是具体实体(北京/上海、苹果/华为)不同。传统Agentic RAG却每次都让大模型从头分析、从头拆解、从头规划,造成巨大的算力与时间浪费。
规划缓存的核心创新: 不缓存“答案”,只缓存“怎么做”的规划模板。
规划缓存系统由5大核心模块组成,嵌入Agentic RAG主流程:
整体流程:
用户提问 → 意图提取 → 模板匹配
├── 命中 → 小模型填充模板 → 执行检索/工具 → 生成答案
└── 未命中 → 大模型完整规划+执行 → 提取通用模板 → 存入缓存 → 生成答案
用轻量小模型(如GPT-4o-mini、Llama 3 8B、Qwen 7B) 替代大模型,提取问题的高层意图关键词(而非表面语义)。
气象查询销量均值计算产品技术对比from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
import json
# 1. 初始化轻量小模型(意图提取专用)
intent_llm = ChatOpenAI(
model_name="gpt-4o-mini", # 低成本小模型
temperature=0.0, # 确定性输出
max_tokens=50
)
# 2. 意图提取Prompt模板(核心:输出标准化关键词)
intent_prompt = PromptTemplate(
input_variables=["query"],
template="""
你是任务意图分类器,仅从以下固定类别中提取1个最匹配的高层意图关键词,不要额外解释:
固定类别:
- 事实查询(实体/数据/属性查询)
- 数值计算(求和/均值/增长率/统计)
- 对比分析(两实体/多维度对比)
- 汇总总结(文档/报告/观点提炼)
- 步骤指导(操作流程/解决方案)
- 原因分析(问题根源/影响因素)
用户问题:{query}
输出:仅返回关键词,不要其他内容
"""
)
# 3. 意图提取函数
def extract_intent(query: str) -> str:
"""提取用户问题的高层意图关键词"""
prompt = intent_prompt.format(query=query)
response = intent_llm.predict(prompt)
return response.strip()
# 测试
if __name__ == "__main__":
test_queries = [
"查2025年天津的GDP总量",
"计算A产品近3个月的平均销量",
"对比iOS和Android的系统安全性",
"总结2025年AI行业报告核心观点"
]
for q in test_queries:
intent = extract_intent(q)
print(f"问题:{q} → 意图:{intent}")
采用键值对存储,Key为意图关键词,Value为规划模板(结构化JSON)。
{占位符}标记可变实体(如{实体1}、{指标}、{时间范围})示例模板(JSON格式):
{
"intent_key": "数值计算_均值",
"plan_steps": [
"步骤1:从知识库检索{实体}在{时间范围}的{指标}原始数据",
"步骤2:校验数据完整性,缺失则补充检索",
"步骤3:用均值公式(总和/数据条数)计算结果",
"步骤4:生成包含计算过程、结果、数据来源的回答"
],
"placeholders": ["实体", "时间范围", "指标"],
"create_time": "2026-04-01",
"hit_count": 0
}
生产级缓存管理器代码:
import redis
import json
import hashlib
from typing import Dict, Optional
class PlanCacheManager:
"""Agentic RAG规划缓存管理器(生产级)"""
def __init__(
self,
redis_host: str = "localhost",
redis_port: int = 6379,
redis_db: int = 0,
cache_ttl: int = 86400 * 7 # 缓存有效期7天
):
self.redis_client = redis.Redis(
host=redis_host, port=redis_port, db=redis_db, decode_responses=True
)
self.cache_ttl = cache_ttl
self.cache_prefix = "agentic_rag:plan:"
def _get_cache_key(self, intent_key: str) -> str:
"""生成缓存Key(前缀+意图关键词)"""
return f"{self.cache_prefix}{intent_key}"
def get_plan(self, intent_key: str) -> Optional[Dict]:
"""根据意图关键词获取缓存模板"""
cache_key = self._get_cache_key(intent_key)
plan_json = self.redis_client.get(cache_key)
if plan_json:
# 命中缓存:更新命中次数
plan = json.loads(plan_json)
plan["hit_count"] += 1
self.redis_client.setex(cache_key, self.cache_ttl, json.dumps(plan, ensure_ascii=False))
return plan
return None
def save_plan(self, intent_key: str, plan: Dict):
"""保存新模板到缓存"""
cache_key = self._get_cache_key(intent_key)
# 初始化命中次数
plan["hit_count"] = 1
plan["create_time"] = "2026-04-05"
plan_json = json.dumps(plan, ensure_ascii=False)
self.redis_client.setex(cache_key, self.cache_ttl, plan_json)
def delete_plan(self, intent_key: str):
"""删除缓存模板(数据更新时使用)"""
cache_key = self._get_cache_key(intent_key)
self.redis_client.delete(cache_key)
# 初始化缓存管理器
cache_manager = PlanCacheManager()
缓存命中后,无需大模型参与,用小模型提取问题中的具体实体,替换模板占位符。
填充代码实现:
# 初始化填充专用小模型
fill_llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0.0, max_tokens=100)
fill_prompt = PromptTemplate(
input_variables=["query", "placeholders", "plan_steps"],
template="""
提取用户问题中的以下占位符对应内容,严格按JSON格式输出,不要额外内容:
占位符列表:{placeholders}
用户问题:{query}
输出格式:{{"占位符1":"内容1", "占位符2":"内容2"}}
填充后规划步骤:
{plan_steps}
"""
)
def fill_plan_template(query: str, plan: Dict) -> Dict:
"""小模型填充模板占位符"""
placeholders = plan["placeholders"]
plan_steps = plan["plan_steps"]
prompt = fill_prompt.format(
query=query,
placeholders=placeholders,
plan_steps="n".join(plan_steps)
)
# 提取占位符内容
fill_content = fill_llm.predict(prompt)
fill_dict = json.loads(fill_content)
# 替换模板步骤中的占位符
filled_steps = []
for step in plan_steps:
for key, value in fill_dict.items():
step = step.replace(f"{{{key}}}", value)
filled_steps.append(step)
return {
"filled_steps": filled_steps,
"fill_content": fill_dict,
"original_intent": plan["intent_key"]
}
# 测试:命中模板后填充
if __name__ == "__main__":
# 模拟缓存命中的模板
test_plan = {
"intent_key": "数值计算_均值",
"plan_steps": [
"步骤1:检索{实体}在{时间范围}的{指标}数据",
"步骤2:计算均值并生成回答"
],
"placeholders": ["实体", "时间范围", "指标"]
}
test_query = "计算华为手机2025年上半年的销量均值"
filled_plan = fill_plan_template(test_query, test_plan)
print("填充后规划步骤:", filled_plan["filled_steps"])
# 初始化大模型(规划专用,如GPT-4o)
planning_llm = ChatOpenAI(model_name="gpt-4o", temperature=0.1, max_tokens=300)
# 模板生成Prompt(核心:抽象通用步骤)
plan_gen_prompt = PromptTemplate(
input_variables=["query", "executed_steps"],
template="""
基于用户问题和实际执行步骤,生成通用规划模板:
1. 抹除所有具体实体、数值、时间,替换为{占位符}
2. 提取高层意图关键词(从固定类别选)
3. 输出JSON格式:{{"intent_key":"关键词", "plan_steps":[步骤1,步骤2], "placeholders":[占位符列表]}}
用户问题:{query}
执行步骤:{executed_steps}
输出:仅返回JSON
"""
)
def generate_and_save_plan(query: str, executed_steps: list):
"""大模型生成通用模板并保存"""
# 生成模板
prompt = plan_gen_prompt.format(
query=query,
executed_steps="n".join(executed_steps)
)
plan_json = planning_llm.predict(prompt)
new_plan = json.loads(plan_json)
# 保存到缓存
cache_manager.save_plan(new_plan["intent_key"], new_plan)
return new_plan
def agentic_rag_with_cache(query: str) -> str:
"""带规划缓存的Agentic RAG主函数"""
# 1. 提取意图关键词
intent_key = extract_intent(query)
print(f"[流程] 提取意图:{intent_key}")
# 2. 匹配缓存模板
cached_plan = cache_manager.get_plan(intent_key)
if cached_plan:
# 命中缓存:小模型填充 → 执行 → 生成
print("[流程] 缓存命中,跳过大模型规划")
filled_plan = fill_plan_template(query, cached_plan)
# 执行填充后的步骤(检索/工具调用)
answer = execute_plan(filled_plan["filled_steps"])
else:
# 未命中:大模型完整规划 → 执行 → 生成模板 → 保存
print("[流程] 缓存未命中,执行完整Agentic流程")
executed_steps = full_agentic_planning(query) # 大模型规划
answer = execute_plan(executed_steps) # 执行
new_plan = generate_and_save_plan(query, executed_steps) # 生成模板
print(f"[流程] 新模板已保存:{new_plan['intent_key']}")
return answer
# 辅助函数:执行规划步骤(检索/工具调用,简化实现)
def execute_plan(steps: list) -> str:
"""模拟执行规划步骤,返回答案"""
return f"基于规划步骤执行完成:n" + "n".join(steps) + "nn最终答案:xxx"
# 辅助函数:完整Agentic规划(大模型,简化实现)
def full_agentic_planning(query: str) -> list:
"""模拟大模型完整规划流程"""
return [
f"步骤1:检索{query}相关数据",
"步骤2:校验数据完整性",
"步骤3:分析并生成答案"
]
# 测试
if __name__ == "__main__":
# 首次提问(未命中,生成模板)
q1 = "计算苹果2025年Q1的平均营收"
print("首次提问结果:", agentic_rag_with_cache(q1))
# 二次同类提问(命中缓存)
q2 = "计算华为2025年Q2的平均营收"
print("n二次提问结果:", agentic_rag_with_cache(q2))
问题:意图关键词覆盖不足,导致不同任务匹配同一模板(如“查天气”和“查股价”都匹配“事实查询”) 解决方案:
数值计算_均值、对比分析_产品)问题:知识库更新、业务流程调整后,缓存模板仍按旧逻辑执行 解决方案:
数值计算_销量模板)问题:系统上线初期模板少,缓存命中率低(<10%) 解决方案:
问题:轻量小模型意图提取、占位符填充准确率低 解决方案:
问题:长期运行后模板库过大(>1000条),匹配耗时增加 解决方案:
计算_均值、计算_求和)合并为数值计算通用模板需重点监控以下指标,保障稳定性:
Agentic RAG的速度瓶颈根源是多轮重复的LLM规划,规划缓存通过**“缓存逻辑、复用模板、小模型加速”**的思路,完美解决“准确率与速度”的矛盾:
Agentic RAG是大模型应用的必然趋势,而规划缓存是打通“技术效果”到“生产可用”的关键一步。
以上就是Agentic RAG规划缓存的全实战方案,从原理到代码、从落地到避坑全覆盖。你在落地过程中遇到了哪些缓存相关问题?或者有更优的优化思路?欢迎在评论区交流,一起打造更快更稳的大模型RAG系统!

