锦书在线
80.52M · 2026-03-21

想象你走进一家餐厅,菜单上写着"按食材重量计费"。你点了一碗面,但结账时发现:面条、汤底、葱花全都算重量,而且不同食材单价不同。大模型的 Token 计费,本质上就是这么回事。
大模型(Large Language Model, LLM)是经过海量文本训练的 AI 系统,能理解和生成人类语言。GPT、Claude、Gemini、DeepSeek 都属于此类。Token 则是大模型处理文本的最小单位——不是字,不是词,而是介于两者之间的一种"语言积木"。模型读取你的输入、生成回复,都是以 Token 为单位来计算和计费的。
为什么理解这些概念很重要?因为它直接影响三件事:
本文将从四个维度展开:对话的本质是什么、上下文有什么限制、Token 怎么计费、主流编程模型怎么选。无论你是刚接触 AI 的新手,还是正在做技术选型的开发者,都能找到需要的答案。
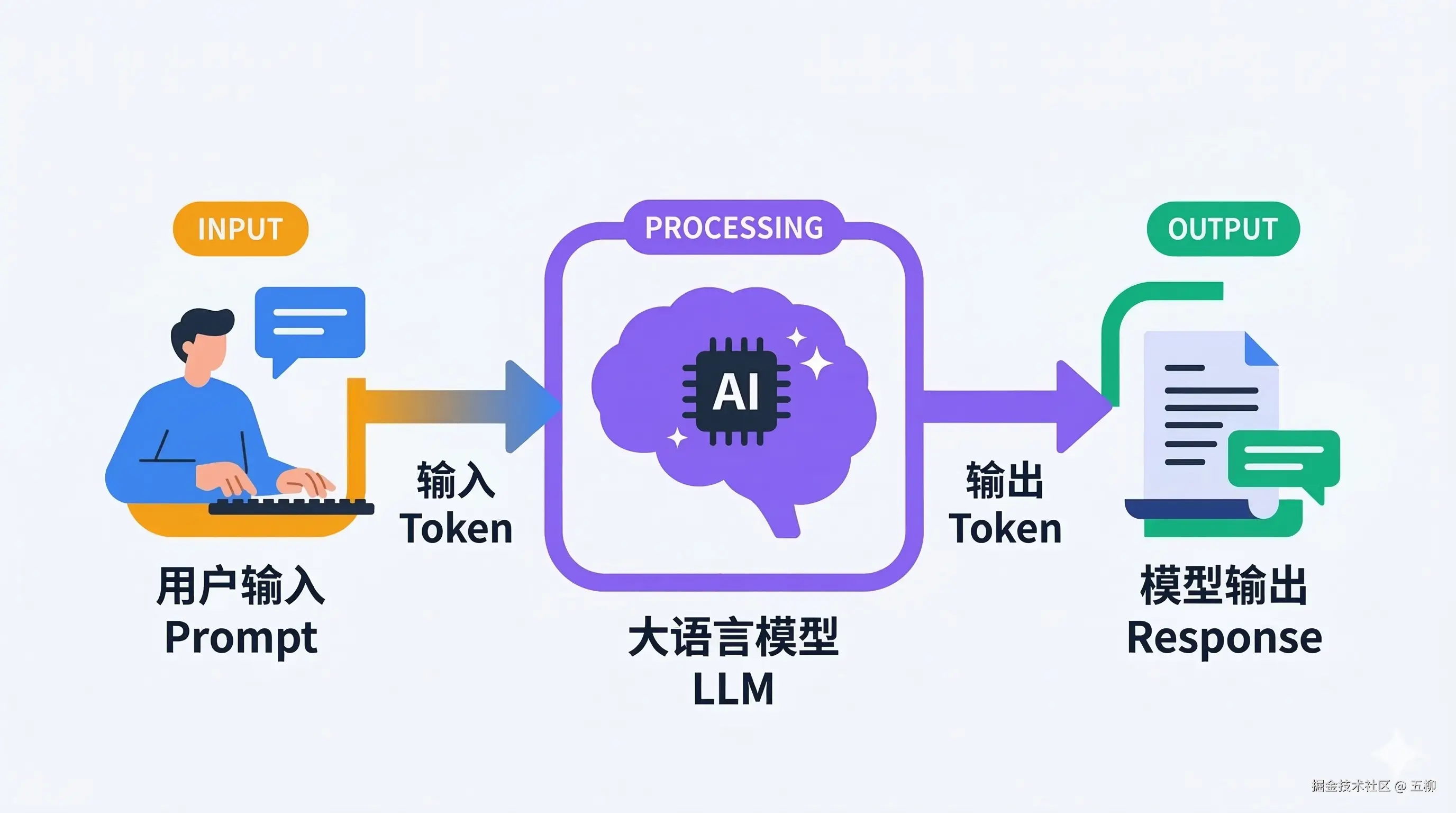
和大模型"聊天"看起来像跟真人对话,但底层机制完全不同。每一轮对话的本质是一次单向的请求-响应:
就像发邮件一样,模型没有"持续思考"的状态。它每次都是拿到你的完整输入,从头开始理解,然后一次性生成回复。这意味着每一轮对话都是一次独立的 API 调用,模型本身并不会"记住"之前聊了什么。
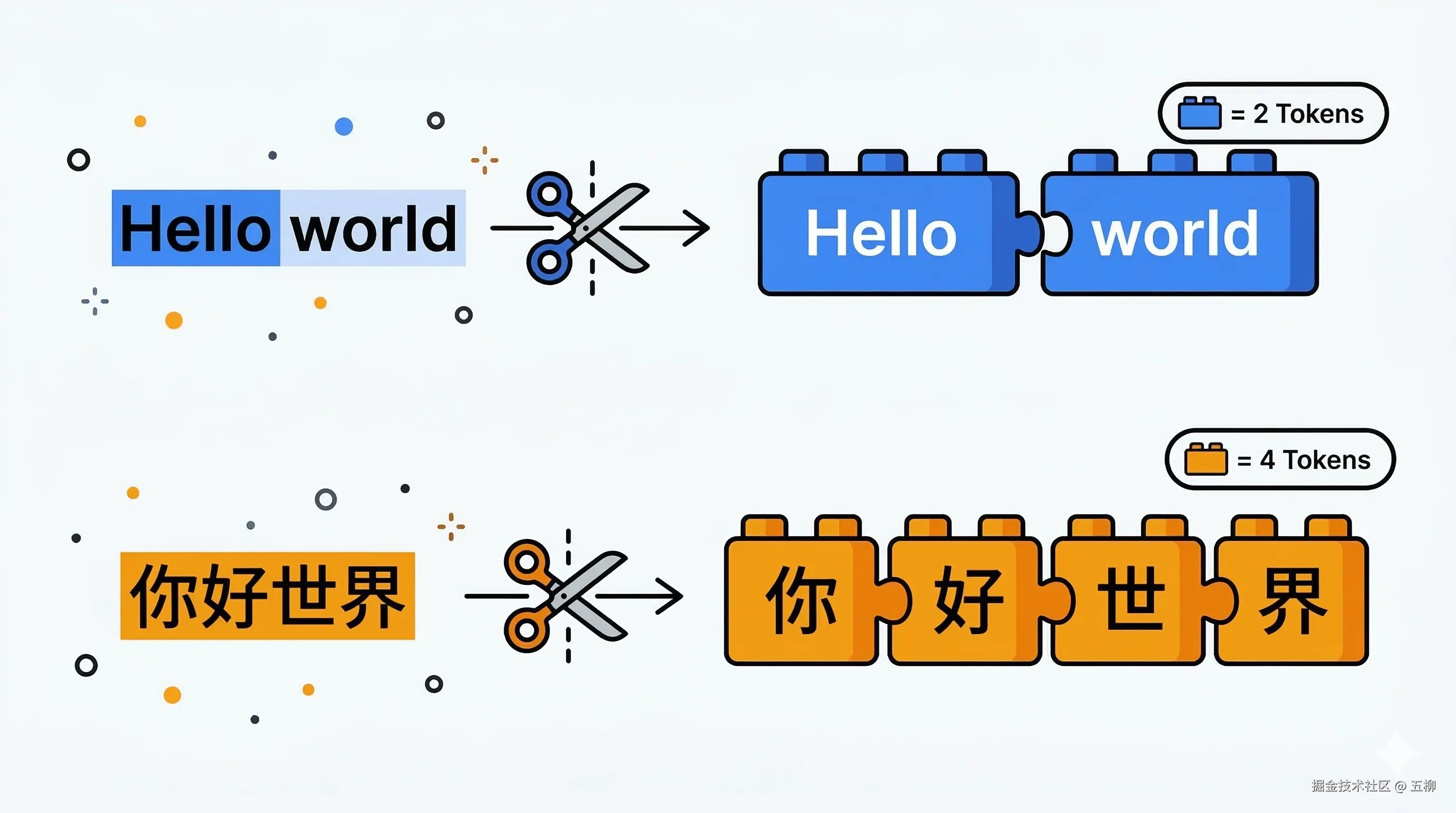
Token 是模型处理文本的基本单位。你可以把它理解为语言积木——模型把文本拆成一块块积木来处理,而不是一个字一个字地读。
不同语言的切分方式不同:
"Hello world" → ["Hello", " world"] = 2 Token"你好世界" → ["你", "好", "世", "界"] 约 4-8 Token关键认知:中文消耗的 Token 显著多于英文。 同样的语义内容,中文输入可能比英文多消耗 50%-100% 的 Token,这直接影响使用成本。
想亲自体验?可以用 OpenAI 的 Tokenizer 可视化工具 试试,把中英文分别粘贴进去对比。
日常使用中,你在 Claude 或 GPT 里的一个"聊天窗口"就是一个会话(Session)。每发送一条消息就是一轮对话。
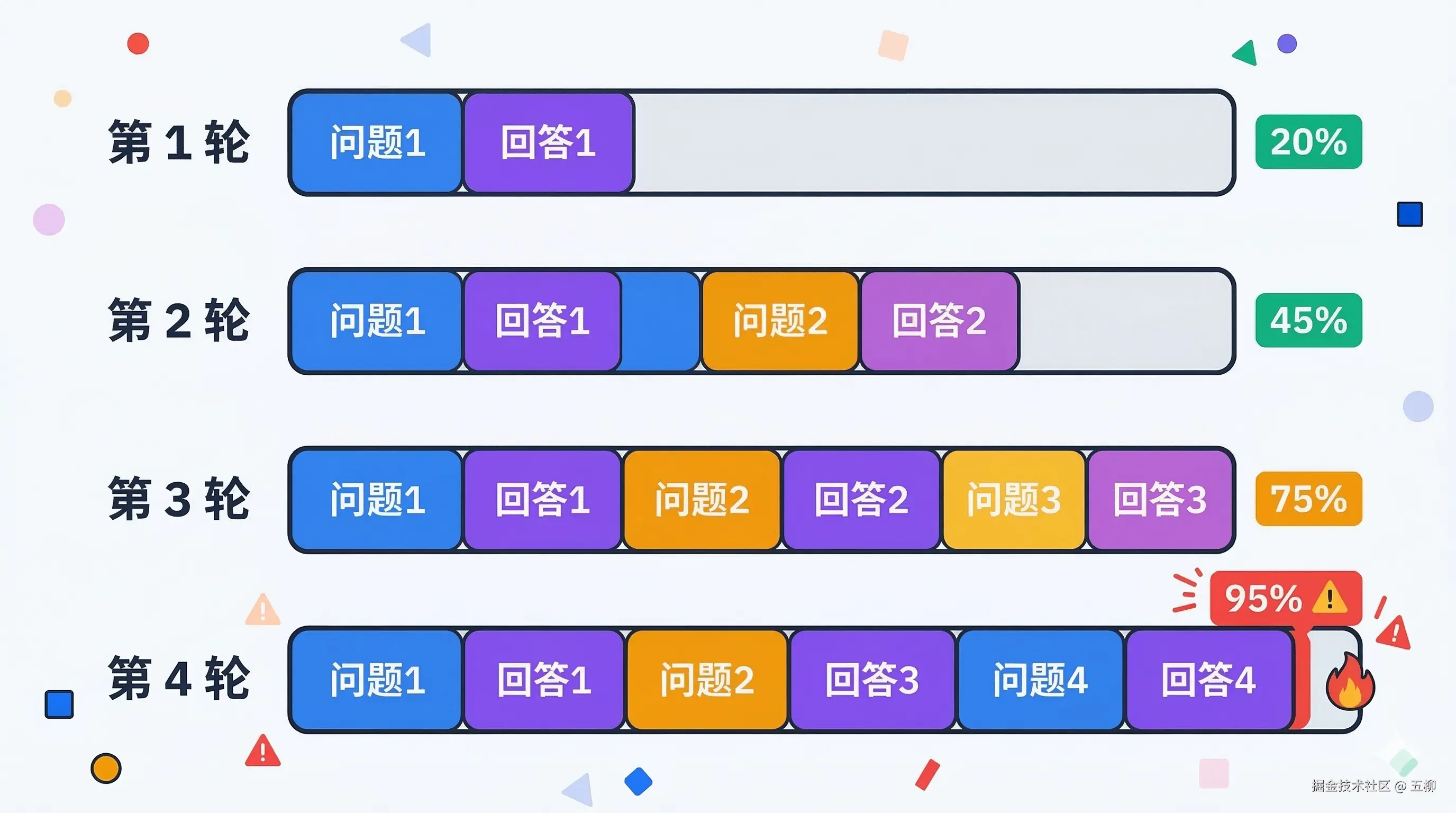
关键问题在于:每一轮对话,模型都要重新读取整个会话历史。
举个例子:
| 轮次 | 你发送的内容 | 模型实际处理的 Token |
|---|---|---|
| 第 1 轮 | "帮我写个排序函数" | 你的消息(约 20 Token) |
| 第 2 轮 | "改成降序" | 第 1 轮完整对话 + 你的新消息(约 300 Token) |
| 第 3 轮 | "加上注释" | 前 2 轮完整对话 + 你的新消息(约 600 Token) |
| 第 10 轮 | "还有问题吗?" | 前 9 轮完整对话 + 你的新消息(可能几千 Token) |
这就是为什么聊得越久花费越高——Token 是累积计费的。每一轮对话的成本都包含了之前所有历史消息的 Token。
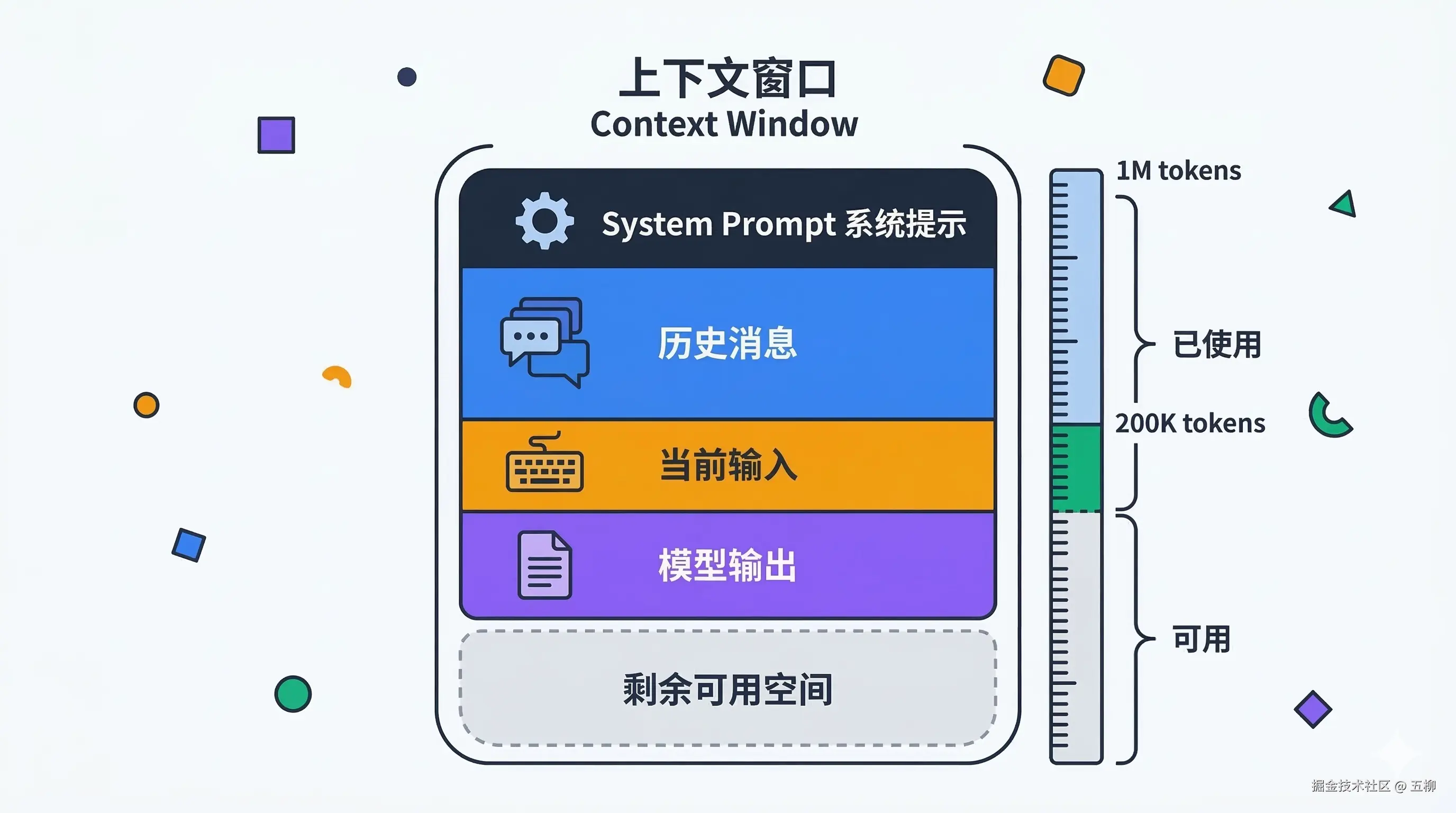
上下文窗口是模型的**"工作记忆"容量**——它能同时处理的 Token 总量上限。这个上限包含输入和输出的所有 Token。
打个比方:上下文窗口就像一张书桌。桌子越大,能同时摊开的资料越多。128K 上下文约等于一本 300 页的书,1M 上下文则约等于 7-8 本书。
| 模型 | 标准上下文 | 扩展上下文 | 备注 |
|---|---|---|---|
| Claude Opus/Sonnet 4.6 | 1M | - | 原生支持,无需额外配置(2026.3.13 GA) |
| GPT-5.4 | 272K | 1.05M | 需显式开启扩展窗口 |
| GPT-5.2 | 400K | - | |
| Gemini 3 Pro | 1M | - | 原生支持,长上下文最强 |
| DeepSeek V3 | 128K | - | |
| Kimi K2.5 | 256K | - | 长上下文特长 |
| GLM-5 | 200K | - | |
| MiniMax M2.5 | 200K | 架构支持 1M | |
| Qwen 3.5 | 256K | 1M(Plus 版本) |
当对话 Token 累积接近或超过上下文窗口时,模型需要某种策略来处理。以下是常见的 6 种方式:
| 处理方式 | 说明 | 适用场景 |
|---|---|---|
| 自动截断 | 丢弃最早的消息,保留最近的 | 简单聊天场景 |
| Auto-compact | 自动压缩/总结历史对话 | Claude Code 等开发工具 |
| 滑动窗口 | 保留最近 N 轮对话,丢弃更早的 | API 调用常见策略 |
| 摘要压缩 | 将历史对话总结为摘要,替换原文 | 长对话场景 |
| 手动分段 | 用户主动开启新会话,手动传递上下文 | 复杂任务、精确控制 |
| RAG 检索 | 历史存入向量库,按需检索相关内容 | 企业级应用 |
不同产品和 API 采用的策略不同。以开发者常用的 Claude Code 为例,它采用了一套多层递进压缩策略(参考 learn-claude-code 项目的解析):
[Previous: used read_file]),不需要调用模型,纯规则替换这套"先规则替换、再模型摘要"的递进设计,在不丢失关键信息的前提下尽可能延长了可用的对话长度。对于 API 开发者来说,滑动窗口和摘要压缩是最常用的两种方案,可以根据业务场景灵活选择。
大模型 API 的计费很直接:按 Token 数量收费,输入和输出分开计价。
为什么输出比输入贵?因为输入阶段是并行处理(模型一次性读取所有 Token),而输出阶段是逐个 Token 生成,每一步都需要独立的推理计算。通常输出价格是输入的 3-5 倍。
计费单位统一为每百万 Token($/MTok 或 ¥/MTok)。
| 模型 | 输入 ($/MTok) | 输出 ($/MTok) | 上下文 | 特点 |
|---|---|---|---|---|
| Claude Opus 4.6 | $5 | $25 | 1M | 最强能力,全窗口统一价 |
| Claude Sonnet 4.6 | $3 | $15 | 1M | 平衡之选,全窗口统一价 |
| GPT-5.4 | $1.75 | $14 | 272K / 1.05M | >272K 加价 2x / 1.5x |
| GLM-5 | 参见官方定价 | - | 128K | 近期涨价 30%+ |
| Kimi K2.5 | $0.45 | $2.20 | 256K | 缓存命中率高达 90% |
| MiniMax M2.5 | $0.30 | $1.20 | 1M | 仅 Claude Opus 的 1/63 |
| DeepSeek V3 | $0.28 | $0.42 | 128K | 极致性价比 |
差距有多大?用 Claude Opus 处理 100 万 Token 输出需要 0.42——相差近 60 倍。当然,能力和价格往往成正比,选型要看具体场景。
Prompt Caching(提示缓存)
大部分平台支持缓存重复的输入内容(如系统提示词)。缓存命中时,该部分 Token 可享受最高 90% 折扣。如果你的应用有固定的系统提示词,这是最直接的省钱方式。
Batch API(批量接口)
对于不需要实时返回的任务(如批量翻译、数据标注),使用 Batch API 可享受 50% 折扣。代价是响应时间从秒级变为分钟到小时级。
选择合适的模型层级
不是所有任务都需要最强的模型:
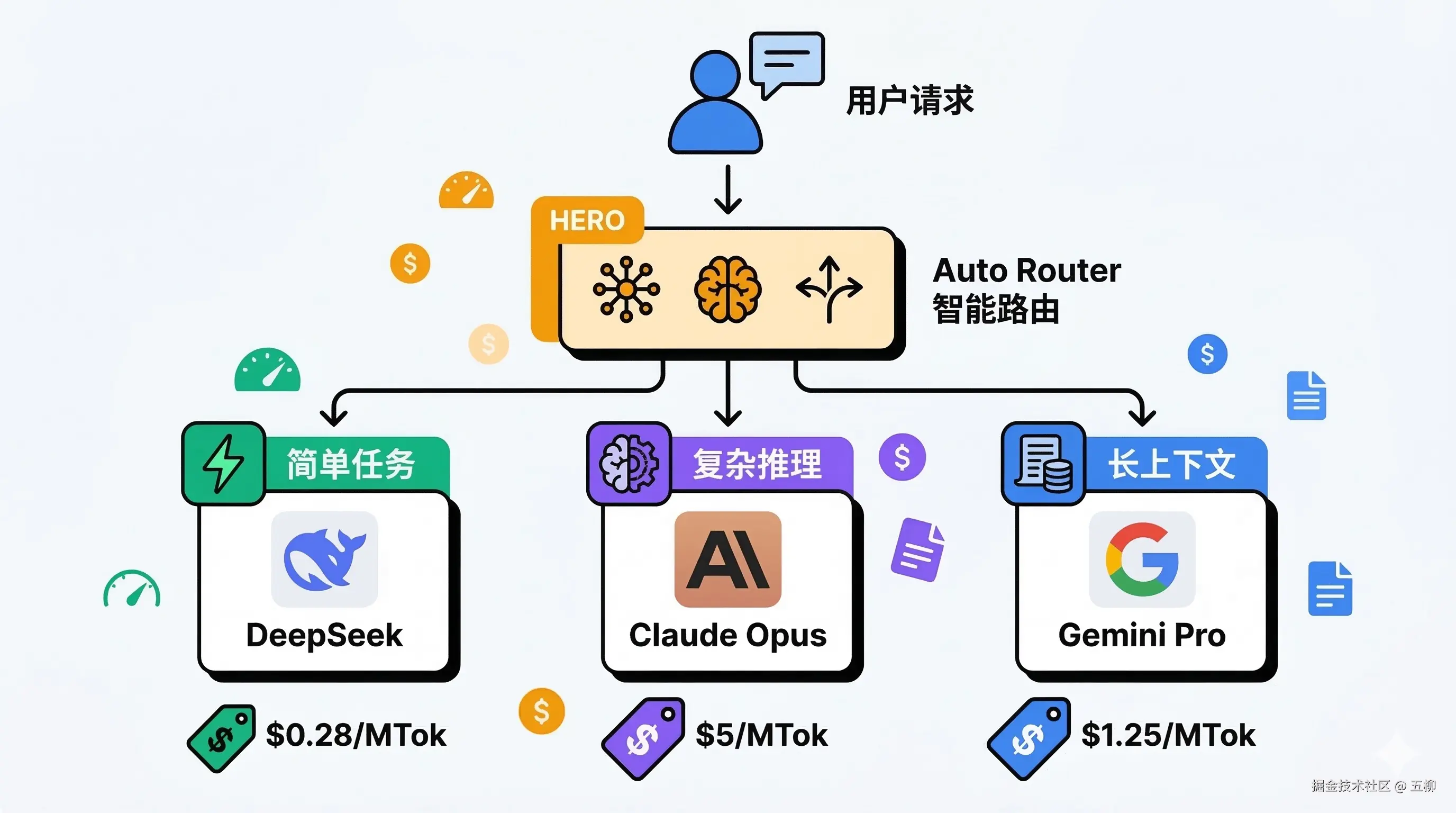
Auto Router(智能路由)
Auto Router 根据任务复杂度自动选择模型层级,让简单任务走便宜模型、复杂任务走强模型。Claude Code 社区有一个热门项目 claude-code-router(26.4k+ Star),可实现最高 80% 成本节省。
但 Auto Router 也有明显的缺点需要注意:
适合场景:对成本敏感、能接受偶尔质量波动的个人开发者或非关键业务。
使用大上下文窗口时,部分厂商会收取溢价:
| 厂商 | 阈值 | 超出后定价 |
|---|---|---|
| Anthropic (Claude 4.6) | 无阈值 | 全窗口统一价格(2026.3.13 起) |
| OpenAI (GPT-5.4) | >272K | 输入 2x,输出 1.5x |
| Google (Gemini) | >200K | 2x |
Claude 4.6 取消长上下文加价是一个重要变化。 此前使用超长上下文往往意味着额外的成本,现在 Claude 的 1M 全窗口统一定价,意味着你用 10K Token 和用 900K Token 的单价完全一样。对于需要处理大量代码、长文档的开发者来说,这是实实在在的成本优势。
选模型不能只看厂商宣传。以下是值得参考的权威评测资源:
什么是 Benchmark?
Benchmark 是标准化的测试集,用来量化模型在特定任务上的能力。常见的有:
推荐的评测站点:
| 类型 | 站点 | 说明 |
|---|---|---|
| 综合评测 | Artificial Analysis | 综合评分、价格、速度、延迟一站式对比 |
| 综合评测 | LM Council | 多维度 Benchmark 对比 |
| 综合评测 | LLM Stats | 排行榜汇总 |
| 代码能力 | Vellum | 代码能力专项评测 |
| 代码能力 | SWE-Bench | 软件工程能力评测(官方) |
对于开发者最关心的编程能力,以下是 SWE-Bench 榜单的关键数据:
| 模型 | SWE-Bench Verified | 编程特点 |
|---|---|---|
| Claude Opus 4.6 | 80.8% | 代码质量高,Agent 能力强,擅长复杂重构 |
| MiniMax M2.5 | 80.2% | 性价比极高,性能接近顶级但价格仅为 1/60 |
| GPT-5.4 | 77.2%* | 生态成熟,IDE 插件丰富,Computer Use 能力强 |
| GLM-5 | 77.8% | 逻辑推理强,中文编程场景友好 |
| Kimi K2.5 | 76.8% | 多模态能力突出,可根据截图生成代码 |
| DeepSeek V3.2 | 73.0% | 开源标杆,可本地部署 |
数字只是一部分。在实际使用中,Claude 在长上下文代码理解和 Agent 工作流方面表现突出;GPT-5.4 的核心升级在 Computer Use 和工具调用方向,编码能力较 5.2 有小幅提升;DeepSeek 作为开源模型可以本地部署,适合对数据隐私有要求的场景。
不要问"哪个模型最好",要问"哪个模型最适合我的场景"。以下是一些常见场景的选型思路供参考:
编程场景
长文本处理
极致性价比
以上仅为示例,模型迭代速度很快,建议结合前文的评测站点查看最新排名,再做决策。
没有"最好"的大模型,只有"最适合"的。
选型的思路是三步走:先明确场景(编程、对话、翻译、图像?),再看 Benchmark(用第三方评测站验证能力),最后算成本(Token 单价 × 预估用量)。
AI 领域的竞争正在让模型更强、价格更低。保持关注,定期重新评估你的选型——今天的最优选择,明天可能就不是了。
| 类型 | 站点 | 链接 |
|---|---|---|
| 综合评测 | Artificial Analysis | artificialanalysis.ai/leaderboard… |
| 综合评测 | LM Council | lmcouncil.ai/benchmarks |
| 综合评测 | LLM Stats | llm-stats.com/leaderboard… |
| 代码能力 | Vellum | www.vellum.ai/best-llm-fo… |
| 代码能力 | SWE-Bench | www.swebench.com/ |
| 厂商 | 链接 |
|---|---|
| Anthropic (Claude) | platform.claude.com/docs/en/abo… |
| OpenAI (GPT) | openai.com/api/pricing… |
| Google (Gemini) | ai.google.dev/gemini-api/… |
| 智谱 (GLM) | open.bigmodel.cn/pricing |
| 月之暗面 (Kimi) | platform.moonshot.cn/docs/pricin… |
| MiniMax | www.minimaxi.com/pricing |
| 阿里云百炼 (Qwen) | help.aliyun.com/zh/model-st… |
| 硅基流动 (国产聚合) | siliconflow.cn/pricing |
| 站点 | 链接 |
|---|---|
| AIGCRank | aigcrank.cn/llmprice |
| 硅基流动 | siliconflow.cn/pricing |
| 工具 | 说明 | 链接 |
|---|---|---|
| claude-code-router | Claude Code 智能路由,多 Provider 支持 | github.com/musistudio/… |

