锦书在线
80.52M · 2026-03-21

随着大模型能力的提升,越来越多的系统开始尝试使用 Agent 架构 来完成复杂任务,例如自动化运维、数据分析、代码生成等场景。
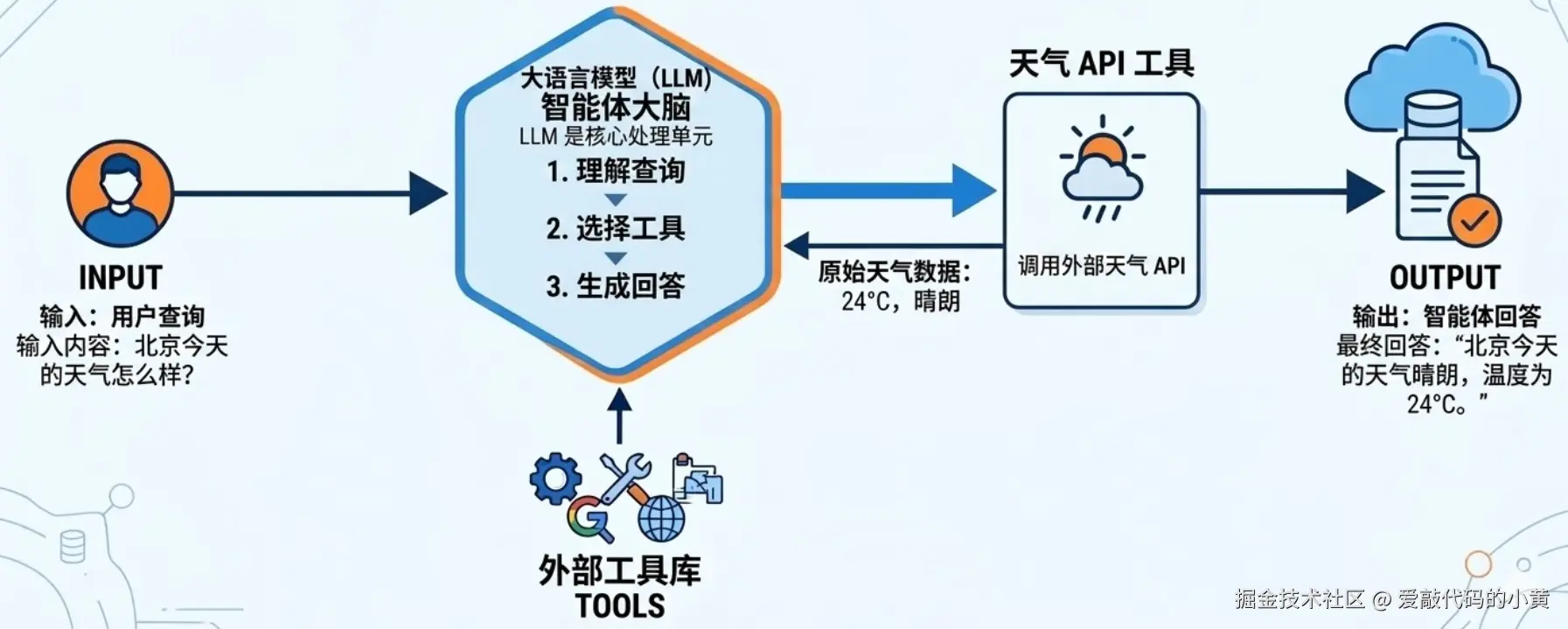
在最早期的 Agent 设计中,整体结构其实非常简单
在这种模式下,大模型通过 Tool Calling 的方式选择合适的工具,并根据工具返回结果继续推理,从而完成任务。
例如:
get_weatherrun_sqlsearch_docs这种方式在 工具数量较少时非常有效。但随着 Agent 能力不断增加,系统接入的工具越来越多,问题也逐渐开始显现。
在早期 Agent 系统中,通常只接入少量工具,例如:查询天气、查询数据库、搜索文档。大模型通过 Tool Calling 选择工具即可完成任务。
但在真实系统中,随着能力不断增加,Agent 往往会接入越来越多的工具,当工具数量从 几个增长到几十个甚至上百个 时:
很多真实任务并不是一次工具调用可以完成,而是包含多个步骤,并且步骤之间存在依赖关系。
例如:规划一次五一n京旅行
查询车票
确定出行时间
预订酒店
查询景点
规划每日行程
生成旅行计划
这些步骤存在明显依赖,例如:
因此,大模型不仅要选择工具,还需要推理 执行顺序和依赖关系。
当工具数量和任务步骤增加时,这种推理难度也会迅速上升。
当 工具规模不断增长、任务复杂度不断提升 时,Agent 系统需要一种方式来管理这些能力。
在传统软件工程中,我们通常通过模块化来控制复杂度,例如:函数、模块、微服务
Agent 系统同样需要类似机制,将复杂能力拆分为 可管理、可复用的能力模块。例如:旅行规划、日志分析、SQL优化、文档生成
在这样的背景下,Skill 作为能力模块化的机制逐渐出现。
Skill 是 Agent 的一个能力单元,用于封装完成某一类任务所需的逻辑和资源。
与单个 Tool 不同,Skill 描述的是一类 完整能力或任务流程。在执行过程中,Skill 可以根据需要调用多个 Tool,并组织它们完成任务。
在 Agent 系统中,Agent 会根据用户问题选择合适的 Skill,然后由 Skill 负责组织具体的工具调用与任务执行。
因此可以简单理解为:
从系统结构上看,Skill 是 Agent 的能力模块,用于将复杂任务组织为可复用的执行流程。
在 Anthropic 的设计中,一个 Skill 通常以 目录的形式组织,用于封装完成某一类任务所需的说明、知识和执行资源。
一个典型的 Skill 结构如下:
skill/
├── SKILL.md
├── references/
└── scripts/
通过这种结构,Skill 将能力描述、知识资源和执行逻辑统一封装,从而形成可复用的能力模块。
在 Agent 系统中,Skill 和 Tool 扮演不同角色。
从系统结构上看:
Skill 通过组合多个 Tool,从而完成更复杂的任务。
Skill 在 Agent 中的执行通常包含三个阶段:选择、加载和执行。
为了更清晰地说明 Skill 的执行流程,我们以一个典型的 xiaohongshu_publish Skill 为例
xiaohongshu_publish/
├── SKILL.md
├── references/
│ └── style-examples.md
└── scripts/
└── publish_xiaohongshu.py
└── save_xiaohongshu_payload.py
接下来,我们基于这个 Skill 来说明其在 Agent 系统中的执行流程。
当 Agent 接收到用户请求时,需要从可用的 Skill 中选择最合适的一个。
通常情况下,Agent 会根据用户问题与 Skill 的 name 和 description 进行匹配,从而判断是否需要使用该 Skill。
例如,一个 xiaohongshu_publish Skill 的基本信息可能如下:
---
name: xiaohongshu
description: 将用户输入的任意中文内容改写为成小红书风格文案,输出吸引点击的标题、有节奏的正文和话题标签。适用于用户要求“改;支持先提炼生成小红书风格”“写种草文案”“写小红书笔记”“优化稿,再通过独立发布脚本调用发布接口分享内容”等场景。
---
实际系统中,Skill 的选择通常分为两个阶段:
Skill 不会一次性加载全部资源,而是采用 按需加载 的方式。Agent 通常会先读取 SKILL.md 中的能力说明和执行规则,以理解该 Skill 的整体能力。
xiaohongshu_publish/
├── SKILL.md
├── references/
│ └── style-examples.md
└── scripts/
└── publish_xiaohongshu.py
└── save_xiaohongshu_payload.py
在这一阶段,Agent 会优先读取 SKILL.md。只有在任务确实需要时,才会进一步读取 references/ 中的内容,或选择性执行 scripts/ 中的脚本。
这种方式被称为 渐进式加载(Progressive Disclosure),可以避免一次加载大量无关信息,从而降低上下文复杂度并提升推理效率。
需要注意的是,scripts/ 中的脚本并不一定都会执行。根据任务流程的不同,脚本既可能在大模型生成前执行,也可能在生成后执行。例如在小红书发布任务中,发布脚本和保存脚本通常会在内容生成之后执行,而其他脚本则可能用于生成前的数据准备。
在完成 Skill 的选择和加载之后,Agent 会按照 SKILL.md 中定义的规则执行该 Skill。
在执行过程中,Agent 可能会读取 references/ 中的内容作为上下文,并根据任务需要调用 scripts/ 中的脚本完成具体操作。
例如在小红书发布任务中,Agent 会先根据参考示例生成小红书内容,然后调用 publish_xiaohongshu.py 脚本将内容发布到平台,同时通过 save_xiaohongshu_payload.py 保存生成结果。
通过这种方式,Skill 将大模型能力与外部工具结合起来,从而完成完整的任务执行。
每个 Skill 应当只负责一类明确的能力,而不是同时承担多个不相关的任务。
Skill 的粒度需要保持适中。
例如:
Skill 中的资源应尽量按需加载,而不是一次性全部提供给模型。
例如:
SKILL.md 用于描述能力references/ 存放参考资料scripts/ 提供执行脚本这种设计可以减少上下文长度,并提升推理效率。
Skill 负责组织任务流程,而 Tool 或 Script 负责具体执行。
通过这种方式,可以将能力逻辑与具体执行实现解耦,从而提升系统的灵活性和可维护性。
Skill 为 Agent 提供了一种能力模块化的方式,使复杂任务能够被拆分为可管理、可复用的能力模块。
通过 Skill 的结构化组织和渐进式加载机制,Agent 可以在保持能力扩展性的同时,避免上下文膨胀的问题。
在实际系统中,Skill 已成为连接大模型能力与外部工具的重要桥梁。
但从技术发展的角度来看,Skill 很可能只是当前阶段的一种工程实现。随着大模型能力的持续提升,未来可能会出现更加自然的能力组织方式,例如由模型直接理解和调用能力接口,或通过更智能的任务规划与能力路由机制来组织各种能力。
某种意义上看,Skill 更像是 Agent 时代的函数封装。而未来的 Agent 系统,也许会像操作系统一样,通过更加动态的能力调度机制来管理这些能力。至于最终会演进成什么形态,现在还很难确定,但可以确定的是,让 Agent 更高效地组织能力、完成复杂任务,仍然是这一领域持续探索的重要方向。

