锦书在线
80.52M · 2026-03-21

内容有些长,耐心看完,对你应该有所帮助
在自然语言处理中,"Embedding" 通常翻译为嵌入,指将离散数据(如单词、图像)映射到连续向量空间的技术。
简单来说,Embedding 就是一个**从离散数据到高维连续向量空间的映射函数。**想象一下,我们将每一个词、每一段话映射到 空间(比如 或 )。在这个空间里,语义相近的文本,其向量位置也会非常接近。
当我们把文本变成向量后,如何判断“Pinia”和“Vuex”在语义上是相关的呢?主要靠这两个数学工具:
余弦相似度 (Cosine Similarity) :
它衡量的是两个向量之间夹角的余弦值。公式如下:
特点:它只看方向,不看长度。在 NLP 中最常用,因为文档的长短(向量模的大小)不应影响它表达的主题语义。
点积 (Dot Product) :
特点:如果向量已经经过了归一化(模为1),点积就等于余弦相似度。很多高性能向量数据库(如 Milvus)会通过归一化来把复杂的余弦计算简化为点积运算,以提升搜索速度。
总结:
通俗定义:把一段话变成一串数字坐标。
核心逻辑:在 AI 的世界里,相似的词会靠在一起。比如“西瓜”和“哈密瓜”在坐标系里的距离,肯定比“西瓜”和“波音747”要近。
数学必记:余弦相似度。它不看你话有多长,只看你们聊的是不是一个方向。
既然你已经掌握了相似度度量,我们要解决下一个现实问题:速度。
如果你有 1 亿条文档向量,用户问一个问题,你用余弦相似度跟这 1 亿条数据逐一计算(暴力搜索),那用户可能要等半天。
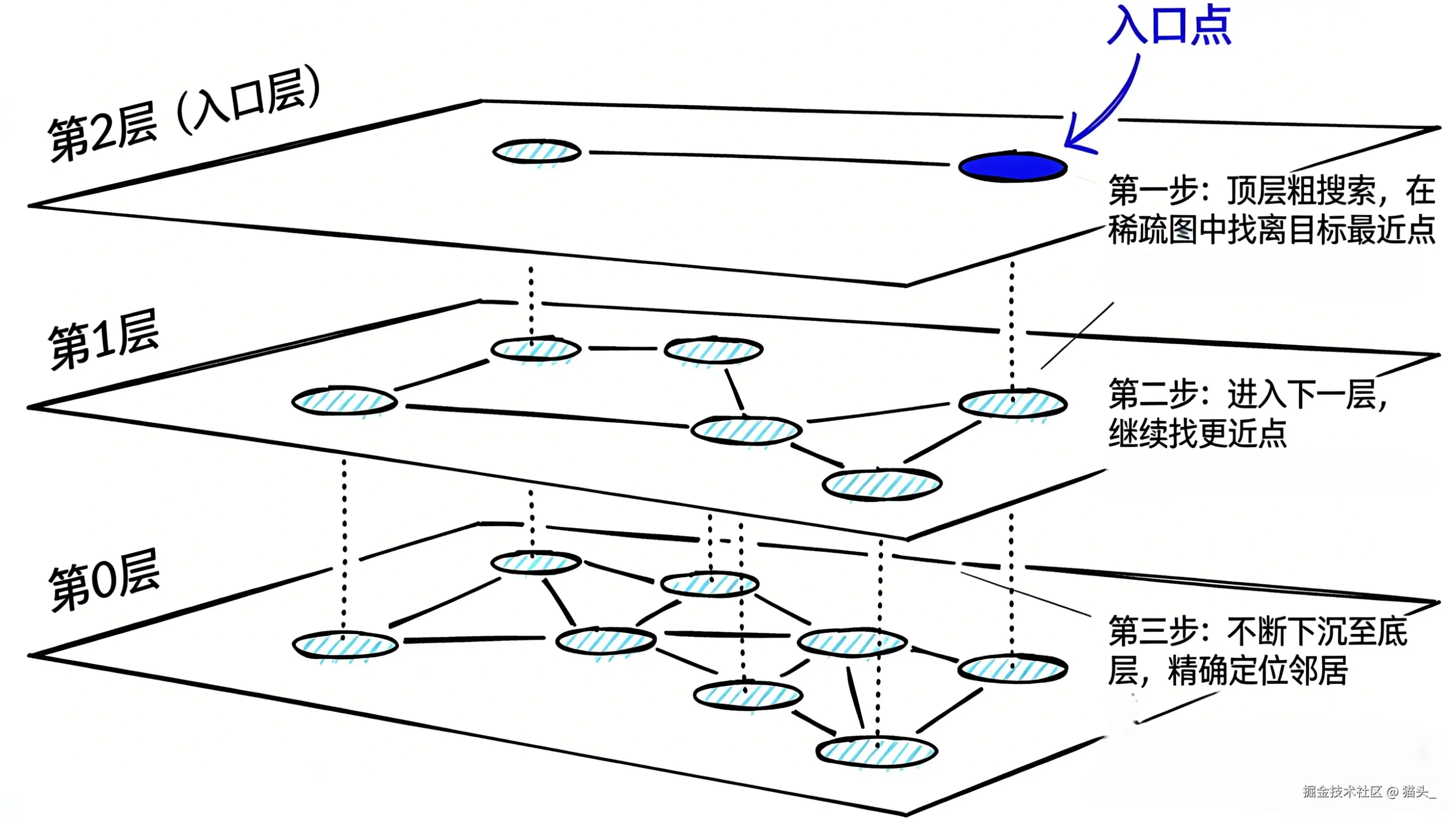
为了实现毫秒级响应,我们需要 HNSW (Hierarchical Navigable Small World) 。
为什么使用分层存储的模式,是遇到什么困难了?
HNSW 的实现基础是多层图结构(Layered Graph):
注意: 当你锁定了底层最相似的向量后,每个向量其实都对应着数据库里的一个指针,指向一段具体的文字(文本块)。
HNSW 输出: “离你最近的知识点是编号为 #1024, #2048, #512,#1314 ……的文本块。”
系统操作: 从数据库取出这几段话。
提问:结构与搜索都有了,那么如何存储?
插入一个新向量 的步骤如下:
A. 确定层数 使用指数概率分布确定新节点的最高层
大部分点都只在第 0 层,极少数点能到达高层。
B. 寻找邻居 从顶层下降到第 层时,只进行简单的贪婪搜索,找到最接近 的进入点。 从第 层下降到第 0 层时,在每一层都会寻找与 最近的 个邻居并建立连接。
C. 启发式连接 (Heuristic Selection) 这是 HNSW 的精髓。在选择邻居时,它不只是简单选择最近的 个点,而是采用多样化策略:
如果候选邻居 虽然离 很近,但 已经和 的另一个邻居 非常接近了,那么 HNSW 可能会放弃连接 ,转而连接稍微远一点但在不同方向上的 (类似:发散思维)。 这样可以保证图的连通性更广,防止搜索陷入孤立的簇。
即使你不提供 HNSW 数据库(或任何外部知识库),AI 依然可以和你对答如流。
1. 核心差异:参数化内存 vs. 非参数化内存
不带数据库(原生 AI): 依靠 参数化内存 (Parametric Memory) 。
带数据库(HNSW/RAG): 依靠 非参数化内存 (Non-parametric Memory) 。
两种模式的优缺点对比
| 特性 | 原生 AI(不带数据库) | AI + HNSW 数据库(RAG 模式) |
|---|---|---|
| 知识来源 | 训练时的陈旧数据(有截止日期) | 实时、私有、最新的外部数据 |
| 准确性 | 容易幻觉(一本正经胡说八道) | 极高(有据可查,不乱编) |
| 隐私性 | 无法访问你的本地私有文档 | 可以检索并处理你的私有文档 |
| 响应速度 | 极快(直接输出) | 稍慢(需要多出一步检索时间) |
| 可追溯性 | 无法告诉你答案在哪看到的 | 可以告诉你“根据文档 A 第 3 页显示...” |
AI为什么还需要数据库?
既然 AI 自己懂这么多,为什么我们还要费劲搞 HNSW 数据库?
所以,当你直接和 AI 交互时,你是在用它的“脑子”;当你给它配上 HNSW 数据库时,你是给了它一套“无穷无尽的书架”。
总结:
笔记要点:
简单来说:递归字符切分是“看长相”来切(物理结构),语义切分是“看意思”来切(逻辑内容)。
递归字符切分 (Recursive Character Splitting)
这是最常用的方式,它会先按段落分,段落太长再按句子分,句子太长再按空格分。
这是目前最常用、性价比最高的方案(比如 LangChain 里的 RecursiveCharacterTextSplitter)。
工作原理:
它并不是暴力地每 500 字一刀,而是拿着一组分隔符清单去递归尝试。典型的顺序是:
nn(双换行,通常是章节/段落)。n(单换行)。.(句号)。""(实在分不开了,就按单个字符切)。它的逻辑:
nn 切。如果切出来的块还是超过了你设定的 chunk_size,它就在这个块内部改用 n 切,以此类推。语义切分 (Semantic Chunking)
这种方法不看回车或句号,它看的是内容的意思。
工作原理:
它的逻辑:
深度对比:你应该怎么选?
| 特性 | 递归字符切分 (推荐入门) | 语义切分 (进阶首选) |
|---|---|---|
| 判断标准 | 物理符号(换行、标点) | 语义相似度(Embedding) |
| 计算开销 | 极低。只是简单的字符串处理。 | 高。每一句都要调一次模型算向量。 |
| 准确度 | 较好,能保留段落完整性。 | 极佳。每个块都是一个独立的“知识主题”。 |
| 缺点 | 依然可能把一个跨段落的长逻辑切断。 | 慢,且依赖 Embedding 模型的质量。 |
| 适用场景 | 通用文档、格式规整的代码、说明书。 | 逻辑复杂、跳跃性大的专业论文或对话记录。 |
开发建议
在实际做项目时,建议是:
先从“递归字符切分”开始:
设定 chunk_size: 500,chunk_overlap: 50(后面会说)。这能解决 80% 的问题,而且运行飞快,不需要花钱调模型。
遇到疑难杂症再用“语义切分”:
如果你发现 AI 总是“断章取义”,或者你的文档逻辑特别碎片化,再考虑引入语义切分。
笔记要点:
问题:如果你设置 Chunk Size(切块大小)太小(比如只有 20 个字符),或者太大(比如 20000 个字符),分别会导致什么后果?
1. 如果切得太小(例如:每句一词)
2. 如果切得太大(例如:整章切分)
解决方案:滑动窗口(Overlap)
为了解决“切太小丢上下文”的问题,工业界标准做法是设置 Overlap(重叠度) 。
关于“Overlap 10%”的精妙之处
笔记要点:
运行这个AI前,我们将历史数据切块向量化,本体存储在 向量库(文件切片部分+文件切片overlap10%),向量坐标在向量库(HNSW部分),
用户提问→ 转化为向量 → 去HNSW找到最近的向量获取地址 →根据地址去获取向量库的存储数据内容 → 再根据内容去一起写成prompt交给AI → AI处理发送答案
| 描述 | 技术术语 | 核心要点 |
|---|---|---|
| 切块并留 10% Overlap | Text Chunking | 10% 的重叠是为了防止“语义断裂”(比如一句话被切成两半,通过重叠可以保留上下文)。 |
| 本体存储在向量库 | Document Store | 这部分通常是磁盘上的 KV 数据库,负责存“沉甸甸”的文字。 |
| 向量坐标在 HNSW 部分 | Vector Index | 这部分是内存里的“路标”,专门负责算数学距离。 |
| 根据地址获取内容 | Metadata Fetching | 通过向量 ID(你说的地址)秒杀回传对应的原始文本。 |
| 写成 prompt 交给 AI | Context Injection | 把搜到的“知识”塞进 AI 的输入框,这叫“上下文注入”。 |
假设你是个前端开发者,你在写一个 AI 助手,整个链路是这样的:
"植物为什么需要阳光"Top 1 ID: 9527。9527 迅速从磁盘/缓存中抓取文本:"光合作用是植物..."。疑问?:Prompt 是怎么“拼”的?
提到的“一起写成 Prompt”,在代码底层通常长这样:
离线阶段(预处理) :
在线阶段(查询) :
希望能帮到你

