锦书在线
80.52M · 2026-03-21

最近 Cursor 发布了它内部使用的评测体系 CursorBench 报告,用来衡量 AI coding agent 的真实工程能力,它做 CursorBench 主要是因为:
官方的原话是:
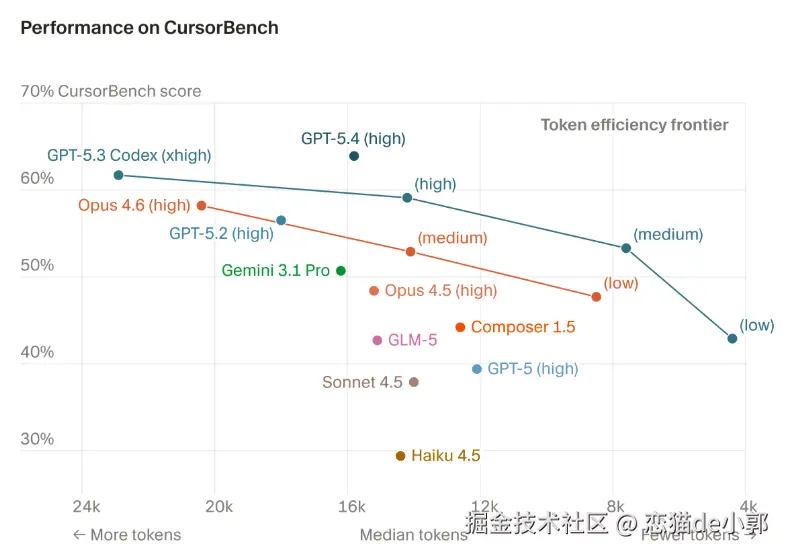
例如这里展示的是 CursorBench 结婚图:
对于 CursorBench 来说,它评估维度会比 SWE-bench 多 :
| 维度 | 含义 |
|---|---|
| correctness | 是否能完成任务 |
| code quality | 代码是否符合工程规范 |
| efficiency | token / steps / retries |
| interaction | agent行为是否合理 |
最重要是,Cursor 是中间商,它相对会更加中立一点点(虽然它自己也开始做 Composer),毕竟现在公开的 Bench 是越来越没有说服力了,测试方向本身就不贴合实际场景,像一些 Terminal-Bench 也是在做一些宽泛的解谜式任务,例如从棋盘位置找出最佳的国际象棋走法这些,实际上是和 Agent 要执行的 Coding 任务根本不匹配。
而 CursorBench 的设计思想也和现在新的主流的差不多,主要是用真实开发任务,而不是合成任务 ,例如:
在这里,Cursor 使用 Cursor Blame 给 CursorBench 补充任务,Cursor Blame 可以将已提交的代码追溯到生成该代码的Agent 请求,从而能够自然地将开发者查询和真实解决方案配对,这里的许多任务来自 Cursor 的内部代码库和受控来源,从而降低了模型在训练过程中接触到这些任务的风险,特别是每隔几个月更新一次任务套件,方便跟踪开发者使用 Agent 变化。
对比 SWE-bench 的 GitHub issue/patch 下的自动验证流程,CursorBench 采用 IDE Agent 下的多轮交互,修改多个文件路径,覆盖 terminal / tool / search 等场景,还评测了 context 管理等。
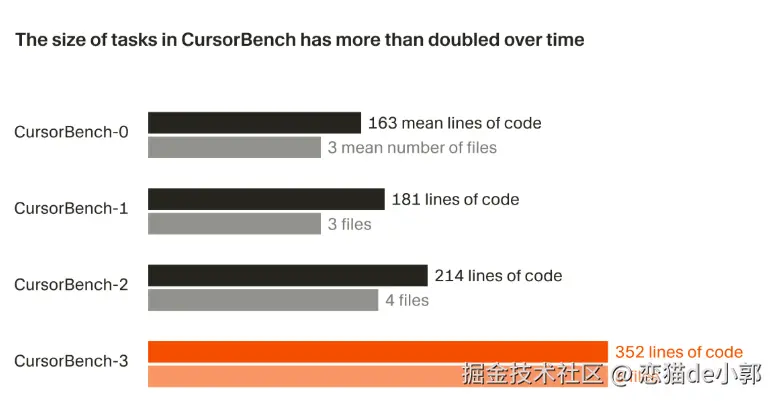
从初始版本到现在的 CursorBench-3 版本,正确性评估中的问题范围大约翻了一番,无论是代码行数还是平均文件数都显著增加,也就是 CursorBench-3 的任务涉及的代码行数远超 SWE-bench Verified、Pro 或 Multilingual :
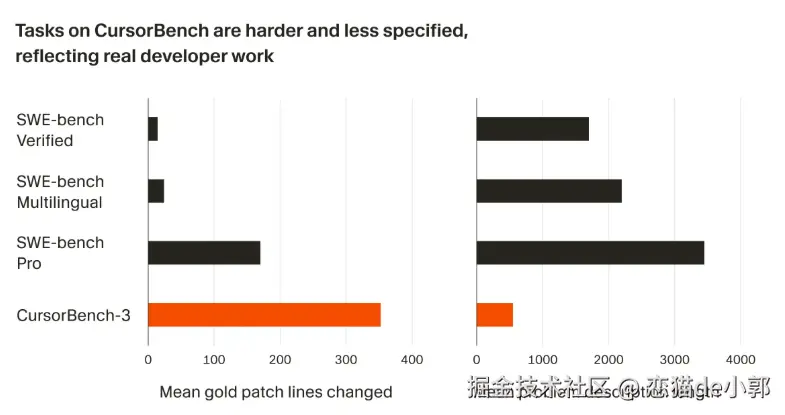
虽然代码行数不是衡量难度的完美指标,但这个指标的增长也反映了任务的复杂度在提升,例如处理具有仓库的多工作区环境、分析生产日志和执行长时间运行的实验。
最重要的是,CursorBench 任务也符合开发者与 Agent 之间沟通时常存在的规范不足、含糊不清的特点,和其他相比更贴近真实场景:
因为现在的 coding AI 本来就是不只是模型,我也说过很多次,模型本身确实很重要,但是 harness 环境也很重要,现在的 AI 开发,本来就是 model + tools + planner + memory 的集合体,所以单讨论模型本身意义不大,例如 Cursor 也说了:
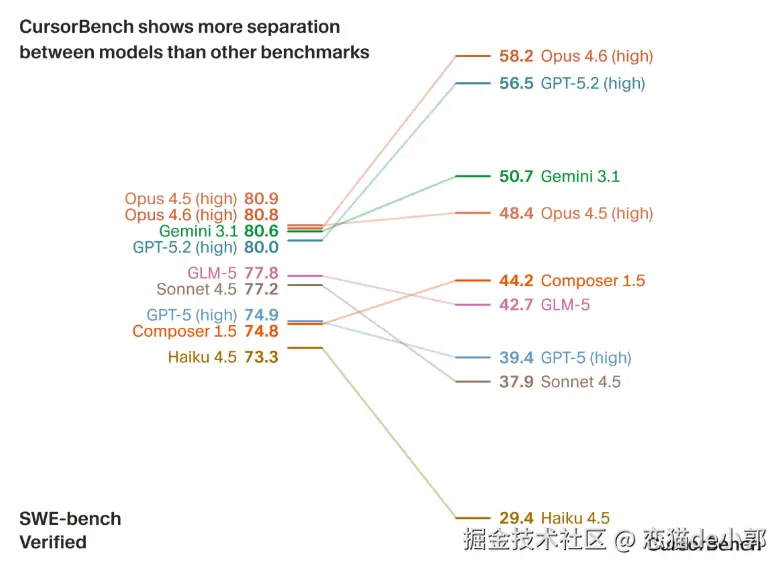
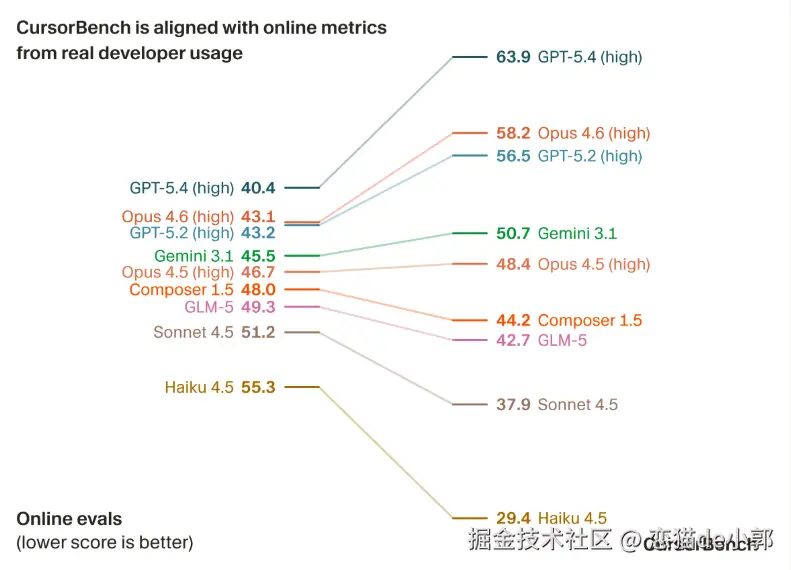
任务复杂度和前面说的这些差异,对基准测试的实用性产生的影响很大,比如在某些情况下,像 Haiku 这样的模型甚至可以达到或超过 GPT-5 的性能,但是对比右边 CursorBench 就结果就很明显了:
最后,前面说了那么多废话,这里直接看结果:
在这个结果上,Cursor 证明了 CursorBench排名 ≈ 真实使用排名 ,而结果确实也趋势基本一致,在线越好的模型场景, CursorBench 也高。
当然,因为是内部流程,也是为了防止污染, CursorBench 完全不公开,它是一个闭源测试项目,所以你无法复现和验证,另外因为是内部任务,也存在模型容易过拟合,例如:用 Cursor 训练但室又用 Cursor 评测 。
所以它最多是证明了模型在 Cursor 下哪个更好用,性价比更好,不代表这个模型在其他场景下的能力,还是那句话,harness 很重要,比如你在 opencode 里用 Claude ,大概体验不出 Claude 的好。
所以,如果你还用 Cursor ,那这个文章就有比较高的参考意义,如果我选择的话,codex-5.3 medium 就是一个性价比还可以的选择。
cursor.com/blog/cursor…

