闪电疯狂赛车
91.44M · 2026-03-23

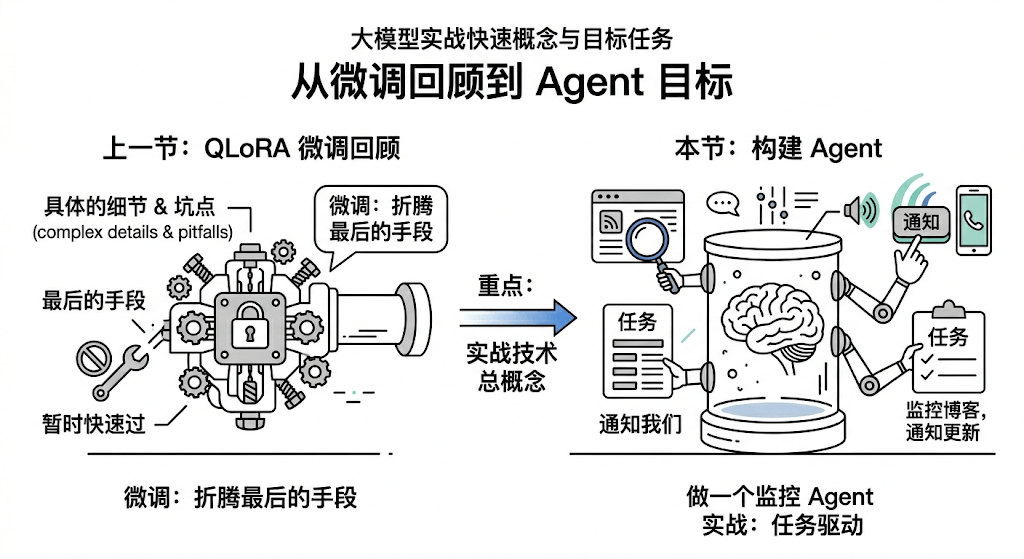
各位友人们好啊,在上一节我们快速了解了QLoRA微调技术,进行了一个简单的模型认知微调。微调可以说是咱们在折腾的最后的手段,其具体的细节和坑点都有很多可以细讲,但是由于篇幅所限,咱们暂时这是快速过一下,之后有机会可以再单开一个专栏去做微调,咱们目前的重点还是对整个大模型的实战技术有个总的概念。
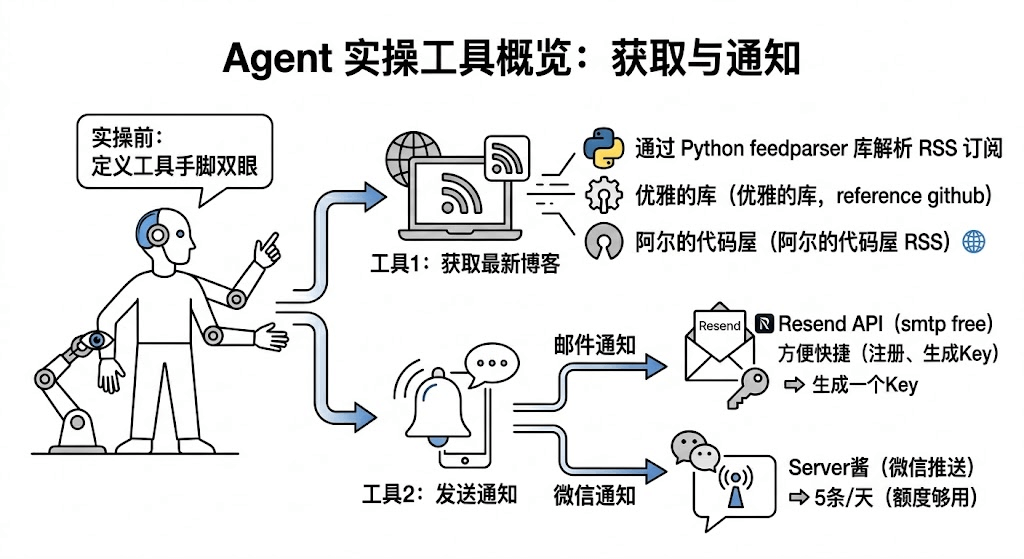
好嘞,废话不多话,这节咱们来做个Agent, 来帮咱们干点活儿,任务驱动起来,咱们学得也更愉快一点,更有目标一点。 本篇博客的目的:做一个监控博客更新,并且可以通知咱们更新的Agent。
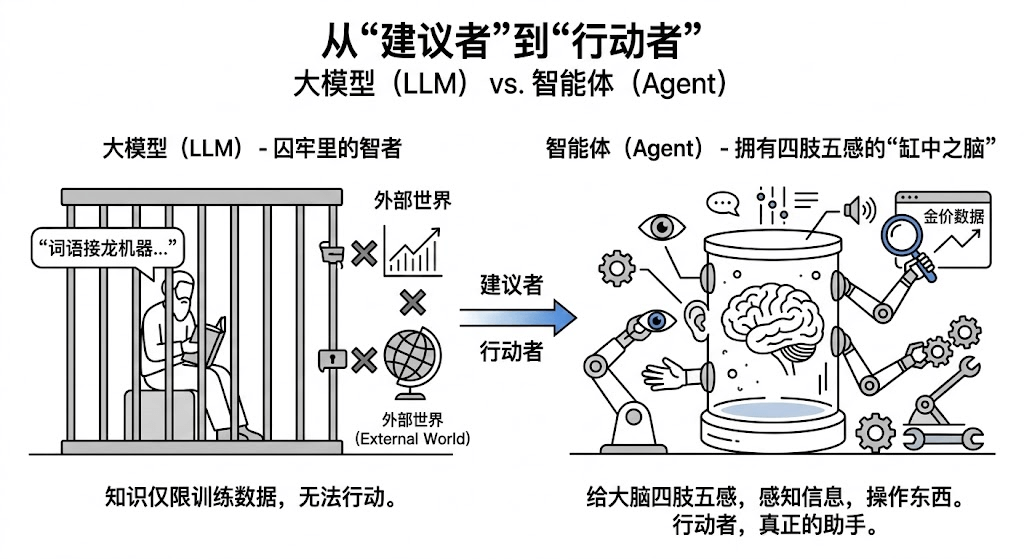
通过前面的博客,我们知道,大模型其本身只是拥有训练时数据的知识的词语接龙机器,换一个形容的话,就像是一个被关在囚牢里的智者,对外界无所知,也无法改变外界。如果我们想让它写写文章,讲讲笑话,还在其能力之内,如果我们想让它去帮我们去查一下今天的金价,它就只能回答“抱歉,作为一个对话大模型,我没有上网的能力”,或者直接开始瞎编。 而对于Agent,或者说智能体,我们给这颗“缸中之脑”四肢五感,让它能去看到信息,能操作一些东西。它就能从一个“建议者”变成“行动者”成为一个真正能干活儿的助手。
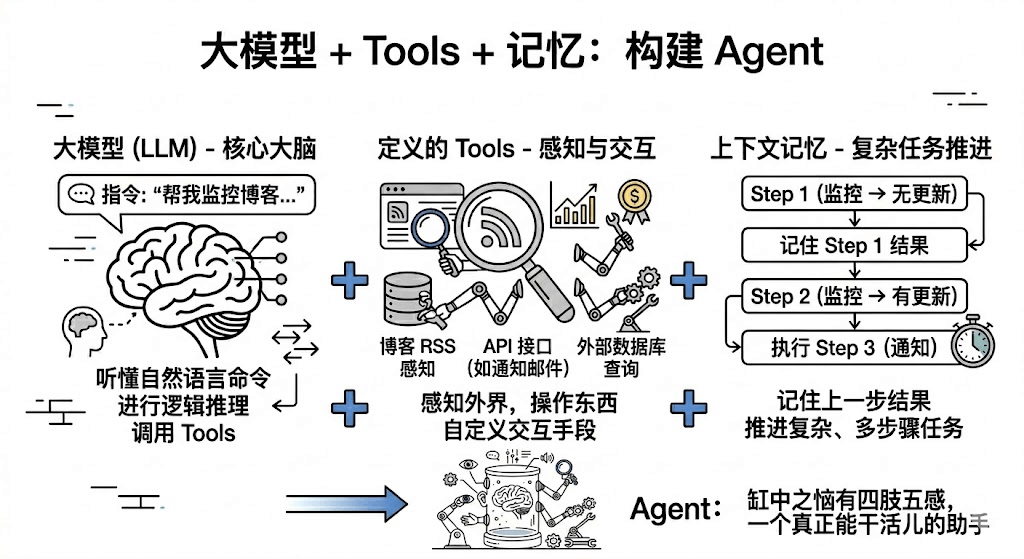
Agent = 大模型(大脑)+ 定义的Tools(手脚双眼)+ 上下文记忆
大模型:大模型作为Agent的核心,其负责听懂自然语言命令,也就是咱们的指令,进行逻辑推理,去调用Tools
Tools: Tools则是咱们为Agent定义的与外界交互的手段,对这个需要咱们去自己定义,当然也有别的法子。
上下文记忆:这是为了推进复杂任务,很多时候其需要记住上一步的结果,根据结果进行第二步。
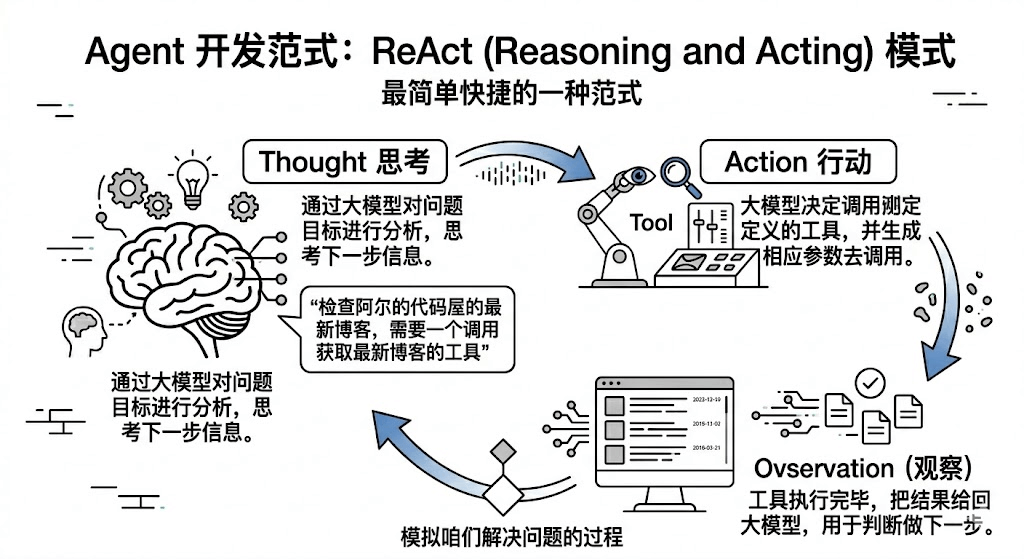
Agent的开发也有很多范式,咱们今天来用最简单快捷的一种ReActAgent模式。
ReAct,全称是Reasoning and Acting,从字面上看就是“推理” + “行动”的Agent模式。这种范式最简单,因为它是模拟咱们解决问题的过程:
在开始实操之前,因为咱们知道对这个任务来说,咱们需要至少两个工具:
!pip install uv
!uv pip install feedparser llama-index requests llama-index-llms-huggingface
!uv pip install -U transformers peft accelerate bitsandbytes
!uv pip install --reinstall torch torchvision torchaudio --index-url --system
由于kaggle默认的transformers库有点老了,咱们也直接给它升级上去,然后完成安装之后,一定要点击重启并清理(Restart & clear all cell outputs),来让新的库进入环境使用,否则还是使用的旧有的库。
我们在之前注册的用于发送通知的Api Key,属于隐私资产,咱们不能直接写在代码中,需要用密钥的方式加到环境中
EMAIL_API_KEY,在VALUE中填上咱们在Resend获取的Api keyWECHAT_API_KEYTARGET_EMAIL配置完毕之后,需要确认是否新加的这几个Secrets都勾选上了,这里添加了之后,在别的项目中,咱们也可以通过勾选他们去激活,这些secrets是项目间可见的。
另外Kaggle也给出了获取这些Secrets的代码示例
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_value_0 = user_secrets.get_secret("EMAIL_API_KEY")
secret_value_1 = user_secrets.get_secret("TARGET_EMAIL")
secret_value_2 = user_secrets.get_secret("WECHAT_API_KEY")
待会儿咱们会用到
import feedparser
def get_latest_blog_post(rss_url:str)->str:
"""
用于请求并解析目标博客的 RSS feed,获取最新的一篇博客文章信息。
当咱们需要检查博客是否有更新时,必须首先调用此工具。
"""
print(f"【calling】 get_latest_blog_post with rss_url:{rss_url}")
try:
feed = feedparser.parse(rss_url)
if feed.entries:
latest_entry = feed.entries[0]
print(f"debug: title {latest_entry.title} link:{latest_entry.link}")
return (
f"Title: {latest_entry.title}n"
f"Link: {latest_entry.link}nn"
"【系统强制指令】:请立刻将上面的 Title 与咱们已知最新标题进行严格比对!n"
"情况 A:如果 Title 与已知标题【完全相同】,请直接输出 Answer: 无更新,结束任务。n"
"情况 B:如果 Title 与已知标题【不一致】,咱们绝对不能直接输出 Answer!咱们必须严格按以下格式输出,以调用通知工具:nn"
"Thought: 标题不一致,我必须立刻调用通知工具。n"
"Action: send_all_notificationsn"
"Action Input: {"post_title": "完全复制上面的Title", "post_link": "完全复制上面的Link"}n"
)
return f"No posts found in rss feed {rss_url}"
except Exception as e:
return f"Exception: {str(e)} on fetching blog"
代码通过feedparser去获取到最新博客的title和link,中间打印了一些信息方便后期调试确认,但是为什么return的时候返回了这么一大堆看起来像提示词的东西? 这里咱们卖个关子,在后面给大家解密。
咱们调用一下这个函数测试一下
get_latest_blog_post("https://blog.algieba12.cn/atom.xml")
结果如下, 可能各位友人看到博客的时候,最新的一篇已经不是这篇了,不过没问题,只要是能获取到最新一篇即可。
【calling】 get_latest_blog_post with rss_url:
debug: title 在 Kaggle 上用 Unsloth 极速微调 Qwen3 - 大模型实战 06 | 阿尔的代码屋 link:
'Title: 在 Kaggle 上用 Unsloth 极速微调 Qwen3 - 大模型实战 06 | 阿尔的代码屋nLink: nn【系统强制指令】:请立刻将上面的 Title 与咱们已知最新标题进行严格比对!n情况 A:如果 Title 与已知标题【完全相同】,请直接输出 Answer: 无更新,结束任务。n情况 B:如果 Title 与已知标题【不一致】,咱们绝对不能直接输出 Answer!咱们必须严格按以下格式输出,以调用通知工具:nnThought: 标题不一致,我必须立刻调用通知工具。nAction: send_all_notificationsnAction Input: {"post_title": "完全复制上面的Title", "post_link": "完全复制上面的Link"}n'
import requests
def send_email_notification(post_title:str, post_link:str)->str:
"""
当发现博客有更新时,必须调用此工具发送邮件通知。
参数 post_title: 新博客的标题
参数 post_link: 新博客的链接
"""
print(f"【calling】 send_email_notification with post_title {post_title} link {post_link}")
target_email= user_secrets.get_secret("TARGET_EMAIL")
email_api_key = user_secrets.get_secret("EMAIL_API_KEY")
headers = {
"Authorization": f"Bearer {email_api_key}",
"Content-Type": "application/json"
}
payload = {
"from" : "onboarding@resend.dev",
"to":target_email,
"subject":f"阿尔的代码屋更新咯:{post_title}",
"text":f"检测到 阿尔的代码屋 更新了一篇新博客 nn 标题:{post_title}]n 链接: {post_link}"
}
try:
response = requests.post("https://api.resend.com/emails", headers=headers, json=payload)
if response.status_code == 200:
return "Email sent successfully via API"
return f"Email sent failed. {response.text}"
except Exception as e:
return f"Exception: {str(e)} on sending email"
这里我们使用了之前Secret代码示例获取咱们的收信邮箱和api key,这里需要注意一下,from字段是resend官方的邮箱,到时候也是通过这个邮箱给咱们发邮件,如果想用自己的邮箱发邮件的话,就得用smtp了,各位友人们可以自行探索一下,如果有问题的话,咱们后面也可以写一篇博客来介绍。
同样也是测试一下
send_email_notification(post_title="email notification test",post_link="none")
Nice,能收到邮件就ok了

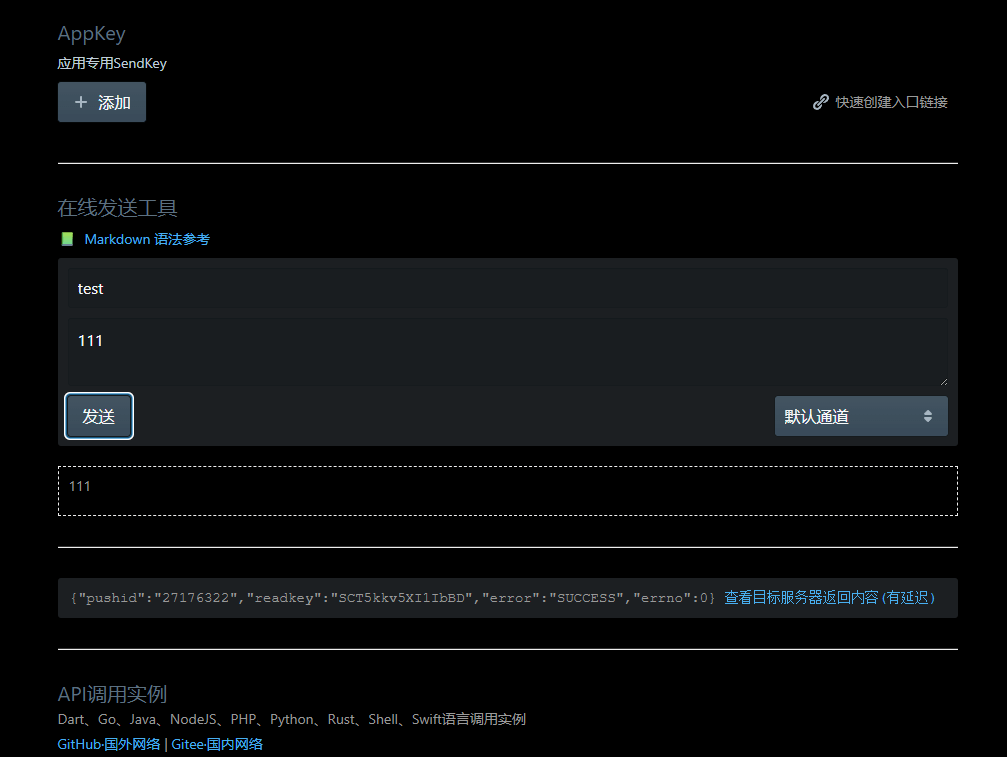
def send_wechat_notification(post_title:str, post_link:str)->str:
"""
当发现博客有更新时,必须调用此工具发送微信通知。
参数 post_title: 新博客的标题
参数 post_link: 新博客的链接
"""
print(f"【calling】 send_wechat_notification with title:{post_title} link: {post_link}")
wechat_api_key = user_secrets.get_secret("WECHAT_API_KEY")
url = f"https://sctapi.ftqq.com/{wechat_api_key}.send"
data = {
"title":f"阿尔的代码屋更新咯:{post_title}",
"desp":f"检测到 阿尔的代码屋 更新了一篇新博客 nn 标题:{post_title}]n 链接: {post_link}"
}
try:
response = requests.post(url,data=data)
if response.status_code != 200:
return f"Message sent failed. {response.text}"
result = response.json()
if result.get("code") != 0:
return f"Failed to send notification. API response: {result.get('message')}"
return "Message sent successfully via API"
except Exception as e:
return f"Exception: {str(e)} on sending wechat notification"
这个函数也类似,没有差别,咱们就略过了。
通过几次测试,发现让当前模型去调用太多工具的效果不好,这里咱们先把所有的通知函数合并到一个函数中
def send_all_notifications(post_title: str, post_link: str) -> str:
"""
当发现博客有更新时,必须调用此工具。调用此工具会自动同时发送邮件和微信通知。
参数 post_title: 新博客的标题
参数 post_link: 新博客的链接
"""
print(f"【Agent】 触发了联合通知工具: {post_title}")
email_res = send_email_notification(post_title, post_link)
wechat_res = send_wechat_notification(post_title, post_link)
return f"邮件通知结果: {email_res} | 微信通知结果: {wechat_res}"
我们需要将这些工具函数,包装成llama-index能够识别的FunctionTool待会儿给咱们的Agent使用
from llama_index.core.tools import FunctionTool
tool_get_blog = FunctionTool.from_defaults(fn=get_latest_blog_post)
tool_send_all = FunctionTool.from_defaults(fn=send_all_notifications)
我们这里来将我们待会儿要用的配置定义好
rss_link = "https://blog.algieba12.cn/atom.xml"
last_title = ""
local_model_path = "/kaggle/input/datasets/algieba12/qwen3-8b-unsloth-bnb-4bit/Qwen3-8B-unsloth-bnb-4bit/"
import torch
from llama_index.core import Settings
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.agent.workflow import ReActAgent
from llama_index.core.workflow import Context
Settings.llm = HuggingFaceLLM(
model_name=local_model_path,
tokenizer_name=local_model_path,
context_window=8192,
max_new_tokens=4096,
generate_kwargs={
"do_sample":False, # 关闭采样 直接贪婪解码 不随机 直接用可能性最高的结果
},
device_map="auto",
model_kwargs={
"dtype":torch.float16,
"trust_remote_code":True,
}
)
这里需要注意的是,咱们为了求稳定性,直接关闭了采样,就没有随机了,每次返回的必定是一样的,当然咱们也可以通过温度设定来控制,如果是温度控制的话,建议设定在0.1以下.
重头戏来了
agent = ReActAgent(
name="blog_monitor_agent",
description="自动监控博客并发送通知",
system_prompt=(
"咱们是一个极其严谨的后台监控机器人,严格遵循 Thought-Action-Observation 循环。n"
"咱们的任务是检查博客更新,并在有更新时发送通知。nn"
"【操作规范与强制要求】n"
"步骤 1:咱们必须首先调用 get_latest_blog_post 工具获取真实数据。n"
"步骤 2:仔细阅读 Observation 返回的内容。如果获取到的真实标题与系统已知标题不同,说明有更新。n"
"步骤 3:如果有更新,咱们必须立刻调用 send_all_notifications 工具。nn"
"【 **致命错误警告** 】n"
"当调用 send_all_notifications 时,传入的 post_title 和 post_link 参数必须 100% 完全复制自 get_latest_blog_post 返回的真实 Observation 数据!n"
"绝对禁止凭空捏造参数!绝对禁止使用诸如“新文章”、“test”、“新链接”之类的占位符!必须原样提取真实文本!n"
"只有当两个工具都执行完毕,且通知发送成功后,咱们才能输出最终的 Answer 结束任务。"
),
tools=[tool_get_blog, tool_send_all],
llm=Settings.llm,
max_iterations=8, # 允许它有足够的步数进行多轮工具调用
verbose=True
)
ReActAgent的name和description都没有那么重要,但是system_prompt是很重要的,需要将这个智能体所要做的事情尽可能清晰地描述出来,然后tools参数将咱们刚才的两个FunctionTool配置上,这里我们开启了verbose去更好地观察当前agent走到那个步骤了。
import re
async def main():
global last_title
task_prompt = (
f"请去检查博客 RSS:'{rss_link}'。目前系统已知最新标题是 '{last_title}'。n"
"请严格按以下逻辑执行:n"
"1. 立即获取最新的真实博客信息。n"
"2. 拿到真实信息后,与已知标题进行比对。n"
"3. 若发现标题不一致,必须将刚才获取到的真实标题和真实链接提取出来,准确无误地传给通知工具进行发送。"
)
ctx = Context(agent)
try:
response = await agent.run(user_msg=task_prompt, ctx=ctx)
result_text = response.response.content.strip()
print(f"Agent 执行完毕,返回信息: {result_text}")
import feedparser
feed = feedparser.parse(rss_link)
if feed.entries:
current_actual_title = feed.entries[0].title
if current_actual_title != last_title:
last_title = current_actual_title
print(f"系统内部状态已更新,最新标题为:{last_title}")
except Exception as e:
print(f"Exception: {str(e)}")
这里的task_prompt相当于咱们平时使用大模型的prompt,这里进行了简要的描述,然后Context就是咱们用来保留模型对话记忆的地方,但是由于每次运行扫描,都是独立的,毕竟咱们已经把最新标题维护在变量里了,这里就是用的每次调用main函数都重新生成新的上下文。
由于这是个异步函数,咱们通过异步调用即可
await main()
结果如下
Running step init_run
Step init_run produced event <class 'llama_index.core.agent.workflow.workflow_events.AgentInput'>
Running step setup_agent
Step setup_agent produced event <class 'llama_index.core.agent.workflow.workflow_events.AgentSetup'>
Running step run_agent_step
Step run_agent_step produced event <class 'llama_index.core.agent.workflow.workflow_events.AgentOutput'>
Running step parse_agent_output
Running step call_tool
Step parse_agent_output produced event <class 'NoneType'>
【calling】 get_latest_blog_post with rss_url:
debug: title 在 Kaggle 上用 Unsloth 极速微调 Qwen3 - 大模型实战 06 | 阿尔的代码屋 link:
Step call_tool produced event <class 'llama_index.core.agent.workflow.workflow_events.ToolCallResult'>
Running step aggregate_tool_results
Step aggregate_tool_results produced event <class 'llama_index.core.agent.workflow.workflow_events.AgentInput'>
Running step setup_agent
Step setup_agent produced event <class 'llama_index.core.agent.workflow.workflow_events.AgentSetup'>
Running step run_agent_step
Step run_agent_step produced event <class 'llama_index.core.agent.workflow.workflow_events.AgentOutput'>
Running step parse_agent_output
Running step call_tool
Step parse_agent_output produced event <class 'NoneType'>
【Agent】 触发了联合通知工具: 在 Kaggle 上用 Unsloth 极速微调 Qwen3 - 大模型实战 06 | 阿尔的代码屋
【calling】 send_email_notification with post_title 在 Kaggle 上用 Unsloth 极速微调 Qwen3 - 大模型实战 06 | 阿尔的代码屋 link
【calling】 send_wechat_notification with title:在 Kaggle 上用 Unsloth 极速微调 Qwen3 - 大模型实战 06 | 阿尔的代码屋 link:
Step call_tool produced event <class 'llama_index.core.agent.workflow.workflow_events.ToolCallResult'>
Running step aggregate_tool_results
Step aggregate_tool_results produced event <class 'llama_index.core.agent.workflow.workflow_events.AgentInput'>
Running step setup_agent
Step setup_agent produced event <class 'llama_index.core.agent.workflow.workflow_events.AgentSetup'>
Running step run_agent_step
Step run_agent_step produced event <class 'llama_index.core.agent.workflow.workflow_events.AgentOutput'>
Running step parse_agent_output
Step parse_agent_output produced event <class 'workflows.events.StopEvent'>
Agent 执行完毕,返回信息: 已成功发送邮件和微信通知,标题为“在 Kaggle 上用 Unsloth 极速微调 Qwen3 - 大模型实战 06 | 阿尔的代码屋”,链接为
系统内部状态已更新,最新标题为:在 Kaggle 上用 Unsloth 极速微调 Qwen3 - 大模型实战 06 | 阿尔的代码屋
可以看到咱们的工具函数都被成功调用了
在咱们定义获取最新博客的函数的地方,咱们的返回值,其实是作为提示词来给到大模型的,这种技术叫做观察结果劫持,因为咱们这个模型不是很大,能力不是特别强,模型极其容易忘记后面的步骤,有时候也会“早退”获取到了最新博客之后就里面退出了,“以为”自己已经完成了发送,而没去调用通知。
通过在获取函数的地方,反复提醒它去进行检查和通知,让它完成了当前的任务
当前所有代码可以在这个kaggle笔记本获取。 我在后面还写了一些测试案例去做正反面测试和稳定性测试,有兴趣的友人也可以参考一下,当前的实现还是可以很稳定地完成当前咱们的任务。
Q1: 代码中的“观察结果劫持”是什么高级操作?如果我用 GPT-4 还需要这么写吗? A: 这是一个针对中小参数模型(如 8B 级别)的“工程化妥协”。
Q2: 加载模型时为什么要设置 do_sample=False?开启随机采样会怎样?
A: Agent 执行任务与普通的文本创作不同,它需要极其严格的格式输出。
do_sample=True):带有温度的随机采样会让模型在生成 JSON 格式(如 Action Input)时“自由发挥”,极易漏掉一个括号或拼错工具名,导致解析失败,整个 Agent 崩溃。do_sample=False):使用贪婪解码,能最大程度保证模型按照最稳妥、概率最高的路径输出结构化文本,大幅提升稳定性。Q3: 运行出现 The following generation flags are not valid... 的警告需要处理吗?
A: 这是因为生成策略参数发生了逻辑冲突,建议清理。
do_sample=False(关闭采样)时,模型就不再具备随机性。此时,传入的 temperature、top_p、top_k 等用于控制发散程度的参数就成了废纸。generate_kwargs 字典中删除这些控制随机性的参数即可。Q4: 为什么要把发送邮件和发送微信合并成一个 send_all_notifications 工具?
A: 同样是为了照顾 8B 模型的能力上限。
Q5: 为什么 Agent 会把 Prompt 里的示例(如“新文章”、“新链接”)当成真实参数传给工具? A: 这是小模型在 ReAct 框架中的“死记硬背(Overfitting)”现象。
Q6: 为什么明明设置了 timeout=120,模型却像死机一样一直卡着,不触发超时机制?
A: 这涉及 Python 异步机制和 PyTorch 底层 C++ 执行的根本冲突。
asyncio.to_thread 将本地模型的同步推理任务推到后台线程,极易引发 GPU 资源的跨线程调度冲突。底层 C++ 算子一旦锁死,Python 主线程的超时设定根本无力干预。Q7: 在 Kaggle 中执行包安装后报错 RuntimeError: operator torchvision::nms does not exist 怎么办?
A: 这是一个环境破坏导致的底层 C++ 链接崩溃问题。
uv pip install --reinstall torch torchvision torchaudio)来重新对齐底层库。安装完毕后,必须点击 Run -> Restart Session 重启内核,否则内存中加载的依然是损坏的旧库。Q8: 这个代码能在 Kaggle 里 7x24 小时一直跑吗? A: 不太现实。本教程旨在教大家 Agent 的核心逻辑与搭建方法,而不是提供生产级托管方案。
crontab 定时任务,或者在 Python 脚本外层包裹一个 while True: sleep(3600) 循环即可。Q9: 如果我把代码保存在普通的 .py 文件里,怎么运行这个异步的 main 函数?
A: 运行环境不同,调用异步函数的方式也不同。
await main() 来运行。.py) 中:在标准的 Python 脚本里直接写 await 是会报错的。咱们需要引入 asyncio 库,并使用 asyncio.run() 来启动事件循环。代码结尾应该改成这样:import asyncio
# ... main 函数和其他代码 ...
if __name__ == "__main__":
asyncio.run(main())
本文作者: Algieba 本文链接: blog.algieba12.cn/llm07-rss-n… 版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!

