WeBand
119.15M · 2026-04-13

大家好,我是老赵,一名程序员老兵,平时主要从事企业级应用开发,最近打算从零学习、并落地一套完整的RAG检索增强生成系统。不搞虚头理论,全程边学边做,把遇到的问题、踩过的坑、能直接跑通的代码,全都真实记录下来。
前四天我们完成了环境搭建、Milvus部署、文档向量化以及检索匹配并做了结果优化。今天第5天的目标是安装Ollama并在本地运行模型,为RAG的生成环节提供本地LLM服务。
qwen3:4b 模型;curl、git、可选的 docker。 官方安装:请从Ollama官方网站下载windows安装包并进行安装ollama.com/download/wi…,安装后在命令行中运行 ollama --version, 确认ollama可用。
qwen3:4b(示例流程)以下命令为通用示例,实际命令请以当前Ollama CLI/镜像为准:
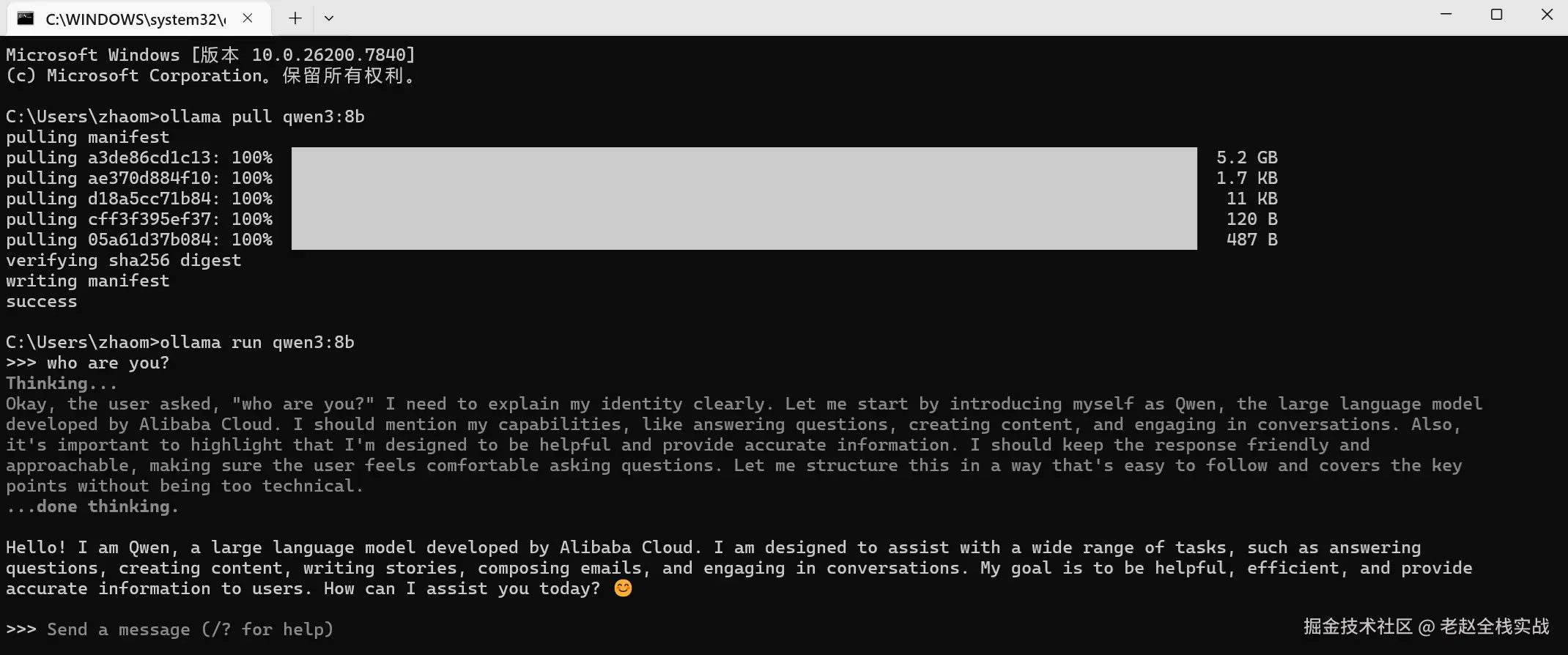
ollama pull qwen3:4b
ollama run qwen3:4b
以下截图展示了运行的结果:
# 如果 Ollama 提供守护进程或 listen 参数,按官方方法启动并本地端口
ollama serve --port 11434
说明:模型名称请严格使用官方 ID(本文使用 qwen3:4b 作为示例)。如出现“找不到模型”,请运行 ollama list 或查看官方模型仓库确认可用模型 ID。
Ollama通过端口11434提供HTTP API,以下为示例请求(请根据实际API字段调整):
curl -s -X POST "http://localhost:11434/api/generate"
-H "Content-Type: application/json"
-d '{
"model": "qwen3:4b",
"prompt": "请用中文简要介绍向量检索的基本流程。",
"max_tokens": 200
}'
Python 示例(requests):
import requests
url = "http://localhost:11434/api/generate"
payload = {
"model": "qwen3:4b",
"prompt": "请用中文列出 RAG 流程步骤。",
"max_tokens": 200,
"stream": False,
}
resp = requests.post(url, json=payload, timeout=300)
print(resp.json())
说明:上面 prompt、max_tokens 等字段为示例,具体字段名请参照当前 Ollama版本的API文档。
qwen3:4b 属中等规模,生产场景可根据成本/延迟选择更合适的模型。qwen3:4b 的典型流程,为 RAG的生成环节打好基础。我是老赵,一名程序员老兵,全程真实记录RAG从零搭建全过程。本系列会持续更新,最后整理成完整视频教程+源码+部署手册。
关注 老赵全栈实战,不迷路,一起从0落地RAG系统。

