
对话翻译App
20.8MB · 2026-04-06

LLM:基于Transform + 大参数量 + 大数据量 => 从概率上预测文本接下来的内容,使文本得到合理的“延续”,最终表现为像有思考能力的“大脑”一样,能够基于问题回答问题。
Agent:基于LLM能力,提供“四肢”,使得像人一样,不仅能思考还能行动。所谓的“四肢”,可以理解为由用户实时数据+工具,使得LLM与现实建立连接,并且能对现实产生影响。
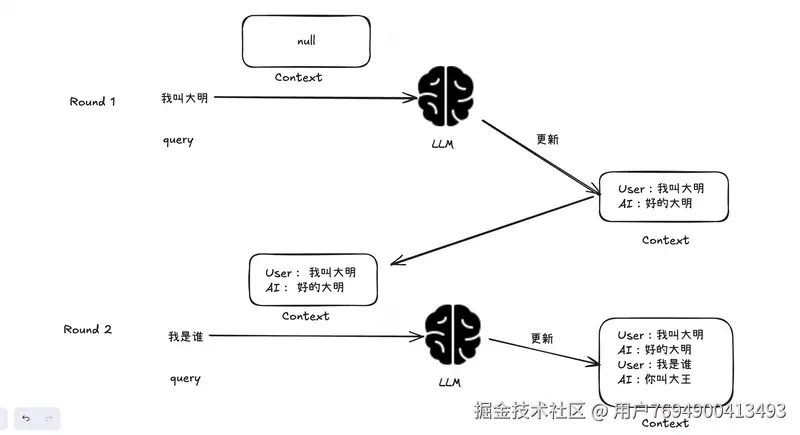
每次请求模型时,携带历史对话窗口信息,当作query的一部分。
对话窗口通常实现为滑动窗口,维护最近n轮对话信息。
编辑
在最简单(滑动窗口)实现的短期记忆基础上,考虑如何更高效维护长短记忆(降低成本 token 消耗)、维护长期记忆。
降低成本:
维护长期记忆:
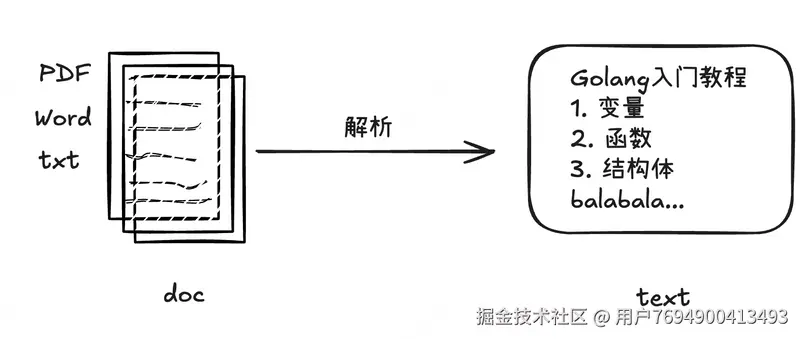
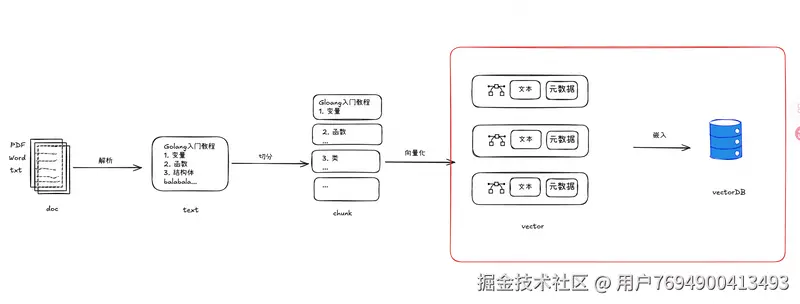
文档:用户提供的文本信息,欲为模型提供信息(外部数据源)。
文档解析:读取文档中的文本内容。
编辑
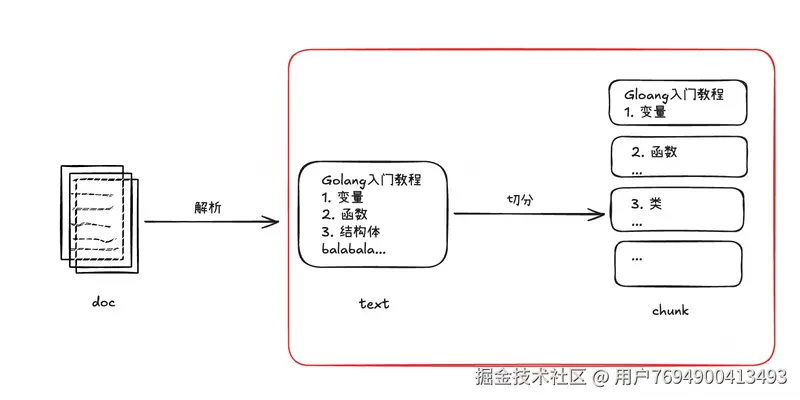
文档切分:将文本内容切分成小的一段(chunk)。
编辑
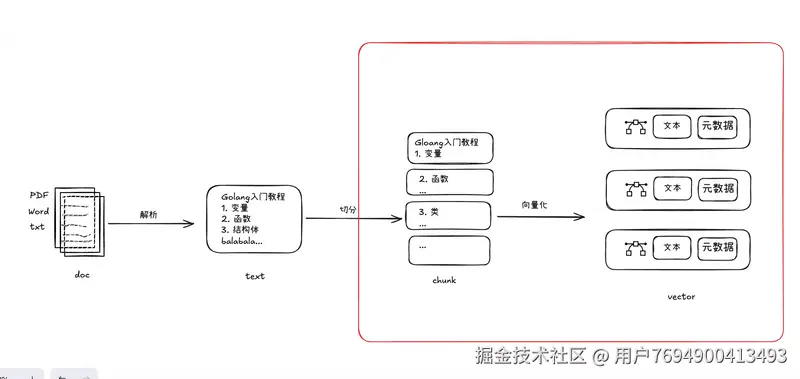
向量化:通过向量化模型将文本解析成多维向量。
编辑
嵌入:向量存储到向量数据库的动作。
编辑
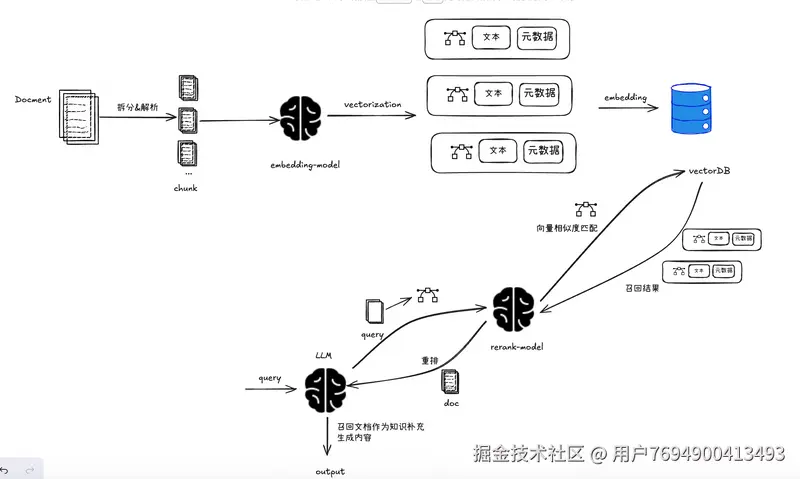
文档召回:根据query,将query向量化,从向量化数据库中根据向量相似度计算进行文档召回。
重排序:应用于文档召回的结果,再做一次精排过滤。
向量与文本之间的关系:
向量时是文本在语义空间里的位置坐标。
每一个维度表示一种语义,用来区分文本的表达,同时向量维度越高,表达力越高,同时对向量化模型的能力与向量的存储要求也高。
eg.
文本:你是谁
[ 0.02134, -0.11782, 0.33491, -0.05217, 0.90831, -0.44102, 0.12944, -0.77230, 0.05681, 0.24899, -0.31540, 0.60127, -0.04498, 0.18733, 0.09211, -0.50988, 0.41102, -0.03277, 0.27561, -0.19844, 0.00321, 0.81277, -0.62108, 0.14419, ... -0.08211, 0.19344, -0.44720, 0.06177 ]
RAG核心流程:
编辑
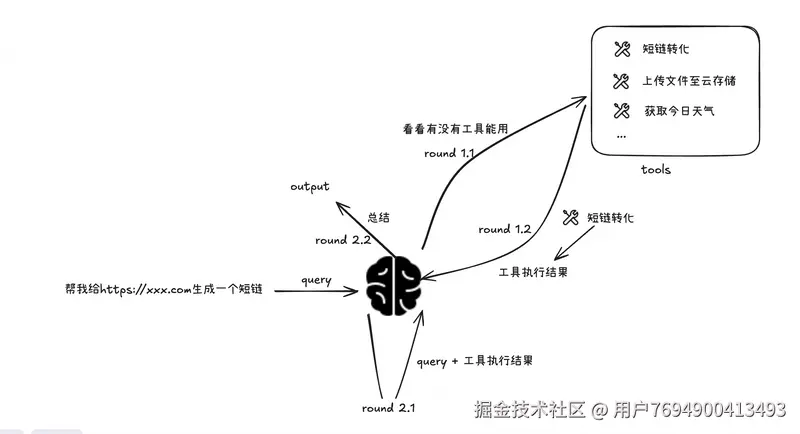
function calling流程:
编辑
1次工具调用 => 与至少模型交互2回合
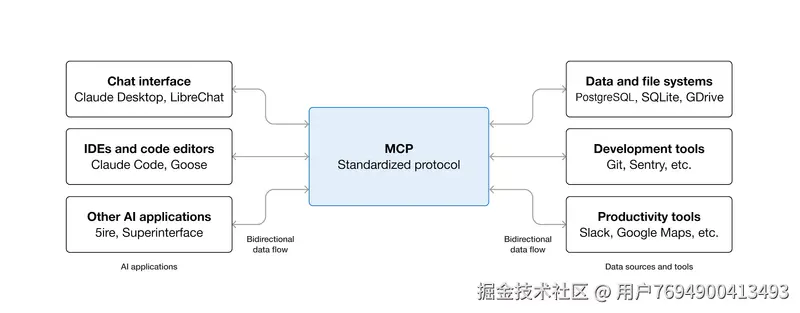
在agent应用中,本质也是一种工具调用(function calling),就是规范协议,方便开发者接入与开发。
编辑
| 维度 | LangChain | LangChain4j | Spring AI | Eino | |
| 语言 | Python | Java | Java | Go | |
| 定位 | LLM 应用框架 | LangChain 的 Java 生态实现 | Spring 体系下的 AI 抽象层 | Go 生态的 LLM 应用框架 | |
| 与业务框架融合 | 弱(偏独立库) | 中等 | 强(Spring 原生) | 中等 |
语言模型
编辑
OpenAiChatModel model = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName("gpt-4o-mini")
.temperature(0.3)
.timeout(ofSeconds(60))
.build();
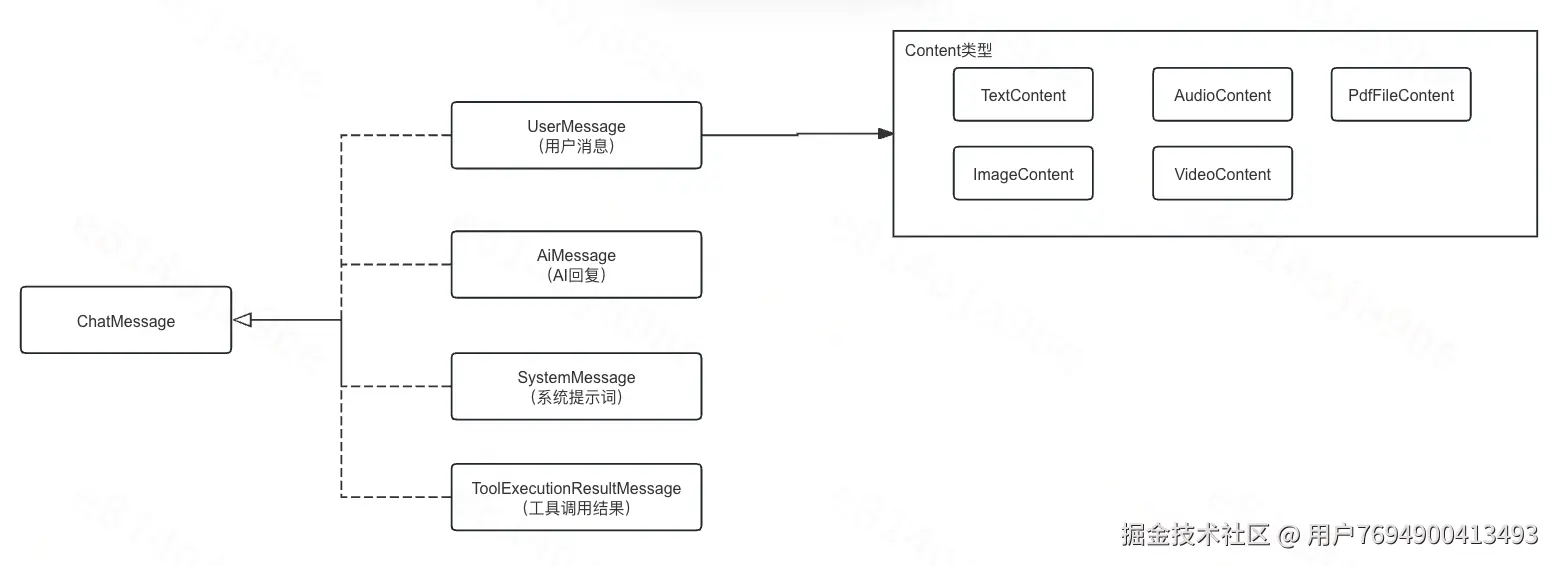
聊天消息类型
编辑
聊天记忆
ChatMemory接口提供聊天对话存储能力(记忆),可以自实现接口实现持久化存储。langchain4j提供了两种实现:
MessageWindowChatMemory: 滑动窗口,仅保留最近窗口内的N条对话记录。MessageWindowChatMemory: 也是滑动窗口,但专注于保留最近N个Token。当有新消息时,会自动回调ChatMemory接口中相关的方法,同步更新对话上下文存储。
聊天示例:
interface Assistant {
String chat(String message);
}
public static void main(String[] args) {
// 1. 最近对话(记忆)存储器
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
// 2. 语言模型
ChatModel model = OpenAiChatModel.builder()
.apiKey(ApiKeys.OPENAI_API_KEY)
.modelName(GPT_4_O_MINI)
.build();
// 3. ai服务
Assistant assistant = AiServices.builder(Assistant.class)
.chatModel(model)
.chatMemory(chatMemory)
.build();
String answer = assistant.chat("你好,我叫小明");
System.out.println(answer); // 小明你好,有什么可以帮助你的吗?
String answerWithName = assistant.chat("我的名字叫啥");
System.out.println(answerWithName); // 你叫小明
}
@Tool("对给定的 2 个数字求和")
double sum(double a, double b) {
return a + b;
}
@Tool("返回给定数字的平方根")
double squareRoot(double x) {
return Math.sqrt(x);
}
interface MathGenius {
String ask(String question);
}
class Calculator {
@Tool
double add(int a, int b) {
return a + b;
}
@Tool
double squareRoot(double x) {
return Math.sqrt(x);
}
}
MathGenius mathGenius = AiServices.builder(MathGenius.class)
.chatLanguageModel(model)
.tools(new Calculator())
.build();
String answer = mathGenius.ask("475695037565 的平方根是多少?");
System.out.println(answer); // 475695037565 的平方根是 689706.486532。
请求 1:
- 消息:
- UserMessage:
- 文本:475695037565 的平方根是多少?
- 工具:
- sum(double a, double b):对给定的 2 个数字求和
- squareRoot(double x):返回给定数字的平方根
响应 1:
- AiMessage:
- toolExecutionRequests:
- squareRoot(475695037565)
请求 2:
- 消息:
- UserMessage:
- 文本:475695037565 的平方根是多少?
- AiMessage:
- toolExecutionRequests:
- squareRoot(475695037565)
- ToolExecutionResultMessage:
- 文本:689706.486532
响应 2:
- AiMessage:
- 文本:475695037565 的平方根是 689706.486532。
接入示例
public class McpDemo {
public static void main(String[] args) {
String dashscopeApiKey = "api-key";
// 0. mcp客户端鉴权
Map<String, String> headers = Map.of(
"Authorization", "Bearer " + dashscopeApiKey,
"Content-Type", "application/json"
);
// 1. mcp(联网搜索)封装
McpTransport transport = new StreamableHttpMcpTransport.Builder()
.url("https://dashscope.aliyuncs.com/api/v1/mcps/WebSearch/sse")
.customHeaders(headers)
.logRequests(true)
.logResponses(true)
.build();
// 2. mcp注册
McpClient mcpClient = new DefaultMcpClient.Builder()
.transport(transport)
.build();
McpToolProvider toolProvider = McpToolProvider.builder()
.mcpClients(List.of(mcpClient))
.build();
// 3. 带有联网搜索能力的ai服务
Bot bot = AiServices.builder(Bot.class)
.chatLanguageModel(model)
.toolProvider(toolProvider)
.build()
.getService();
}
}
关键词解释
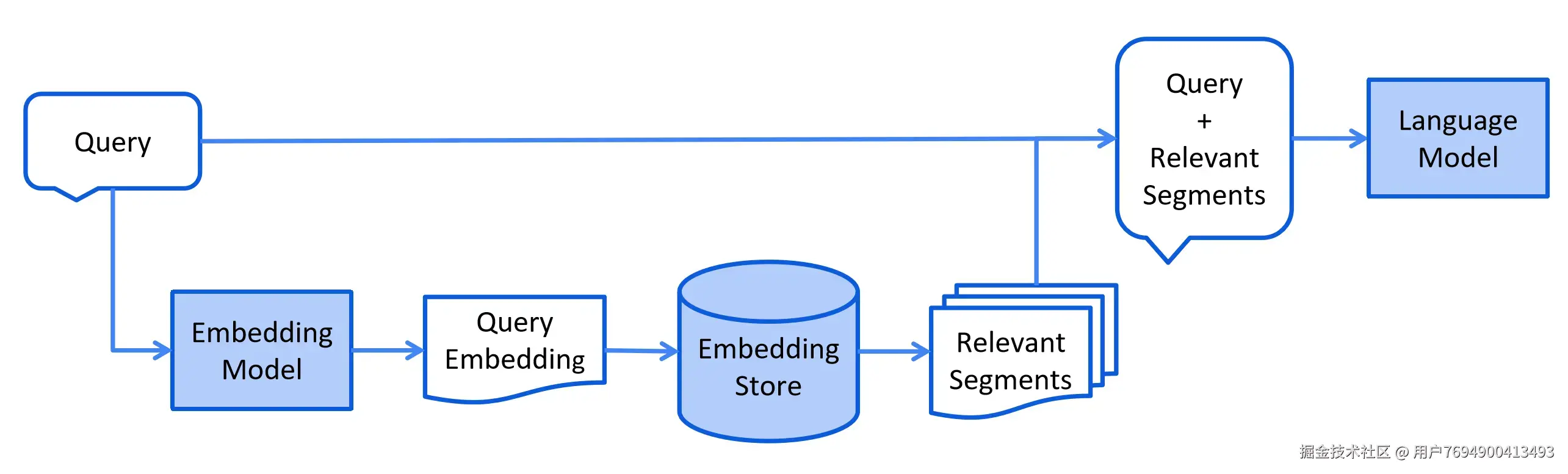
Query:用户输入
Embedding Model: 向量化模型
Embedding Store: 向量化数据库
Relevant Segments: 检索(召回)结果
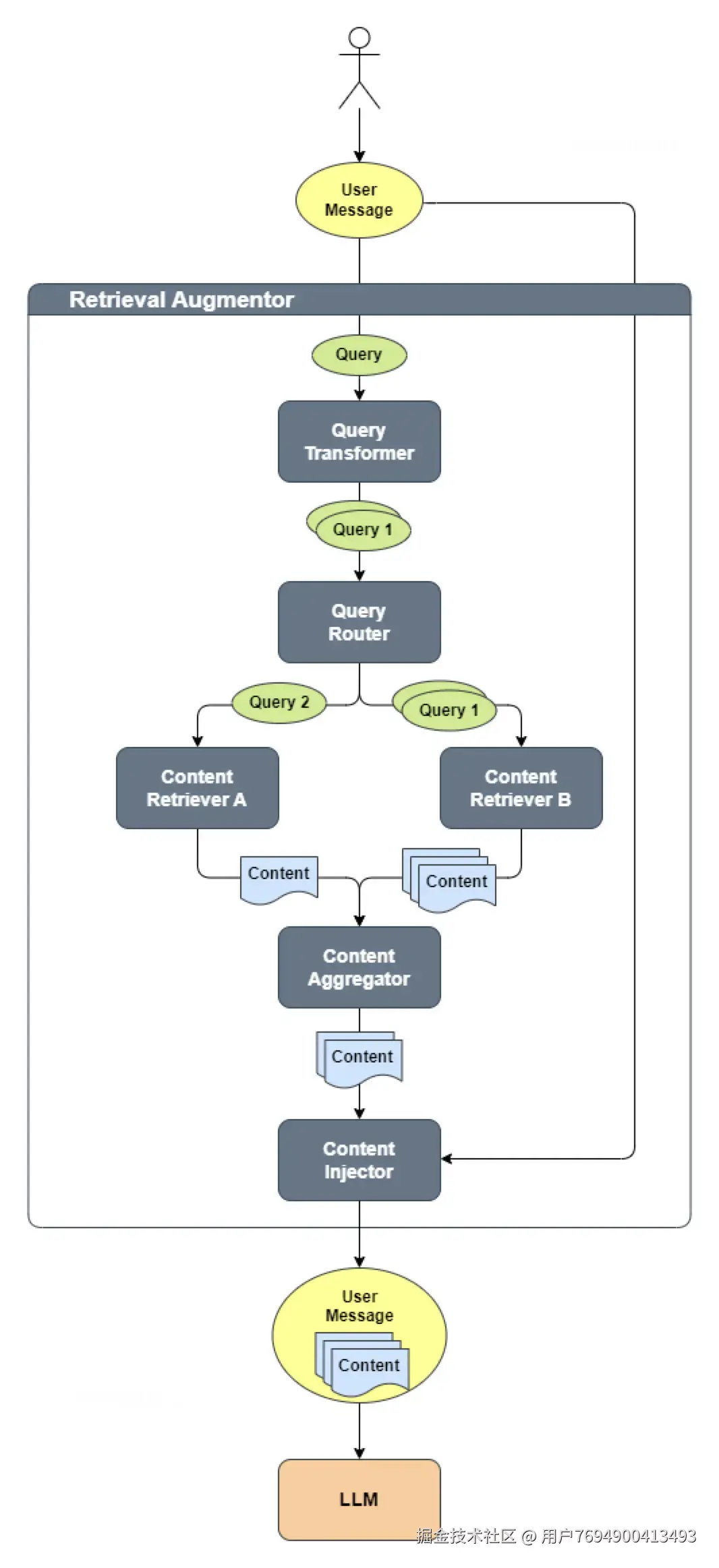
Retrieval Augmentor: 检索增强器,所有RAG相关的组件封装在该类中。
QueryTransformer: 问题拆分器,如果一次query包含多个问题,会被拆分成子问题。
Content Retrieval:内容检索器,从给定数据源(向量数据库)中检索。
Query Router:query路由器,将拆分的子问题智能路由到检索器中。
Content Aggregator:内容聚合器,规定如何将多个内容检索器的结果聚合。
Content Injector:规定检索结果如何嵌入到原始query中。
编辑
作业流程
编辑

