浴室泡泡大作战
91.22M · 2026-03-29

在上篇《多智能体协作案例实践(一):基于AgentScope框架》文章中,Chaiys同学围绕高考信息查询智能助手业务场景,采用AgentScope框架进行多智能体协作的验证。
本文基于同样的业务场景和案例,采用LangGraph框架进行对比实践和验证,以便更深入地理解。
首先回顾一下业务场景,和上篇文章保持一致,还是支撑用户进行高考信息查询,并且要支持多轮对话,后续会基于以下案例来进行验证:
第一轮提问:2016年考生人数有多少?
第二轮追问年份:2018年呢?
第三轮追问其他:录取人数呢?
针对该业务场景,四个智能体之间的协作逻辑和AgentScope案例也完全保持一致:
1)用户输入问题
2)TemplateAgent判断是否有上下文历史,如果没有则转4,有则进一步匹配历史问题模板,如未匹配到则转3,如匹配到则基于模板SQL,从用户当前问题中提取查询参数植入模板SQL,执行后带查询结果转5
3)有上下文历史,但没有匹配的历史问题,则进入意图识别改写RewriteAgent,利用上下文对话背景对用户当前问题做改写,然后进入SQLAgent,RAG检索元数据、生成SQL、查询数据,最后进入AnalysisAgent分析回答
4)无上下文历史,代表用户是首次提问,则直接进入SQLAgent,RAG检索元数据、生成SQL、查询数据,最后进入AnalysisAgent分析回答
5)根据查询结果直接进入AnalysisAgent分析回答
这个协作逻辑基于 LangGraph框架的自定义状态图StataGraph实现:
# ========================
# 路由函数
# ========================
def route_to_next_agent(state: State) -> Literal["sql", "analysis", "rewrite", "__end__"]:
if state.get("next_agent") == "sql":
return "sql"
if state.get("next_agent") == "analysis":
return "analysis"
if state.get("next_agent") == "rewrite":
return "rewrite"
return "__end__"
workflow = StateGraph(State)
workflow.add_node("template", template_agent)
workflow.add_node("rewrite", rewrite_agent) # 新增改写智能体
workflow.add_node("sql", sql_agent)
workflow.add_node("analysis", analysis_agent)
workflow.add_edge(START, "template")
# Template 之后根据条件流向
workflow.add_conditional_edges(
"template",
route_to_next_agent,
{
"rewrite": "rewrite", # 新增 rewrite 分支
"sql": "sql",
"analysis": "analysis",
"__end__": END
}
)
# 改写智能体完成后交给 SQL
workflow.add_edge("rewrite", "sql")
# SQL 执行后流向分析
workflow.add_edge("sql", "analysis")
workflow.add_edge("analysis", END)
# ========================
# ▶️ 主流程
# ========================
if __name__ == "__main__":
from uuid import uuid4
print(" 智能数据助手(支持追问、多轮上下文)")
print("=" *80)
print(" 输入问题开始对话,输入 'exit' 退出。")
print("=" *80)
# 每次启动生成唯一 thread_id(上下文记忆关键)
thread_id = str(uuid4())
config = {"configurable": {"thread_id": thread_id}}
while True:
user_input = input("n 你: ").strip()
if not user_input:
continue
if user_input.lower() in {"exit", "quit"}:
print(" 再见!会话已结束。")
break
# 构造输入
input_data = {
"messages": [HumanMessage(content=user_input)],
}
try:
# 流式执行
for chunk in app.stream(input_data, config=config):
if "analysis" in chunk:
msg = chunk["analysis"]["messages"][0]
print(f" 助手: {msg.content.strip()}")
print("-" *60)
elif "sql" in chunk and "messages" in chunk["sql"]:
# SQL 生成失败的情况
for m in chunk["sql"]["messages"]:
if isinstance(m, AIMessage):
print(f" 助手: {m.content.strip()}")
print("-" *60)
elif "__end__" in chunk:
print(" 对话结束")
except json.JSONDecodeError:
print("️ JSON 解析失败,可能是 LLM 返回了非结构化内容。")
except KeyboardInterrupt:
print("n⏹️ 中断。输入 exit 可退出。")
except Exception as e:
print(f" 出错:{e}")
如以上代码所示,通过“workflow.add_node”方式添加四个Node节点:template、rewrite、sql、analysis分别代表四个智能体。
通过“workflow.add_edge”方式添加对应节点之间的跳转关系,其中“workflow.add_conditional_edges”是添加条件边,通过调用route_to_next_agent()路由函数根据智能体返回的next_agent字段决定流转到哪一个节点。
LangGraph上下文记忆的相关机制,主要通过官方提供的 MemorySaver() 实现:
# 启用记忆(支持多轮对话)
memory = MemorySaver()
app = workflow.compile(checkpointer=memory)
MemorySaver会将每一个节点执行后的 State 存储到检查点(checkpoint)中,使得下一次调用可以从之前的对话状态继续执行。
其特点是原样存 储state状态机,不裁剪、不删减、不合并历史,真正关键的是你在 State 状态机中设计的业务逻辑。
使用“ StateGraph(State)”方式在状态图StateGraph初始化时就将自定义State状态机对象注入并绑定:
# ========================
# 增强状态定义
# ========================
class State(TypedDict):
messages: Annotated[list[BaseMessage], add_messages]
original_intent: Optional[str] # 如 "考生人数"
known_table_struct: Optional[List] # 已确认的表结构
last_sql_template: Optional[str] # 带占位符的 SQL 模板,如 "SELECT ... WHERE year = {year}"
query_result: Optional[list] # 最近一次查询结果
next_agent: str
每轮对话都会在全局统一状态机中保存以下信息:
| key | 含义 |
|---|---|
| messages | 历史消息列表 |
| original_intent | 用户的核心意图(如“考生人数”) |
| known_table_struct | 已识别的数据表结构 |
| last_sql_template | 参数化 SQL 模板,便于复用 |
| query_result | 查询结果 |
| next_agent | 下一步路由方向 |
其中当我们使用 Annotated[list[BaseMessage], add_messages] 来定义 State 中的 messages 字段时,新的消息会自动被追加到现有的消息列表之后,这是 LangGraph 为管理对话历史等序列化数据提供的一种便捷且强大的状态更新机制。
LangGraph所有智能体Agent都要遵循统一规范,将Stata对象作为输入输出对象,如以下“模板匹配智能体”templateAgent的代码所示:
# ========================
# 模板匹配 智能体(支持追问模板复用)
# ========================
def template_agent(state: State):
print("=== Template Agent ===")
current_query = state["messages"][-1].content
# ───────────────────────────────────────
# 情况1:无上下文 → SQL Agent
# ───────────────────────────────────────
if (not state.get("known_table_struct")
or not state.get("original_intent")
or not state.get("last_sql_template")):
print("️ 不存在上下文,进入SQL Agent流程")
return {
"messages": state["messages"],
"next_agent": "sql"
}
# ───────────────────────────────────────
# 情况2:已有上下文 → 尝试参数化追问处理
# ───────────────────────────────────────
print(" 检测到历史上下文,尝试参数化追问")
try:
# 具体业务代码跳过...
print(f" 追问查询成功,进入分析流程")
return {
"query_result": result,
"next_agent": "analysis"
}
except Exception as e:
print(f"参数提取失败: {e}")
print("️ 追问处理失败,进入改写流程")
return {
"messages": state["messages"],
"next_agent": "rewrite"
}
我们测试一下LangGraph实现多智能体协作的效果:
智能数据助手(支持追问、多轮上下文)
================================================================================
输入问题开始对话,输入 'exit' 退出。
================================================================================
你: 2016年考生人数有多少?
=== Template Agent ===
️ 不存在上下文,进入SQL Agent流程
=== Sql Agent ===
启动完整查询流程
调用大模型llama2向量化:2016年考生人数有多少?
匹配表结构: ['{"表名": "college_entrance_examination", "表备注": "考生人数与复读人数信息表,包含字段:高考年份(主键)、考生人数(万人)、复读人数(万人)", "字段列表": [{"字段名": "examination_year", "字段类型": "int", "字段备注": "高考年份"}, {"字段名": "candidates_count", "字段类型": "decimal(10,2)", "字段备注": "考生人数(万人)"}, {"字段名": "retake_count", "字段类型": "decimal(10,2)", "字段备注": "复读人数(万人)"}]}']
原始意图: 2016年考生人数有多少?
保存 SQL 模板: SELECT candidates_count AS '考生人数' FROM college_entrance_examination WHERE examination_year = {year};
=== Analysis Agent ===
助手: **2016年高考考生人数分析报告**
**事实陈述**
2016年高考考生人数为 **940.00万人**(数据来源:考生人数与复读人数信息表)。
**简要洞察**
当前数据仅包含单一时间点的记录,暂无法直接推导趋势变化。若需分析考生人数增减规律,建议结合相邻年份数据(如2015年及2017年)进行对比。
**备注**
数据单位为“万人”,数值保留两位小数,统计口径可能包含应届生与复读生。如需进一步解读,可补充复读人数或分省数据辅助分析。
---
(报告基于提供的数据生成,内容简洁客观,避免过度推测。)
------------------------------------------------------------
你: 2018年呢?
=== Template Agent ===
检测到历史上下文,尝试参数化追问
提取参数: {"year": "2018"}
️ 生成新 SQL: SELECT candidates_count AS '考生人数' FROM college_entrance_examination WHERE examination_year = 2018;
追问查询成功,返回 1 行
=== Analysis Agent ===
助手: **2016年高考考生人数分析报告**
**事实陈述**
2016年高考考生人数为 **975.0万人**(数据来源:考生人数与复读人数信息表)。
**简要洞察**
1. 当前数据仅包含单一时间点的记录,暂无法分析趋势变化。若需观察考生人数增减趋势,建议补充相邻年份数据(如2015年及2017年数据)。
2. 表中还包含“复读人数”字段,若需进一步分析复读对考生总数的影响,可提供对应数据后补充说明。
**备注**
数据单位为“万人”,实际考生人数为9,750,000人。如需更深入的统计分析(如增长率、区域对比等),请提供扩展数据集。
---
**报告说明**:本报告基于提供的数据直接呈现核心结论,避免对单一数据点进行推测性解读。
------------------------------------------------------------
你: 录取人数呢?
=== Template Agent ===
检测到历史上下文,尝试参数化追问
提取参数: {}
️ 年份参数提取失败,进入改写流程
=== Rewrite Agent ===
️ 改写后问题: 2018年全国高考录取人数是多少?
=== Sql Agent ===
启动完整查询流程
调用大模型llama2向量化:2018年全国高考录取人数是多少?
匹配表结构: ['{"表名": "college_entrance_admission", "表备注": "录取人数与普通高校数信息表,包含字段:录取年份(主键)、录取人数(万人)、招生高校数、本科录取人数(万人)、专科录取人数(万人)", "字段列表": [{"字段名": "admission_year", "字段类型": "int", "字段备注": "录取年份"}, {"字段名": "admission_count", "字段类型": "decimal(10,2)", "字段备注": "录取人数(万人)"}, {"字段名": "university_count", "字段类型": "int", "字段备注": "招生高校数"}, {"字段名": "undergraduate_admission_count", "字段类型": "decimal(10,2)", "字段备注": "本科录取人数(万人)"}, {"字段名": "specialty_admission_count", "字段类型": "decimal(10,2)", "字段备注": "专科录取人数(万人)"}]}']
原始意图: 2018年全国高考录取人数是多少?
保存 SQL 模板: SELECT admission_count AS '考生人数' FROM college_entrance_admission WHERE admission_year = {year};
=== Analysis Agent ===
助手: **2018年全国高考录取人数分析报告**
**事实陈述**
根据数据表 `college_entrance_admission` 记录,**2018年全国高考录取人数为 790.99 万人**。
**简要洞察**
1. **数据背景**:该数据反映当年普通高校(含本科及专科)录取总规模,但未提供与考生人数、录取率的对比信息。
2. **趋势参考**:若结合近年数据(需补充),可进一步分析录取人数变化趋势;当前单一数据点建议谨慎用于预测。
3. **结构细化**:表中包含本科与专科分层数据字段(未在本次结果中体现),后续可针对学历层次结构进行深入分析。
**注意事项**
- 当前数据为单一数值,分析需避免过度推论。
- 如需评估录取竞争程度,需补充同年高考报名人数或招生计划数据。
---
**报告说明**:本分析基于提供的数据表结构及查询结果,确保表述与原始数据一致。
------------------------------------------------------------
你:
第一轮问题:2016年考生人数有多少?
第一轮没有上下文,也没有全局变量模板,所以直接走SQL Agent + Analysis AgentRAG检索、生成SQL、查数、分析。同时SQL Agent生成成功后记录SQL模板到全局state。
第二轮问题:2018年呢?
第二轮我们追问2018年,这时存在全局变量模板,所以走模板匹配提取年份参数,直接查数然后通过业务判断存在数据,走Analysis Agent分析。
第三轮问题:录取人数呢?
第三轮我们追问录取人数,但是匹配不到模板,所以上层业务判断走Rewrite Agent + SQL Agent + Analysis Agent改写问题完善条件。改写时,参考Memory中上下文2016和2018年回答,改写为2018年全国高考录取人数是多少?然后走RAG检索、生成SQL、查数、分析。
本文使用LangGraph的Custom图模式实现我们的多智能体协作处理业务:
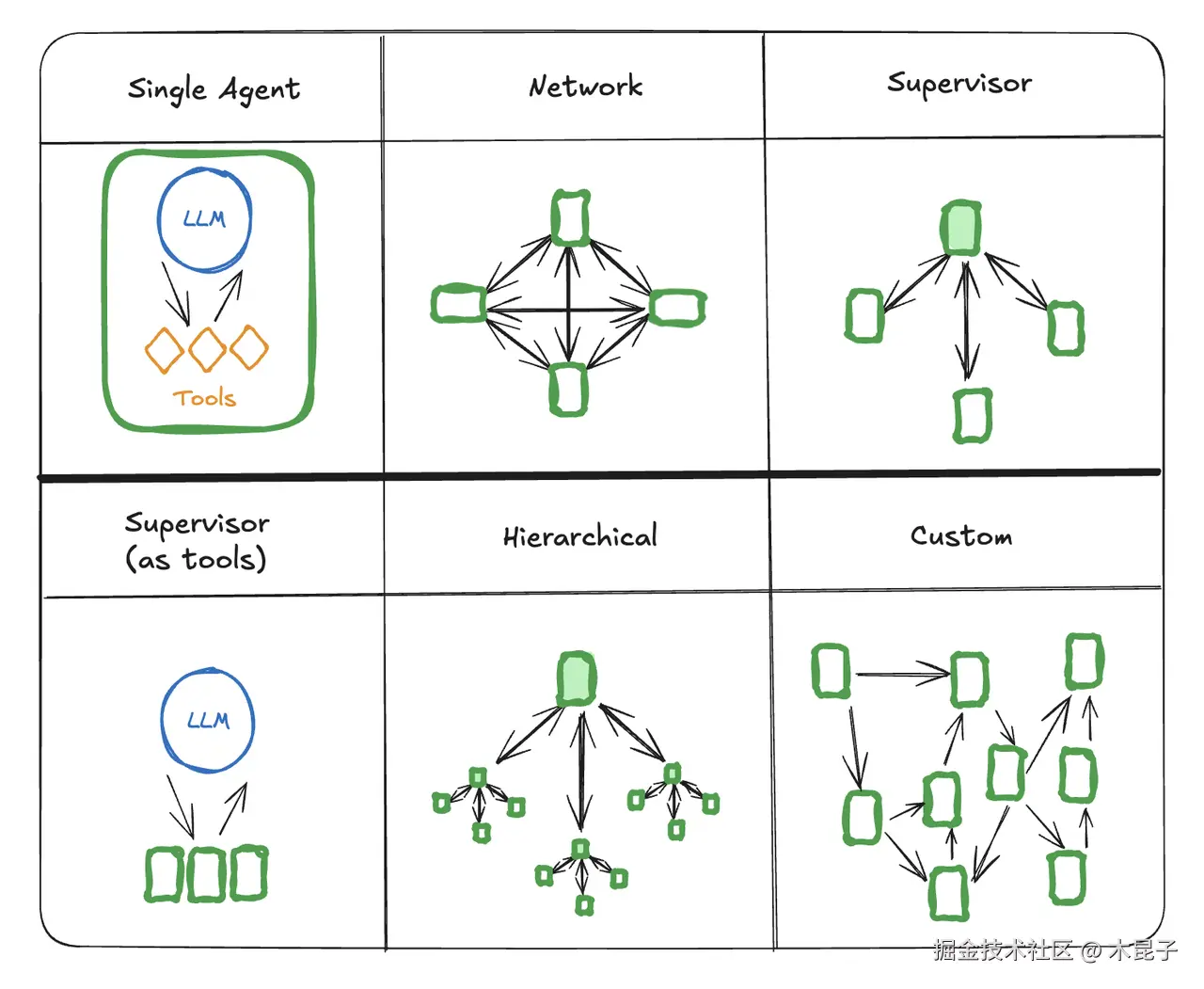
LangGraph 是基于LangChain生态构建,它强调「状态图(StateGraph)」和「可追溯记忆(Checkpoint Memory)」,它提出了几种Multi-Agent模式,适用于不同的调用逻辑和控制流需求:
网络(Network)模式
主管(Supervisor)模式
主管(Supervisor as Tools 工具调用)模式
分层(Hierarchical)模式
自定义(Custom Workflow)模式(对应本文案例)
源码参考:参与协作的四个智能体,以及具体协作控制逻辑代码,详见github.com/MuKunZiAI/c…
本文总结:本文针对高考信息智能查询的业务场景,采用LangGraph框架验证多智能体协作机制,通过状态图StataGraph来管理节点+条件边组成协作执行路径,通过Checkpoint Memory来管理多轮对话上下文和跨智能体结构化参数传递,最后分享了LangGraph官网的几种典型协作模式
本文作者:Chaiys
本文原载:公众号“木昆子记录AI”

