三角符文免安装绿色中文版
787M · 2025-11-08

英伟达这几年很火。因为 AI 的带动,它几乎成为全球最受关注的公司。
我们总是会在网上看到和英伟达有关的一些名词,例如:
A100、B100、H100、GH200、GB200、NVLINK、NVSwitch、DGX、HGX、Quantum、Spectrum、BlueField、CUDA 等等。
这些名词看多了,就有点晕。搞不懂到底是什么,有什么关系。
今天这篇文章,小枣君就给大家详细梳理一下这些名词概念,顺便普及一下相关的知识。
这些名词,应该是大家最常见的。
没错,这些都是 AI 算力卡,也就是 GPU 卡的型号。

英伟达的 GPU,每隔几年就会出一个新的架构。每个架构,都会以一个著名科学家的名字命名,如下所示:
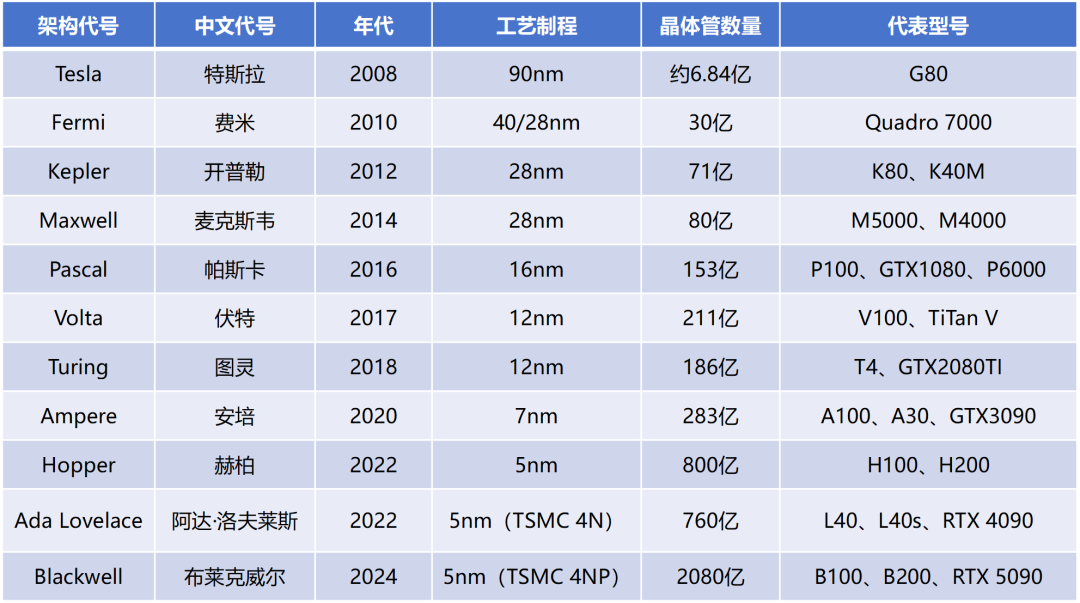
所以,基于某个架构的卡,一般就会以这个架构名称的首字母开头(游戏显卡除外)。
例如,基于 Volta(伏特)架构的 V100,基于 Ampere(安培)架构的 A100,基于 Hopper(赫伯)架构的 H100、H200,基于 Blackwell(布莱克威尔)架构的 B100、B200 等。
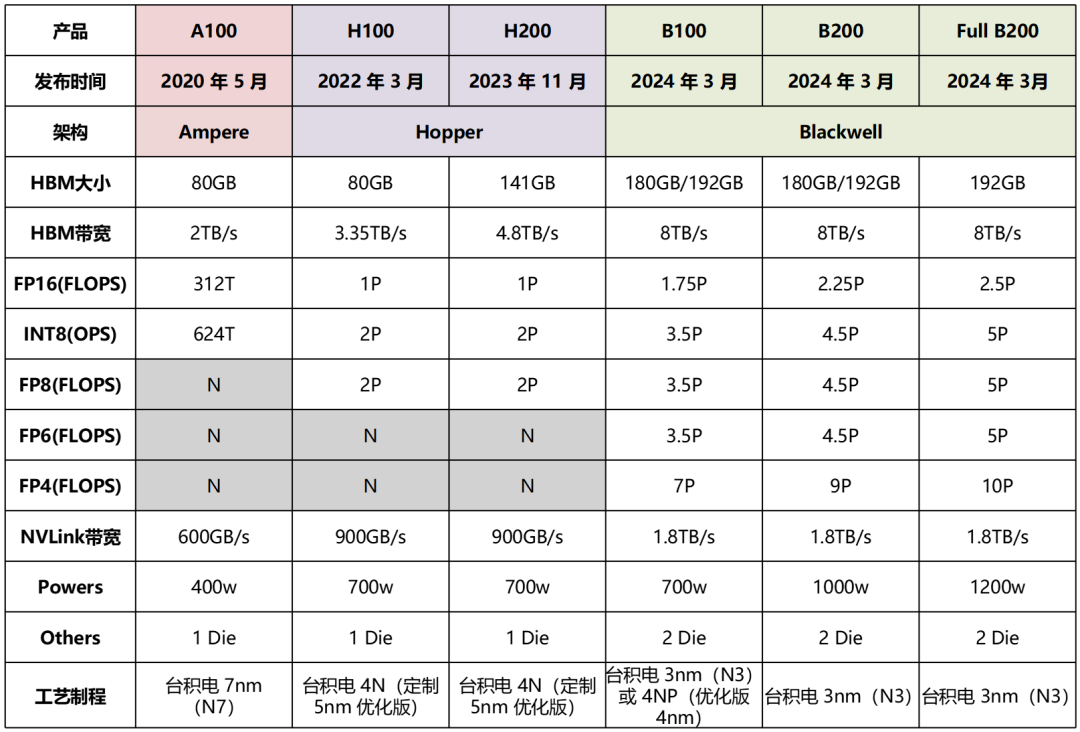
某 200 一般是某 100 的升级版。例如 H200,就是 H100 的升级版(采用了 HBM3e 内存等升级)。
L40 和 L40s 名字稍微有点特别,两者基于 Ada Lovelace(世界上第一个女程序员的名字)架构,后者是前者的升级版。两个卡都是针对数据中心市场推出的,主打低成本和性价比。
还有 1 个型号大家应该比较熟悉 ——H20。
这是英伟达因为美国出口限制而推出的阉割版(特供版)。据说 B200 也会有对应的阉割版 B20。
英伟达的下一代 AI 平台是 Rubin(罗宾),计划于 2026 年推出。大家一开始以为下一代 GPU 就是 R100、R200。但英伟达给出的路线图,又说是 X100。所以,还有待观望。
2028 年,英伟达会推出下下一代平台 ——Feynman(费曼)。
GPU 是英伟达的算力核心硬件单元。但他们并不是只有 GPU。围绕 GPU,他们还有很多的产品和解决方案。
英伟达早期的时候是和 IBM POWER CPU 合作,后来,可能是感觉 IBM 不给力,于是自己开始研发 CPU。例如,基于 ARM 架构研发的 Grace CPU(Vera CPU 在路上)。
英伟达采用 NVLink 技术,将 GPU 和 CPU 进行配对,就变成了所谓的超级芯片平台(Superchip)。
例如 GH200、GB200,以及不久前新发布的 GB300(Blackwell Ultra)。
由一个 Grace CPU 和两个 Blackwell B200 GPU 组成的平台,就是 GB200(取 Grace 和 Blackwell 的首字母),据说性能是 H100 的 7 倍。

类似的,GH200,就是 Grace CPU 和 Hopper GPU 的组合搭配。
再往上一个层级,就是计算机了。其实刚才 GB200,已经是个计算机了。
基于刚才的各种芯片平台,英伟达构建了对应的计算机平台,或者说,叫做超级计算机平台,包括 DGX、EGX、IGX、HGX、MGX 等。
具体的区别如下,我就不多解释了,看下表:

DGX 还是见得比较多。当年黄仁勋送给 OpenAI 的,就是第一代的 DGX-1。

现在的 DGX,基本上都是土豪金配色,价格也很昂贵。
面向桌面市场,英伟达还推出了 DGX Spark 和 DGX Station,相当于工作站。

接下来,要涉及到通信方面的技术了。
之前小枣君给大家介绍超节点的时候(最近很火的“超节点”,到底是干啥的?),提到过 NVLINK。
NVLINK 是英伟达推出的 GPU 卡间互连技术,主要是取代 PCIe。刚才也提到,CPU 和 GPU 之间,也是 NVLINK 技术。
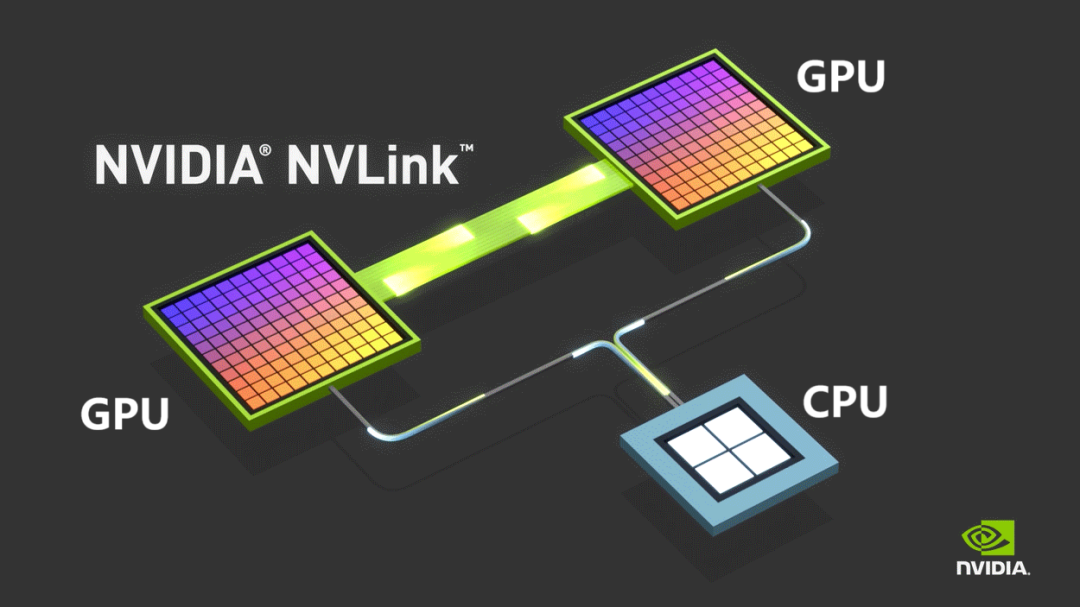
NVLINK 多节点,就不好直连了,要引入交换芯片。于是,就有了 NVLink Switch,也叫 NVSwitch。后来,芯片又变成了设备。
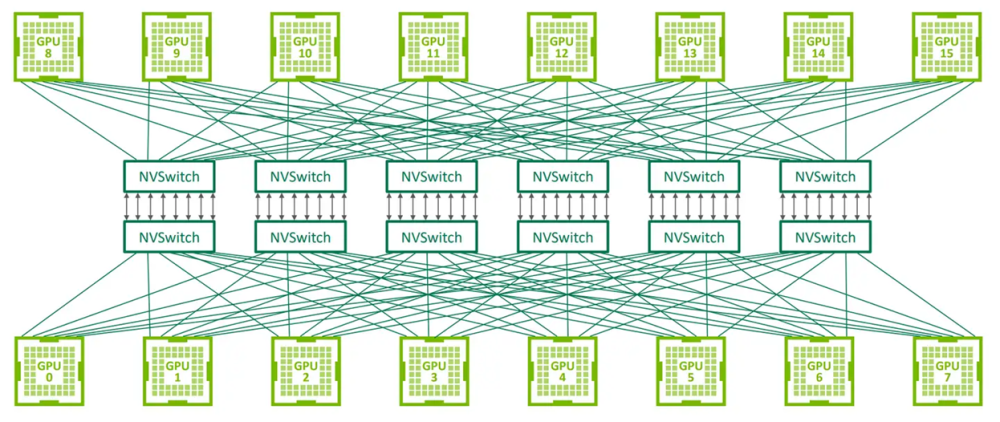
NVLINK 可以把很多的 GPU 连起来,组成看似很多计算机,但实际上属于一个逻辑节点(超节点)的平台。
近年来,我们经常听说 DGX GB200 NVL72。
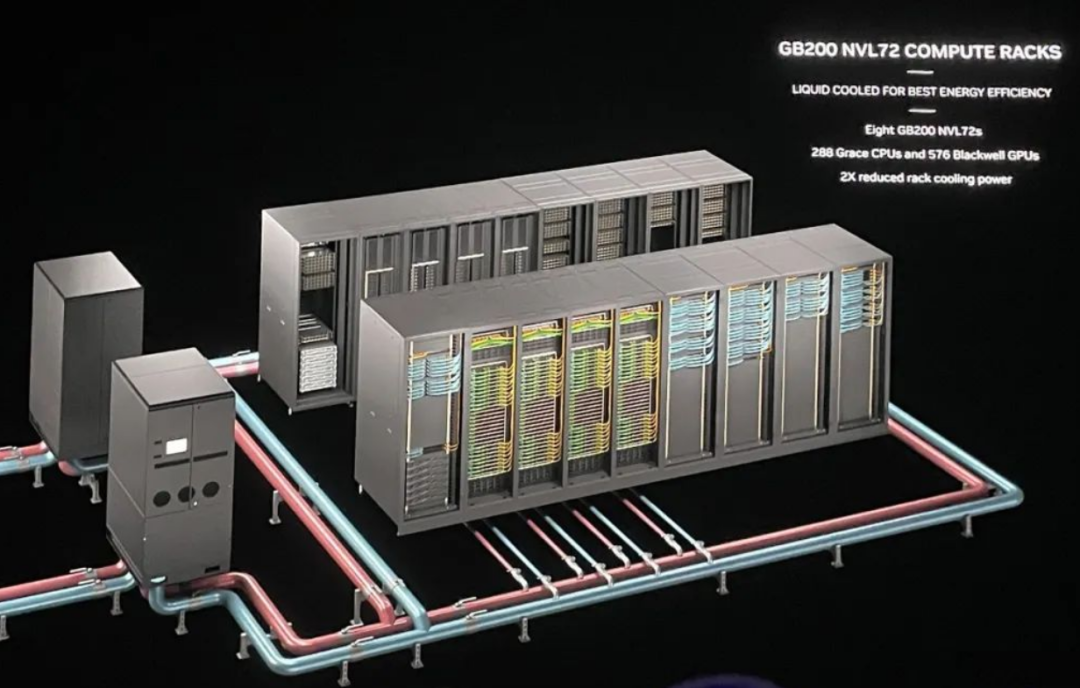
DGX GB200 NVL72,采用了 NVLINK5,包含了 18 个 GB200 Compute Tray(计算托架),以及 9 个 NVLink-network Switch Tray(网络交换托架)。如下图所示:

每个 Compute Tray 包括 2 颗 GB200 超级芯片。所以,就是 36 个 Grace CPU(18×2),72 个 B200 GPU(18×2×2)。
8 个 DGX GB200 NVL72,又可以组成一个 576 个 GPU 的 SuperPod 超节点。
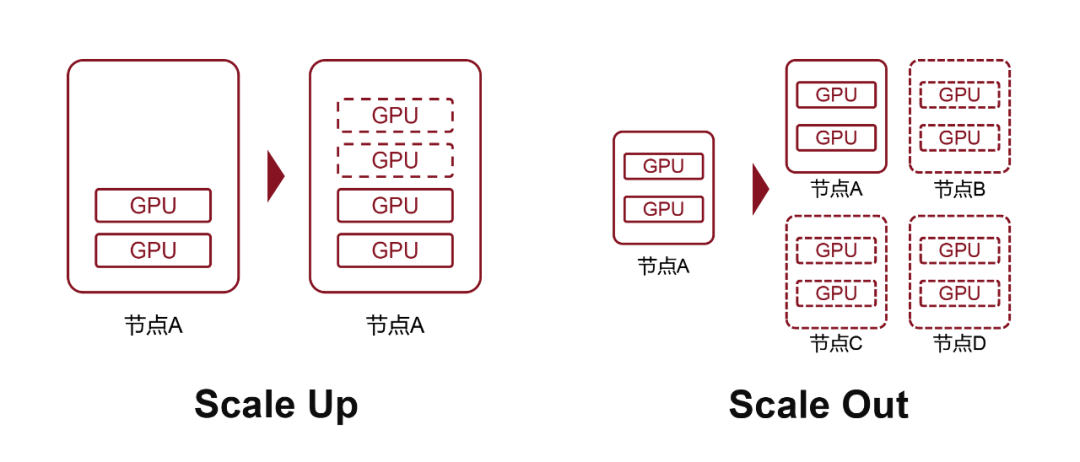
单节点内,不断加 GPU,是 Scale Up(纵向扩展)。单节点到了一定规模,就不好再增加了。就要增加节点数量,搞节点与节点之间的互连,那就是 Scale Out(横向扩展)。
Scale Out,英伟达也有解决方案,那就是 InfiniBand(IB)技术。
InfiniBand 以前是 Mellanox 公司的。英伟达布局深远,2019 年把 Mellanox 收购了,InfiniBand 就成了英伟达的私有技术。
InfiniBand 是技术名词,不是产品名词。英伟达基于 InfiniBand 推出的产品平台是 NVIDIA Quantum(“量子”的意思)。
例如,2024 年 3 月,英伟达发布的 Quantum-X800 网络交换机平台,端到端吞吐量能够达到 800Gbps。平台包括了含 Quantum Q3400 交换机、ConnectX-8 SuperNIC 网卡等硬件。
这些硬件,也都是有系列的。Quantum-X800 的上一代,是 Quantum-2。ConnectX-8 的前代,有 ConnectX-6、ConnectX-7 等。

ConnectX 高速网卡也是来自 Mellanox。
Scale Out 的两大解决方案,除了 InfiniBand,还有以太网。英伟达以太网这边也没放过,也有产品,就是 Spectrum-X800。(Spectrum 是“光谱”的意思。)
Spectrum-X800 包括了 Spectrum SN5600 交换机、BlueField-3 SuperNIC 网卡等硬件产品,吞吐量同样高达 800Gbps。

BlueField 是这些年很火的 DPU。英伟达将 Mellanox 的 ConnectX 网卡技术与自己的已有技术相结合,于 2020 年正式推出了 BlueField-2 DPU 和 BlueField-2X DPU。现在演进到了 BlueField-3。
对了,前段时间,英伟达还发布了 CPO 光电一体化封装网络交换机 Spectrum-X Photonics 和 Quantum-X Photonics。

英伟达还有一些其它的网卡、连接器、线缆等配件,就不逐个介绍了。
黄教主前段时间透露,新一代的 Rubin 平台发布时,据说会带来 NVLink 6、ConnectX-9 SuperNIC 和 Quantum(Spectrum)-X1600。可以期待一下。
刚才介绍的,是英伟达的算力硬件平台家族,以及通信网络家族。
再看一个软件方面的名词 —— 大名鼎鼎的 CUDA。
英伟达的硬件和网络做得很牛,但实际上,最被视为核心竞争壁垒的,反而是这个 CUDA。
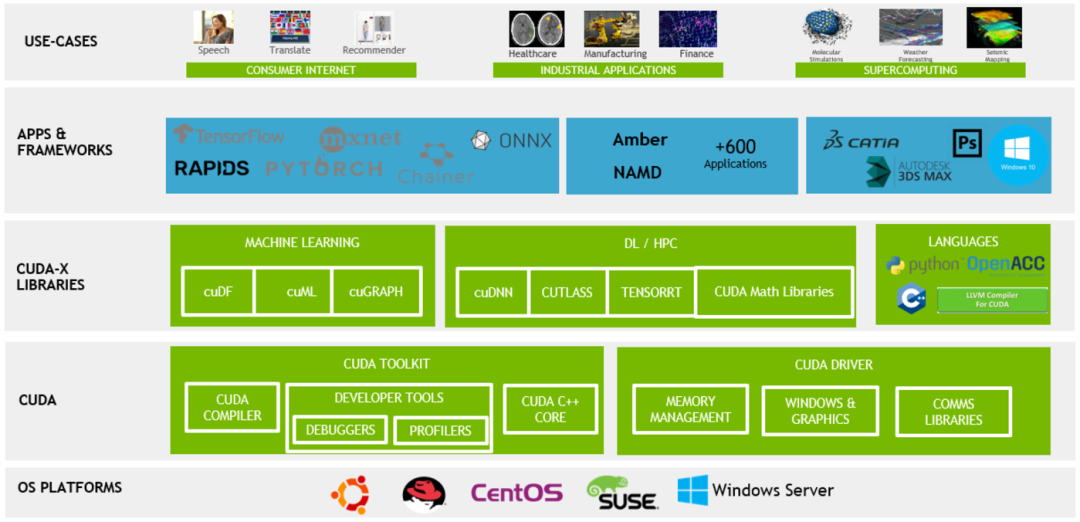
CUDA(Compute Unified Device Architecture,计算统一设备架构),是英伟达在 2006 年推出的并行计算平台和编程模型。它让开发者能够直接在 GPU 上编写代码,从而大幅提升计算速度。
如今,CUDA 就像是智算开发的操作系统,集编程模型、编译器、API、库和工具于一体,有利于用户更好地发挥英伟达硬件的能力。
CUDA 不仅是个工具,更形成了强大的 AI 开发生态。它是英伟达整个业务体系的神经中枢。
现在很多 AI 开发都依赖于英伟达的硬件和 CUDA,换硬件其实也不是很难,但是,生态迁移更加痛苦。
好啦,关于英伟达的主要产品体系和命名规则,就介绍到这里。
在不同的领域,英伟达会基于这些核心产品,构建不同的解决方案。有的时候,也会衍生出一些升级版或阉割版,大家注意一下就行。
这个公司在 AI 领域牢牢占据核心地位,希望能有更多的企业,站出来向它发出挑战。
本文来自微信公众号:鲜枣课堂(ID:xzclasscom),作者:小枣君

