







Slashrun
100.37M · 2026-04-09

算法是独立解决问题的思想和方法
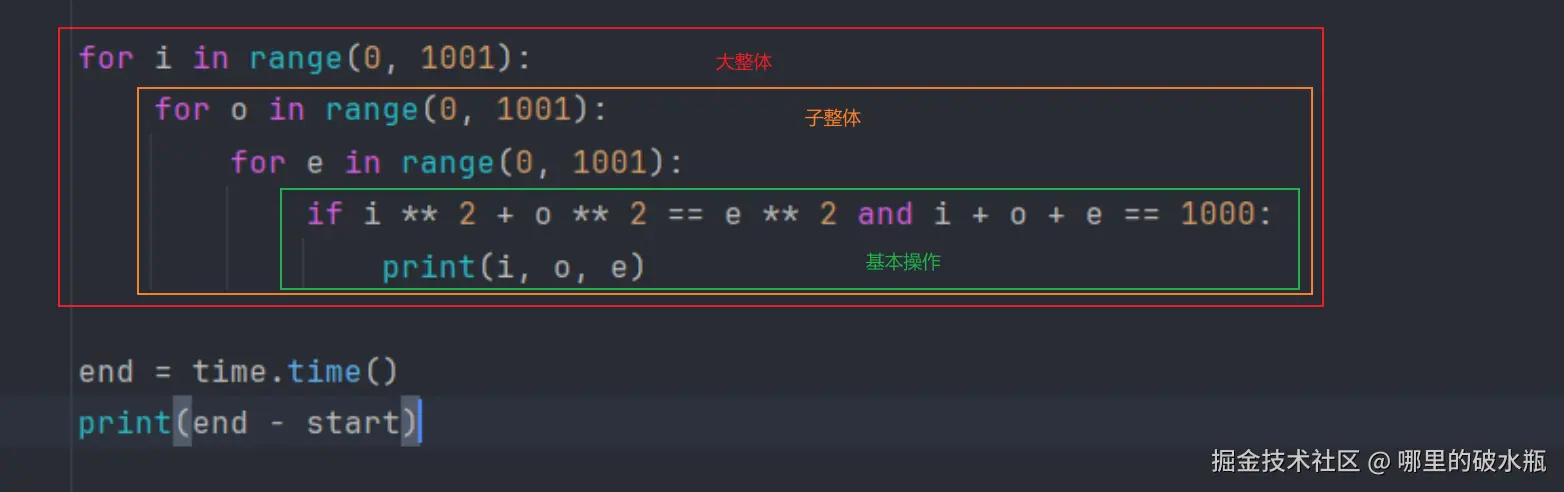
import time
start = time.time()
for i in range(0, 1001):
for o in range(0, 1001):
for e in range(0, 1001):
if i + o + e == 1000: and i ** 2 + o ** 2 == e ** 2 # 65
# if i ** 2 + o ** 2 == e ** 2 and i + o + e == 1000: # 565
print(i, o, e)
end = time.time()
print(end - start)
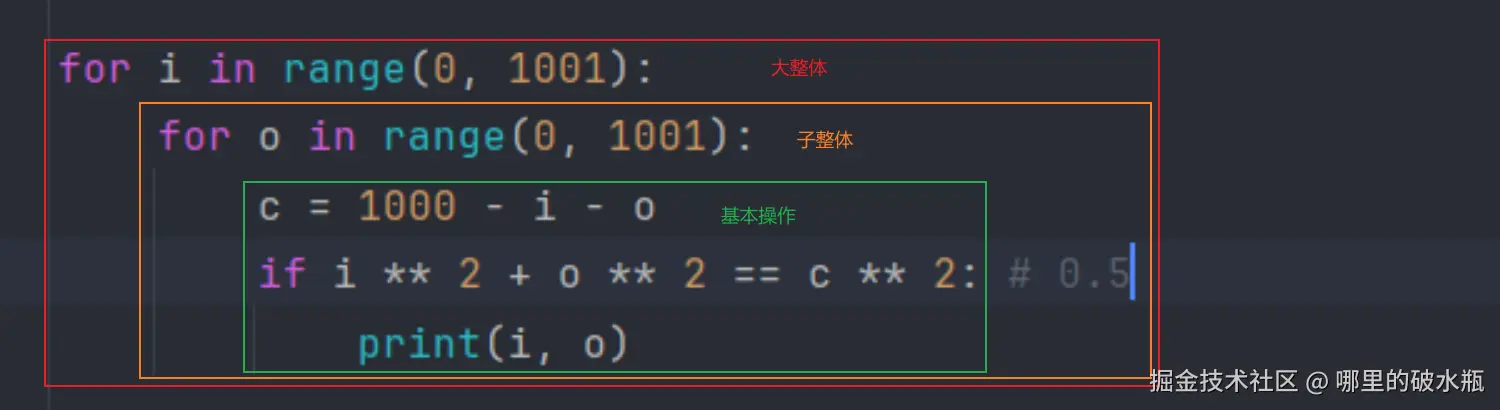
import time
start = time.time()
for i in range(0, 1001):
for o in range(0, 1001):
c = 1000 - i - o
if i ** 2 + o ** 2 == c ** 2: # 0.5
print(i, o)
end = time.time()
print(end - start)
判断算法优劣的方式
下图:1001³ * 9 * 每步执行时间
下图:1001² * 9 * 每步执行时间
适用于衡量算法的优劣的,一般采用大O标记法,把次要条件都忽略,最终形成的表达式就叫大O标记法
计算规则
分析的时候,只参考主要条件,忽略次要条件和常数项。
如果没有特别的说明,我们分析时间复杂度,指的是最坏的时间复杂度。
| 执行次数函数举例 | 阶 | 非正式术语 |
|---|---|---|
| 12 | O(1) | 常数阶 |
| 2n+3 | O(n) | 线性阶 |
| 3n2+2n+1 | O(n2) | 平方阶 |
| 5log2n+20 | O(logn) | 对数阶 |
| 6n3+2n2+3n+4 | O(n3) | 立方阶 |
所消耗的时间从小到大:
O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(n3)
时间复杂度越低,效率越高
备注:
空间复杂度是对一个算法,在运行过程中临时占用存储空间大小的度量
类似于时间复杂度,一个算法的空间复杂度S(n)定义为该算法所耗费的存储空间,也使用大O标记法。
常见的有
O(1) < O(logn) < O(n) < O(n2) < O(n3)
因为图中的 0,无论递增到多少,永远都是会用一个空间来覆盖另一个空间,所以是 0¹
每次循环一个数据,空间都会持续增加,就是线性阶
内存是以字节为基本存储单位的, 每个基本存储空间都有自己的地址(注意:一个内存地址代表一个字节(8bit)的存储空间)。
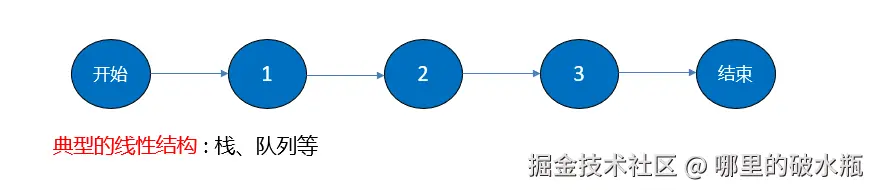
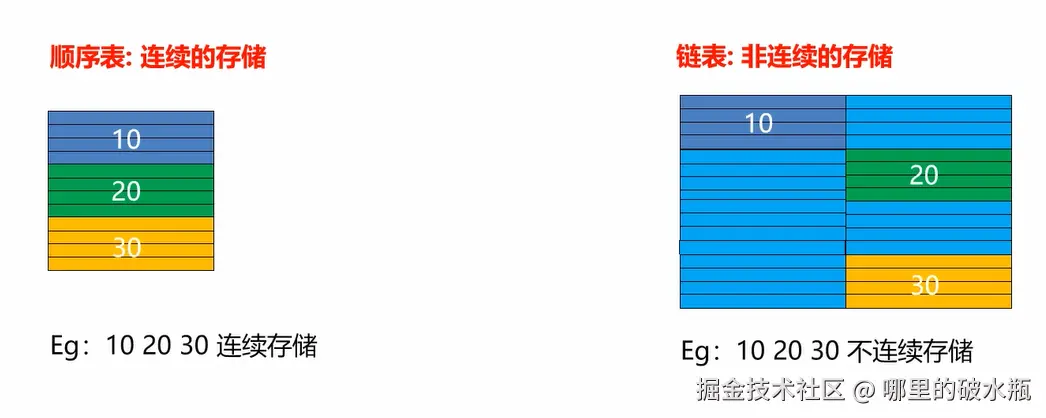
线性结构的特点:
非线性结构的特点:
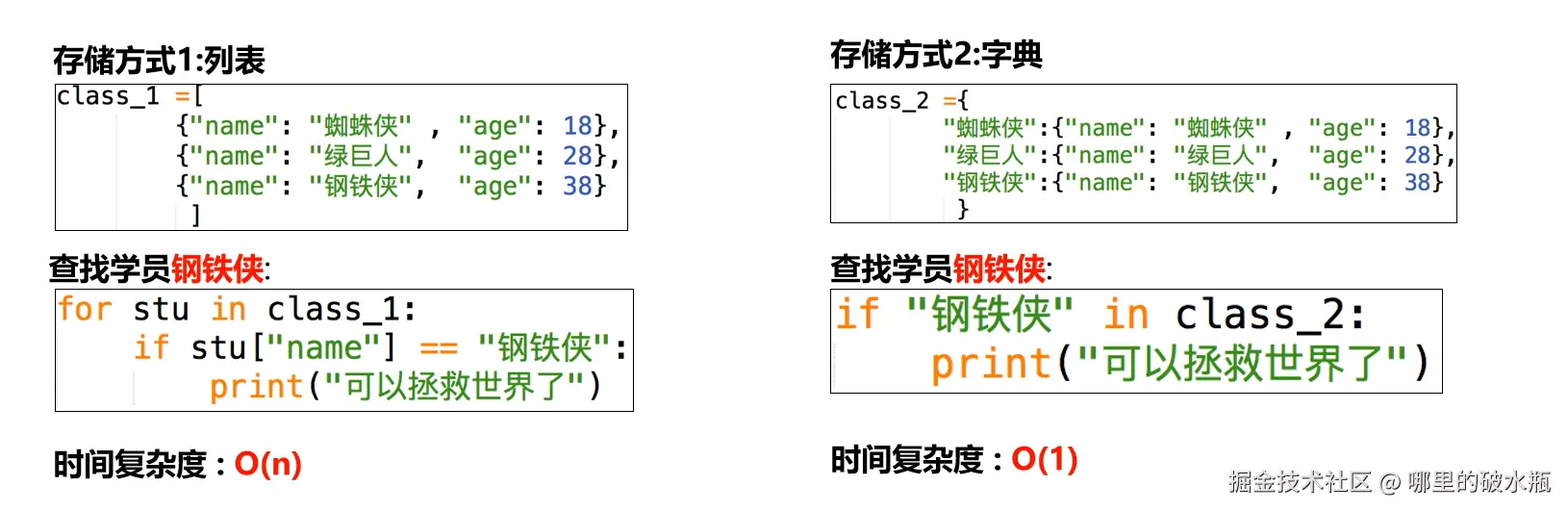
线性结构的实际存储方式,分为两种:
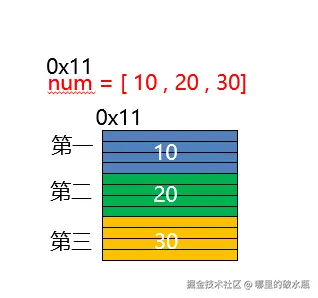
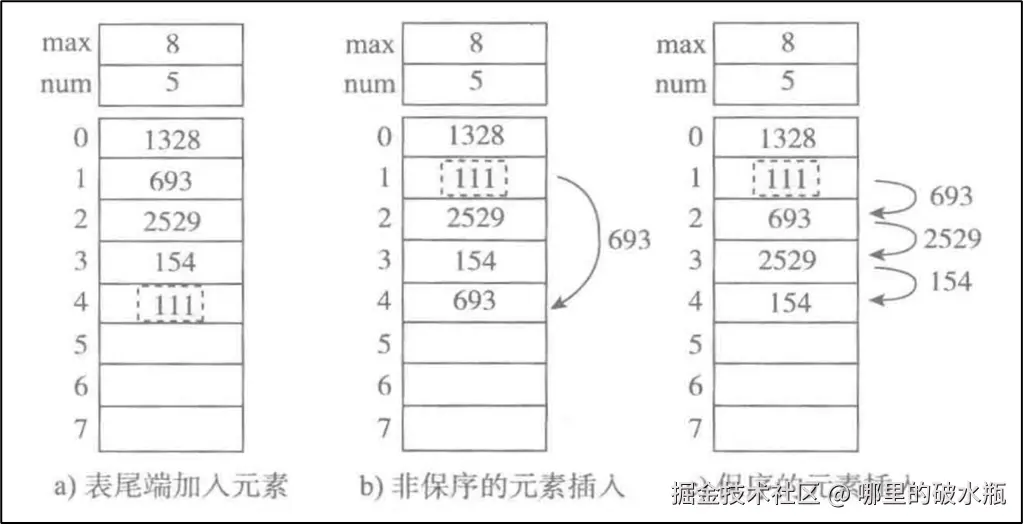
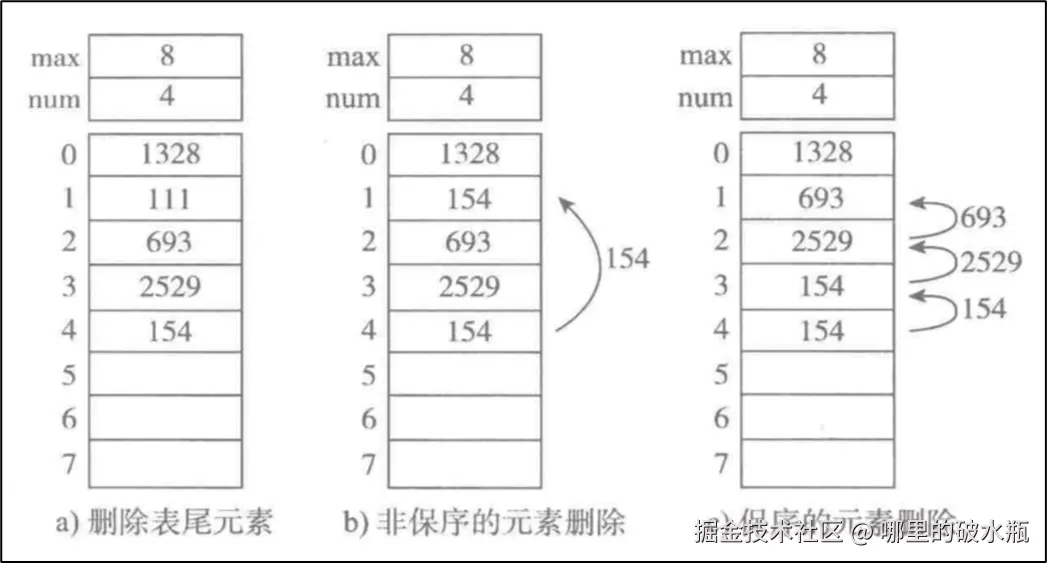
必须是有序的线性结构,元素之间没有间隙,并且可以通过索引访问,元素的占用空间是一样的。
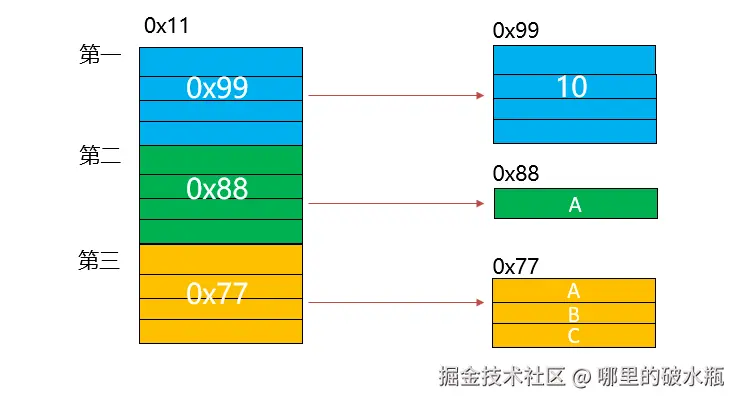
地址的大小为4字节是固定的 , 我们可以不存储数据 , 而是存储地址,这样就解决了,占用空间大小不一样的问题。左边存地址,右边存数据。
无论一体式结构还是分离式结构,顺序表在获取数据的时候直接通过下标偏移就可以找到数据所在空间的地址 , 而无需遍历后才可以获取地址 . 所以顺序表在获取地址操作时的时间复杂度 : O(1)
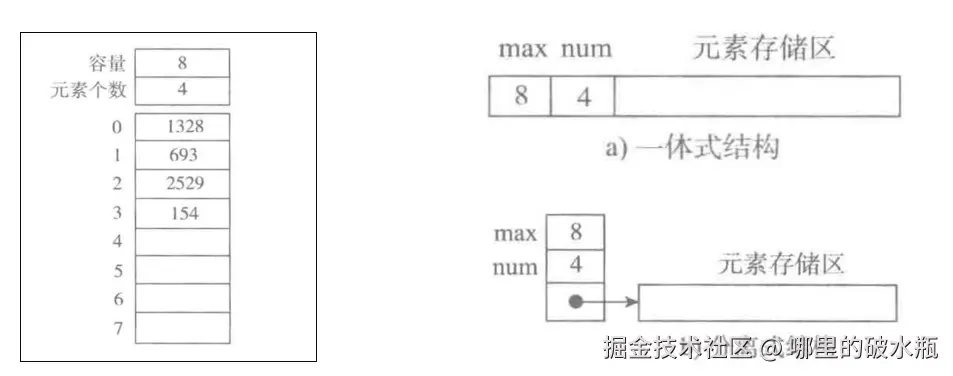
存储结构
顺序表的完整信息包括两部分:
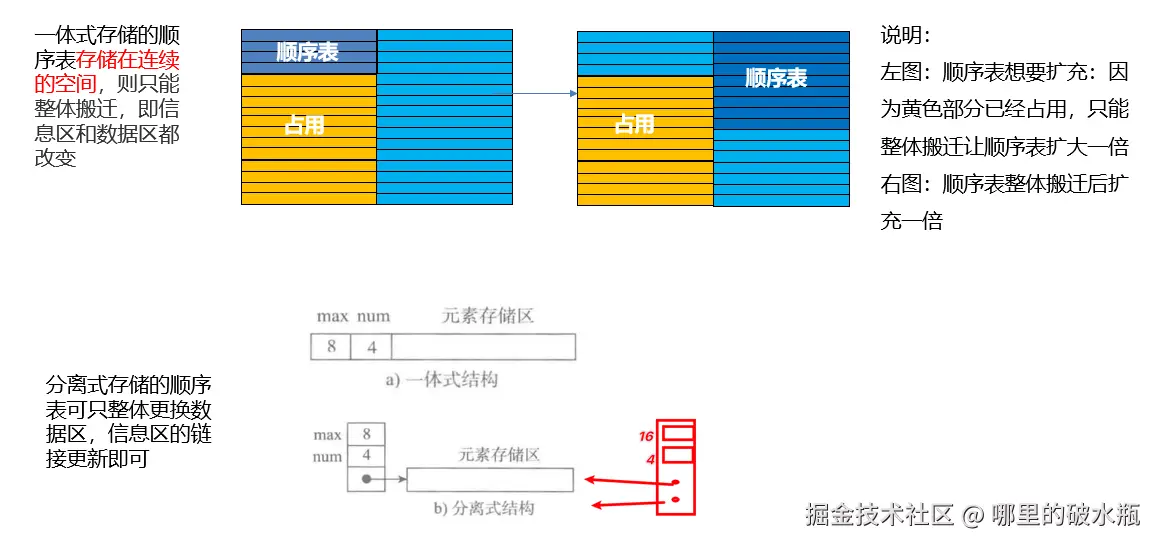
扩充
扩充的两种策略
特点:节省空间,但是扩充操作频繁,操作次数多。
特点:减少了扩充操作的执行次数,但可能会浪费空间资源 , 以空间换时间,推荐的方式
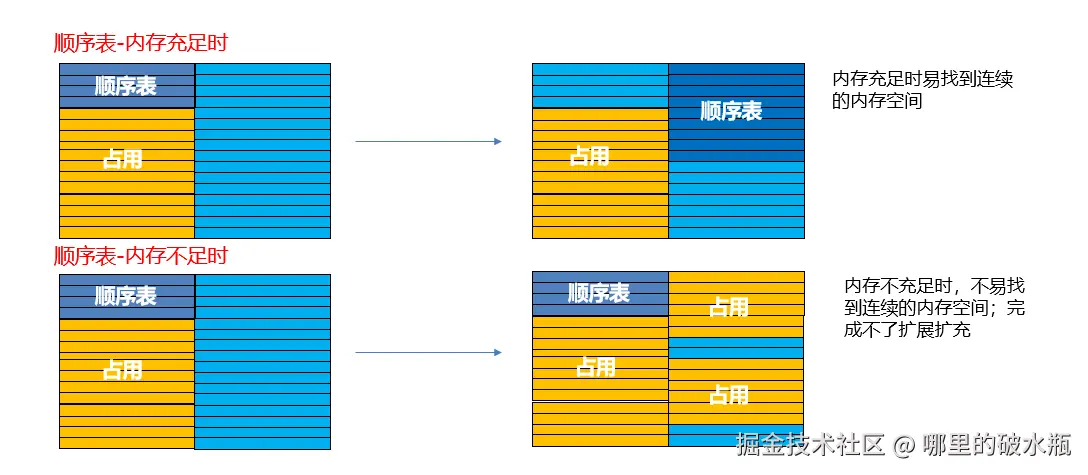
如果是一体式的,在扩容的时候,需要整体搬迁。
如果是分离式的,在扩容的时候,只需要搬迁数据区,重新关联信息区就可以了。
顺序表存储时需要连续的内存空间,当要扩充顺序表时会出现以下两种情况:
当空间不足,很有可能无法完成扩容。
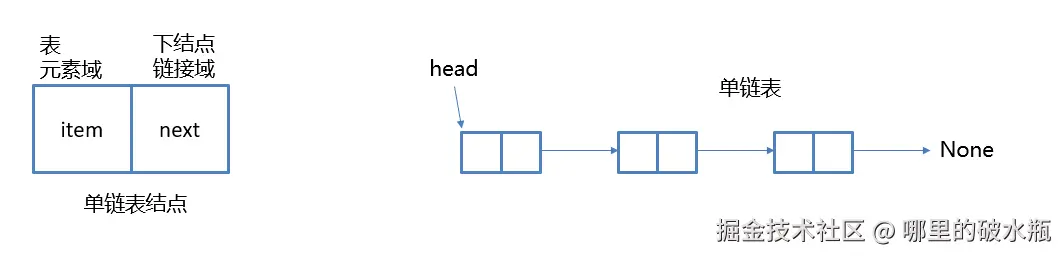
不需要连续的存储空间
单链表(单向链表)是链表的一种形式,每个结点包含两个域:元素域和链接域 . 这个链接指向链表中的下一个结点 , 而最后一个结点的链接域则指向一个空值None。
循环单链表,最后一个指向第一个。双向循环依旧如此。
# 定义节点类
class SingleNode:
def __init__(self, item):
self.item = item # 数据域
self.next = None # 链接域
# 定义链表类
class SingleLinkedList:
def __init__(self, head=None):
self.head = head # 头结点
def is_empty(self):
return self.head is None
def length(self):
cur = self.head
count = 0
while cur is not None:
count += 1
cur = cur.next
return count
def travel(self):
cur = self.head
while cur is not None:
print(cur.item)
cur = cur.next
def add(self, item):
# 创建新的节点
new_node = SingleNode(item)
# 将新节点的链接域指向头结点
new_node.next = self.head
# 将头结点指向新节点
self.head = new_node
def append(self, item):
# 创建新的节点
new_node = SingleNode(item)
if self.is_empty():
# 链表为空
self.head = new_node
else:
cur = self.head
while cur.next is not None:
cur = cur.next
cur.next = new_node
def insert(self, pos, item):
# 插入位置小于等于0,则插入头部
if pos <= 0:
self.add(item)
return
# 插入位置大于单链表长度,则插入尾部
if pos >= self.length():
self.append(item)
return
# 插入位置在单链表长度中间
cur = self.head
count = 0
# 查找到要插入的位置
while count < pos - 1:
count += 1
cur = cur.next
# 此时,cur指向要插入位置的前一个节点
new_node = SingleNode(item)
# 注意赋值问题,左侧不会取结果
new_node.next = cur.next
cur.next = new_node
def remove(self, item):
cur = self.head
pre = None
while cur is not None:
# 找到要删除的节点
if cur.item == item:
# 判断是否是头结点
if cur == self.head:
self.head = cur.next
else:
pre.next = cur.next
break
else:
# 走到这,说明不是要删除的节点
pre = cur
cur = cur.next
def search(self, item):
cur = self.head
while cur is not None:
if cur.item == item:
return True
cur = cur.next
return False
if __name__ == '__main__':
node = SingleNode('乔峰')
print(node)
print(node.item) # 打印数据域
print(node.next) # 打印链接域
linked_list = SingleLinkedList(node)
print(linked_list.head) # 头结点是空的
# 测试获取长度
print(linked_list.length())
linked_list.add('令狐冲')
linked_list.append('张三')
linked_list.insert(2, '李四')
linked_list.travel()
linked_list.remove('张三')
print('*' * 20)
linked_list.travel()
print(linked_list.search('李四'))
| 操作 | 链表 | 顺序表 |
|---|---|---|
| 访问元素 | O(n) | O(1) |
| 在头部插入 / 删除 | O(1) | O(n) |
| 在尾部插入 / 删除 | O(n) | O(1) |
| 在中间插入 / 删除 | O(n) | O(n) |
具有相同关键字的纪录经过排序后,相对位置保持不变,这样的算法是稳定性算法
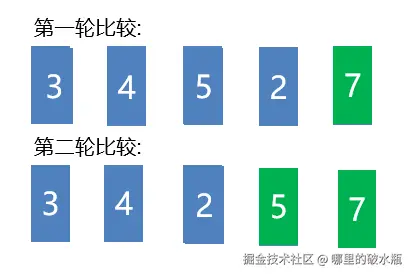
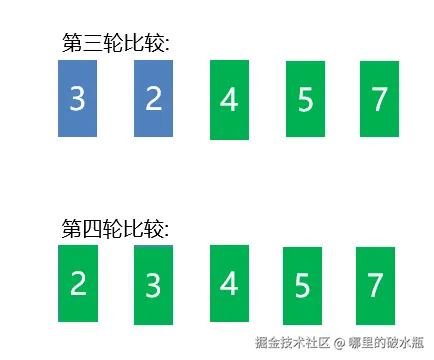
原理:相邻元素两两比较,大的往后走,每轮结束后,最大的就在最后面。重复直至完成。
核心:
def bubble_sort(my_list):
# 1. 获取列表的长度
n = len(my_list)
# 2. 定义外循环,外循环控制,比较的轮数,内循环控制,比较的次数
for i in range(n - 1): # i 的值,0,1,2,3
for j in range(n - 1 - i): # j 的值,0123,012,01,0
# 比较
if my_list[j] > my_list[j + 1]:
# 交换
my_list[j], my_list[j + 1] = my_list[j + 1], my_list[j]
if __name__ == '__main__':
l = [5, 3, 4, 7, 2]
print(f'列表排序前的结果是:{l}')
bubble_sort(l)
print(f'列表排序后的结果是:{l}')
遍历一遍发现没有任何元素发生了位置交换,终止排序
算法稳定性 : 稳定算法
减少了时间复杂度
def bubble_sort(my_list):
n = len(my_list)
for i in range(n - 1):
# 定义变量,记录每轮交换次数
count = 0
for j in range(n - 1 - i):
if my_list[j] > my_list[j + 1]:
# 交换+1
count += 1
my_list[j], my_list[j + 1] = my_list[j + 1], my_list[j]
# 如果没有发生交换,则提前结束
if count == 0:
break
if __name__ == '__main__':
l = [0, 3, 4, 7, 2]
print(f'列表排序前的结果是:{l}')
bubble_sort(l)
print(f'列表排序后的结果是:{l}')
原理:假设第1个元素为最小值,定义变量 min_index 用于记录剩下元素中,最小值的索引,第一轮比较完毕后,如果min_index 的位置发生改变,交换变量即可,最终最小值在最小索引处。
核心:
def select_sort(my_list):
n = len(my_list)
for i in range(n - 1):
# 假设最小值为第一个元素
min_index = i
for j in range(i + 1, n):
if my_list[j] < my_list[min_index]:
min_index = j
if min_index != i:
my_list[i], my_list[min_index] = my_list[min_index], my_list[i]
if __name__ == '__main__':
l = [0, 3, 4, 7, 2]
print(f'列表排序前的结果是:{l}')
select_sort(l)
print(f'列表排序后的结果是:{l}')
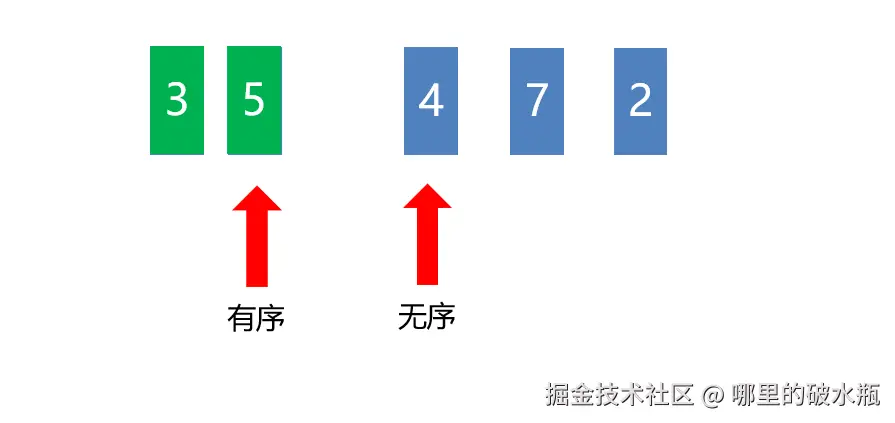
有2个序列,有序序列和无序序列, 将无序序列中的每一个元素插入到有序序列中
原理:把列表分成有序和无序两部分,每次从无序数据中拿到第一个元素,然后放到对应的有序列表中。
属于稳定算法,元素相同的情况下。是不会更换位置的。
def select_sort(my_list):
n = len(my_list)
for i in range(1, n):
for j in range(i, 0, -1):
if my_list[j] < my_list[j - 1]:
my_list[j - 1], my_list[j] = my_list[j], my_list[j - 1]
if __name__ == '__main__':
l = [0, 3, 4, 7, 2]
print(f'列表排序前的结果是:{l}')
select_sort(l)
print(f'列表排序后的结果是:{l}')
原理: 二分查找也叫折半查找,是一种效率比较高的检索算法。
前提:数据必须是有序的,升序,降序均可。
原理:假设数据是升序的。
def binary_search(my_list, item):
# 1. 获取列表的长度
n = len(my_list)
# 2. 如果列表为空,则返回False
if n == 0:
return False
# 3. 获取中间索引
mid = n // 2
# 4. 如果中间的元素等于要查找的元素,则返回True
if my_list[mid] == item:
return True
# 5. 如果中间的元素大于要查找的元素,则将列表的前半部分作为新的列表进行递归查找
if my_list[mid] > item:
return binary_search(my_list[:mid], item)
if my_list[mid] < item:
return binary_search(my_list[mid + 1:], item)
return False
if __name__ == '__main__':
l = [2, 3, 5, 9, 13, 27, 31, 39, 55]
print(binary_search(l, 22))
def binary_search(my_list, item):
# 1 设置初始化搜素空间 起始位置start 结束位置end
start = 0
end = len(my_list) - 1
# 2 循环检索
# 2-1 获取中间值索引 mid = (start + end) // 2
# 2-2 item等于中间值 返回True
# 2-3 item小于中间值 在前半部空间搜索 修改搜索空间 end /mid - 1
# 2-4 item大于中间值 在后半部空间搜索 修改搜索空间 start /mid + 1
while start <= end:
mid = (start + end) // 2
if item == my_list[mid]:
return True
if item < my_list[mid]:
end = mid - 1
elif item > my_list[mid]:
start = mid + 1
return False
if __name__ == '__main__':
l = [2, 3, 5, 9, 13, 27, 31, 39, 55]
print(binary_search(l, 31))
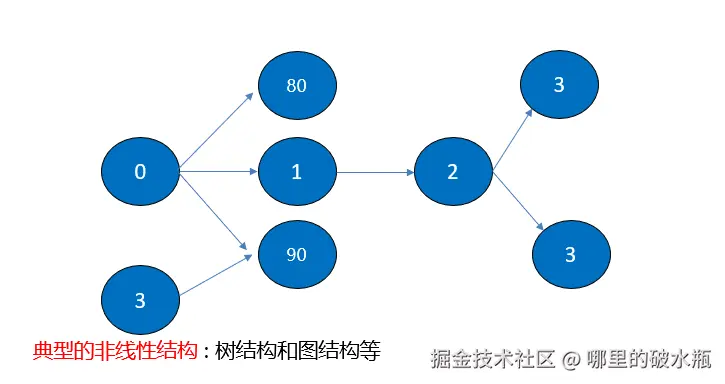
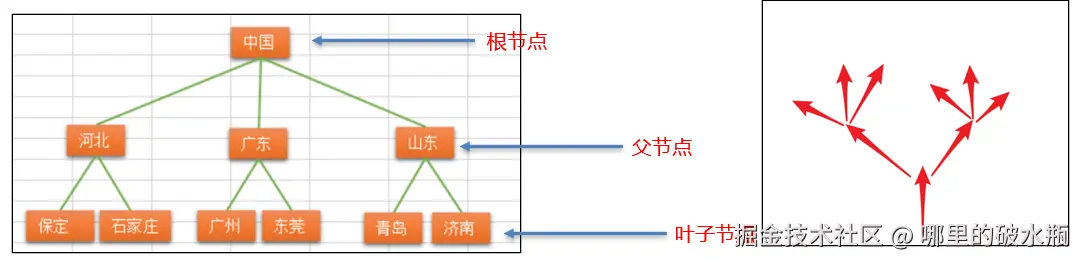
树(英语:tree)就是一种非线性结构
它是用来模拟具有树状结构性质的数据集合. 它是由n(n>=1)个有限节点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的. 它具有以下的特点:
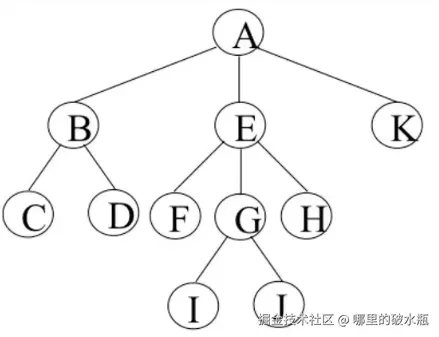
无序树:树中任意节点的子节点之间没有顺序关系,这种树称为无序树,也称为自由树
有序树:树中任意节点的子节点之间有顺序关系,这种树称为有序树
有序树:
霍夫曼树(用于信息编码):带权路径最短的二叉树称为哈夫曼树或最优二叉树
B树:一种对读写操作进行优化的自平衡的二叉查找树,能够保持数据有序,拥有多于两个的子树
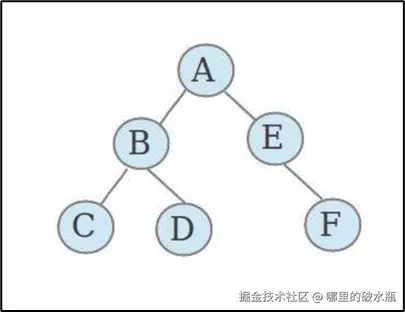
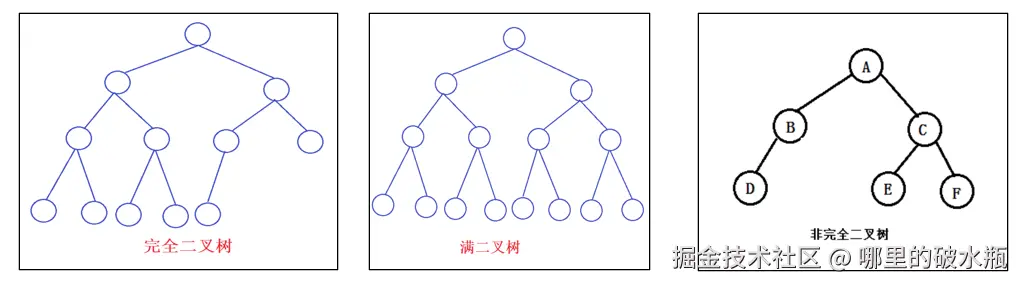
二叉树:每个节点最多含有两个子树的树称为二叉树
完全二叉树:对于一颗二叉树,假设其深度为d(d>1)。除了第d层外,其它各层的节点数目均已达最大值,且第d层所有节点从左向右连续地紧密排列,这样的二叉树被称为完全二叉树,其中满二叉树的定义是所有叶节点都在最底层的完全二叉树
平衡二叉树(AVL树):当且仅当任何节点的两棵子树的高度差不大于1的二叉树 为什么需要平衡二叉树:防止树退化为链表
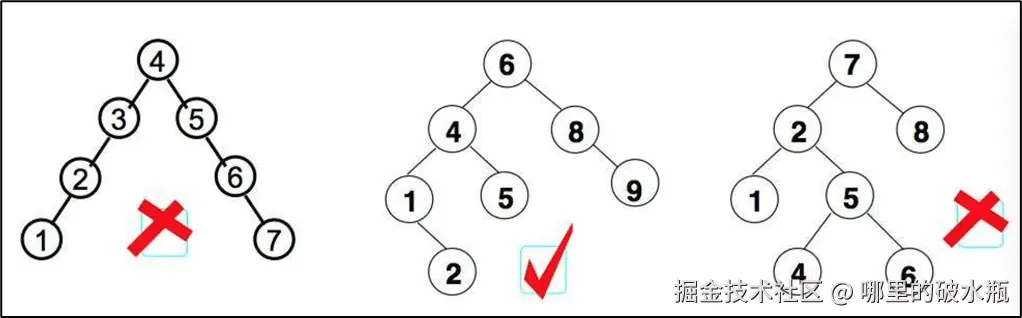
排序二叉树(二叉查找树(英语:Binary Search Tree),也称二叉搜索树、有序二叉树)
排序二叉树(BST)的要求:
排序二叉树包含空树
注1:一般称为二叉排序树
注2:中序遍历排序二叉树,会得到一个有序的序列
1、二叉树可由很多类型:满二叉树、平衡二叉树、排序二叉树各自作用?
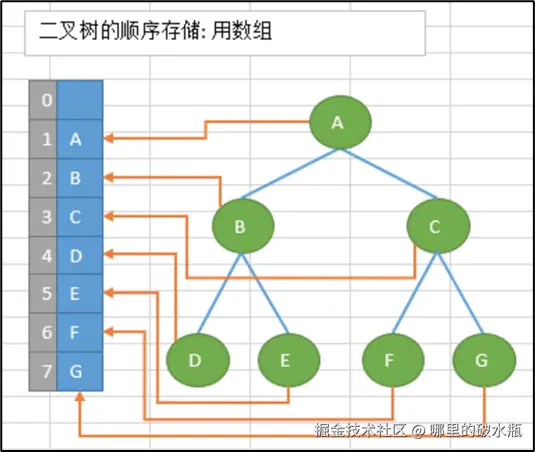
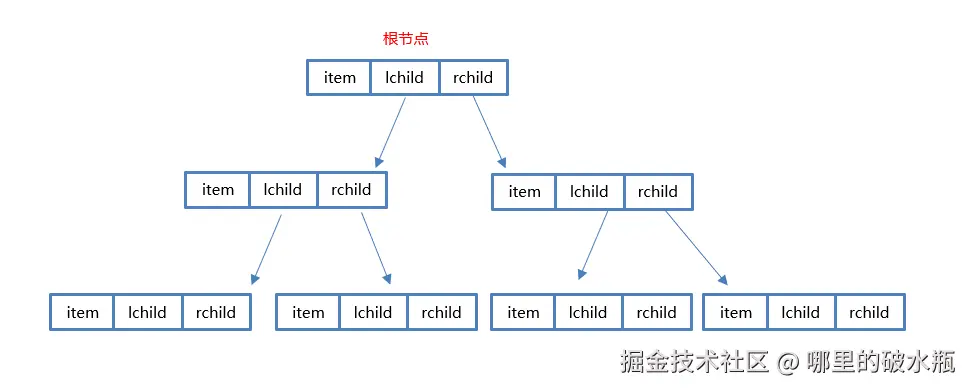
顺序存储:将二叉树存储在固定的数组中,虽然在遍历速度上有一定的优势,但因所占空间比较大,是非主流二叉树 存储方式.二叉树通常以链式存储
思考: 存储树,要存储树的哪些信息?
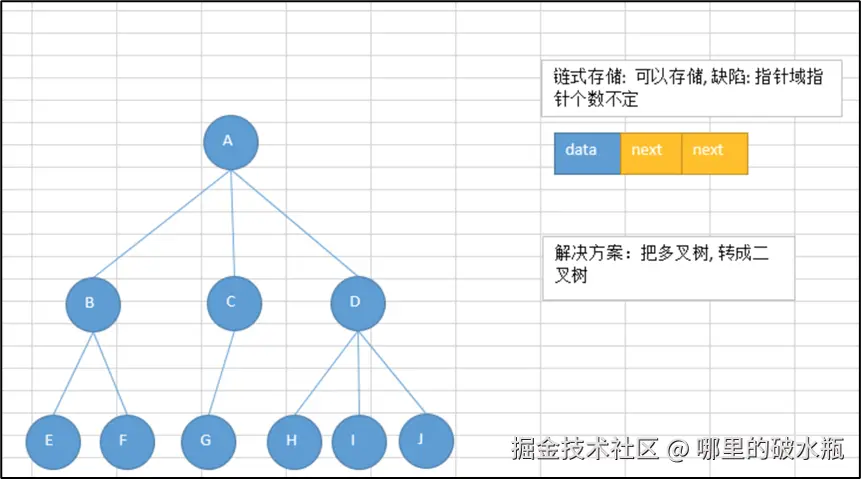
链式存储:由于对节点的个数无法掌握,常见树的存储表示都转换成二叉树进行处理,子节点个数最多为2
二叉树: 每个节点最多含有两个子树的树称为二叉树
完全二叉树:对于一颗二叉树,假设其深度为d(d>1)。除了第d层外 其它各层的节点数目均已达最大值,且第d层所有节点从左向右连续 地紧密排列,这样的二叉树被称为完全二叉树
二叉树的存储方式: 链式存储(每个结点有两个指针域)
顺序表:
链式存储:
二叉树是每个节点最多有两个子树的树结构 通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)
深度:一路往下走到最深,再回头换一条路继续走。
优点:
广度:按层一层一层访问,从上到下,从左到右。
优点:

# 1. 定义节点类 Node
class Node:
def __init__(self, item):
self.item = item
self.lchild = None
self.rchild = None
# 2. 定义二叉树类 BinaryTree
class BinaryTree:
def __init__(self, root=None):
self.root = root
# 定义函数,往二叉树中添加元素
def add(self, item):
if self.root is None:
self.root = Node(item)
return
# 创建一个队列
queue = [self.root]
while queue:
# 弹出队列的第一个元素
cur = queue.pop(0)
# 判断当前节点的左子树
if cur.lchild is None:
cur.lchild = Node(item)
return
queue.append(cur.lchild)
# 判断当前节点的右子树
if cur.rchild is None:
cur.rchild = Node(item)
return
queue.append(cur.rchild)
# 定义函数,实现广度逐层遍历
def breadth_travel(self):
if self.root is None:
return
queue = [self.root]
while queue:
cur = queue.pop(0)
print(cur.item)
if cur.lchild is not None:
queue.append(cur.lchild)
if cur.rchild is not None:
queue.append(cur.rchild)
if __name__ == '__main__':
bt = BinaryTree()
bt.add('a')
bt.add('b')
bt.add('c')
bt.add('d')
bt.add('e')
bt.add('f')
bt.add('g')
bt.add('h')
bt.add('i')
bt.breadth_travel()
# 1. 定义节点类 Node
class Node:
def __init__(self, item):
self.item = item
self.lchild = None
self.rchild = None
# 2. 定义二叉树类 BinaryTree
class BinaryTree:
def __init__(self, root=None):
self.root = root
# 定义函数,往二叉树中添加元素
def add(self, item):
if self.root is None:
self.root = Node(item)
return
# 创建一个队列
queue = [self.root]
while queue:
# 弹出队列的第一个元素
cur = queue.pop(0)
# 判断当前节点的左子树
if cur.lchild is None:
cur.lchild = Node(item)
return
queue.append(cur.lchild)
# 判断当前节点的右子树
if cur.rchild is None:
cur.rchild = Node(item)
return
queue.append(cur.rchild)
# 定义函数,实现广度逐层遍历
def breadth_travel(self):
if self.root is None:
return
queue = [self.root]
while queue:
cur = queue.pop(0)
print(cur.item)
if cur.lchild is not None:
queue.append(cur.lchild)
if cur.rchild is not None:
queue.append(cur.rchild)
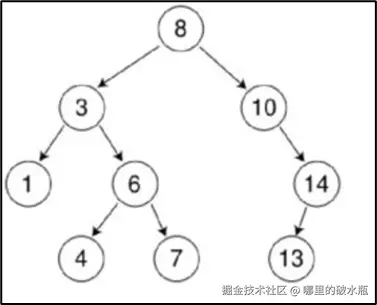
# 先序遍历
def preorder(self, node):
if node is not None:
# 访问根节点
print(node.item, end=' ')
# 访问左子树
self.preorder(node.lchild)
# 访问右子树
self.preorder(node.rchild)
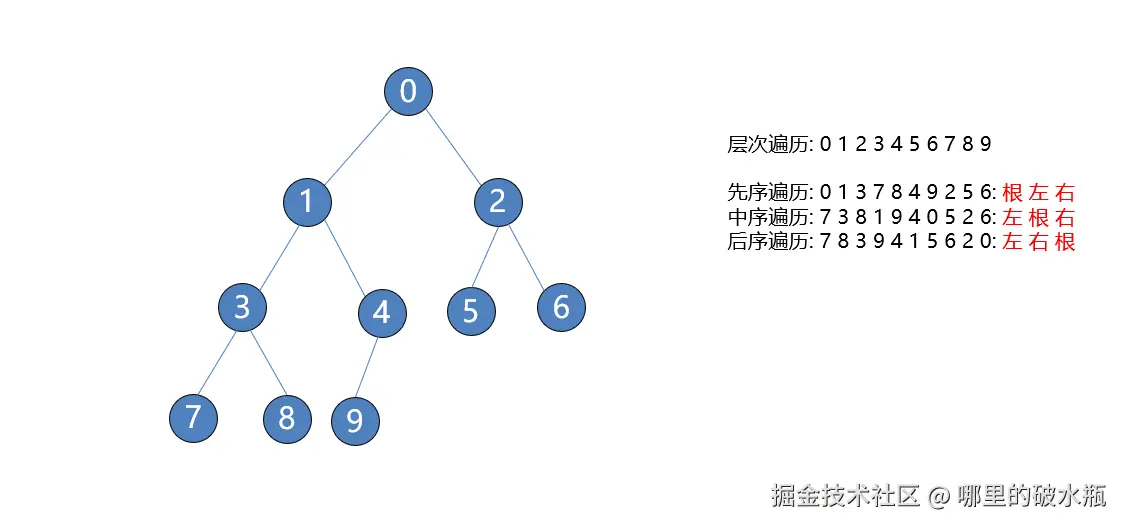
# 结果 0137849256
# 中序遍历
def inorder(self, node):
if node is not None:
# 访问左子树
self.inorder(node.lchild)
# 访问根节点
print(node.item, end=' ')
# 访问右子树
self.inorder(node.rchild)
# 7 3 8 1 9 4 0 5 2 6
# 后序遍历
def postorder(self, node):
if node is not None:
# 访问左子树
self.postorder(node.lchild)
# 访问右子树
self.postorder(node.rchild)
# 访问根节点
print(node.item, end=' ')
# 7 8 3 9 4 1 5 6 2 0
if __name__ == '__main__':
bt = BinaryTree()
bt.add(0)
bt.add(1)
bt.add(2)
bt.add(3)
bt.add(4)
bt.add(5)
bt.add(6)
bt.add(7)
bt.add(8)
bt.add(9)
bt.preorder(bt.root)
print()
bt.inorder(bt.root)
print()
bt.postorder(bt.root)
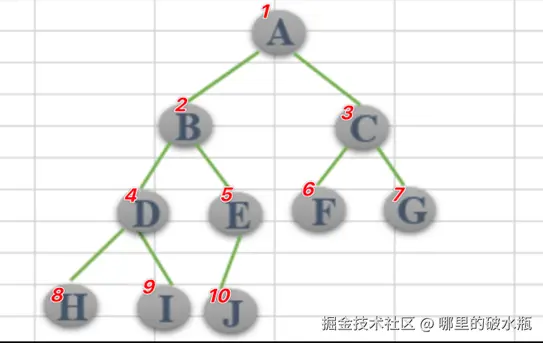
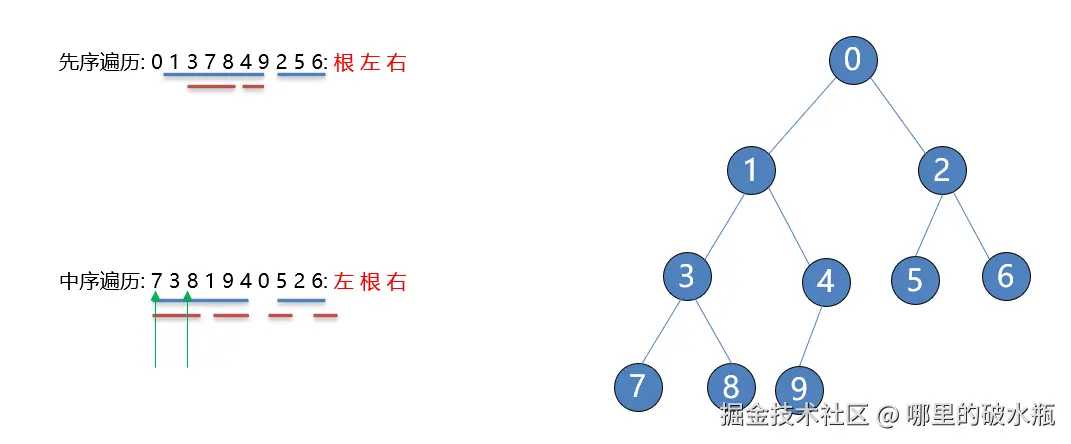
知道中序遍历 和 先序遍历 或者 后序遍历 就可以推出二叉树的结构
思路:
通过先序遍历可以确定哪个元素是根节点,通过中序遍历可以知道左子树都有那些结点、右子树都有那些结点。

