巫魔人中文正式版
477M · 2025-10-14

alixixi 10 月 14 日消息,科技媒体 9to5Mac 今天(10 月 14 日)发布博文,报道称苹果提出 FS-DFM 扩散模型,仅需 8 轮快速迭代,即可生成与传统模型上千轮迭代质量相媲美的文本,且写入速度比同类模型最多可提高 128 倍。
苹果公司与俄亥俄州立大学的研究团队近期联合发表论文,提出一种名为“少步离散流匹配”(Few-Step Discrete Flow-Matching,简称 FS-DFM)的新型语言模型。
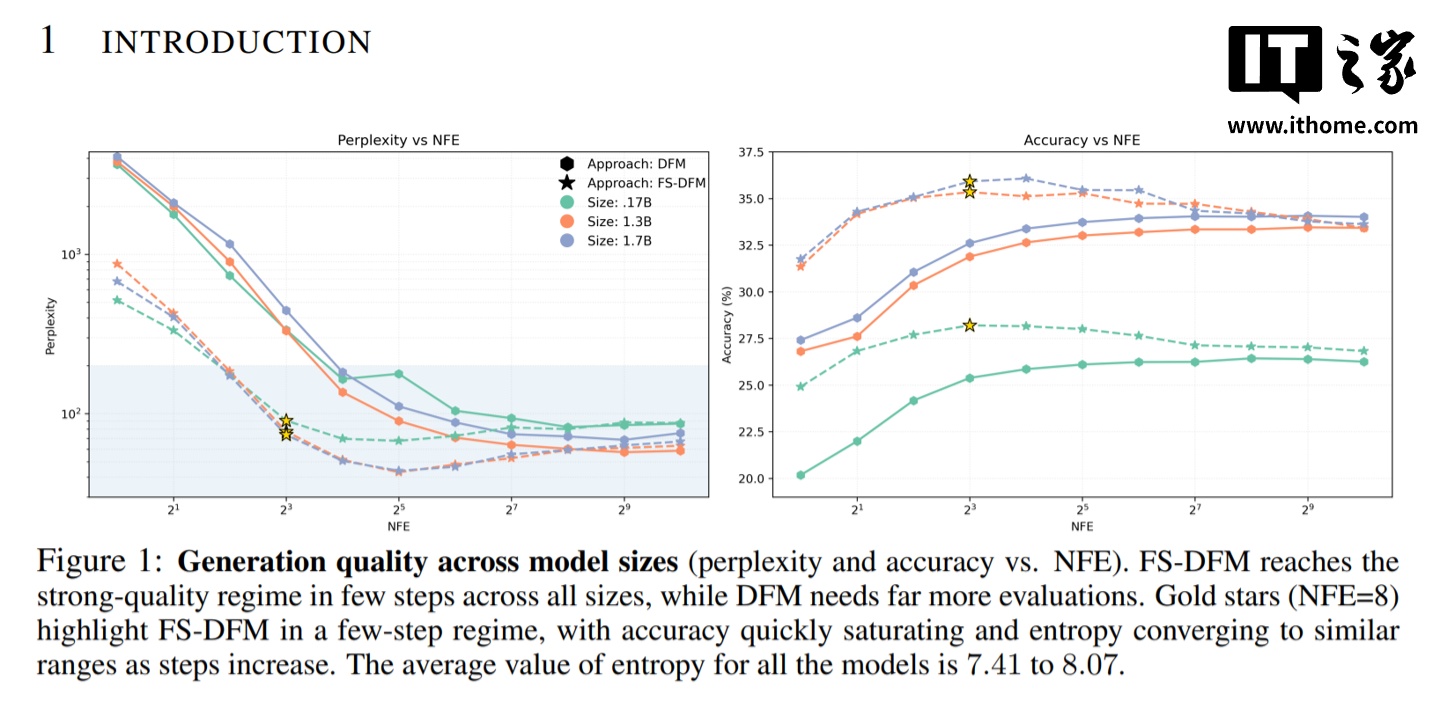
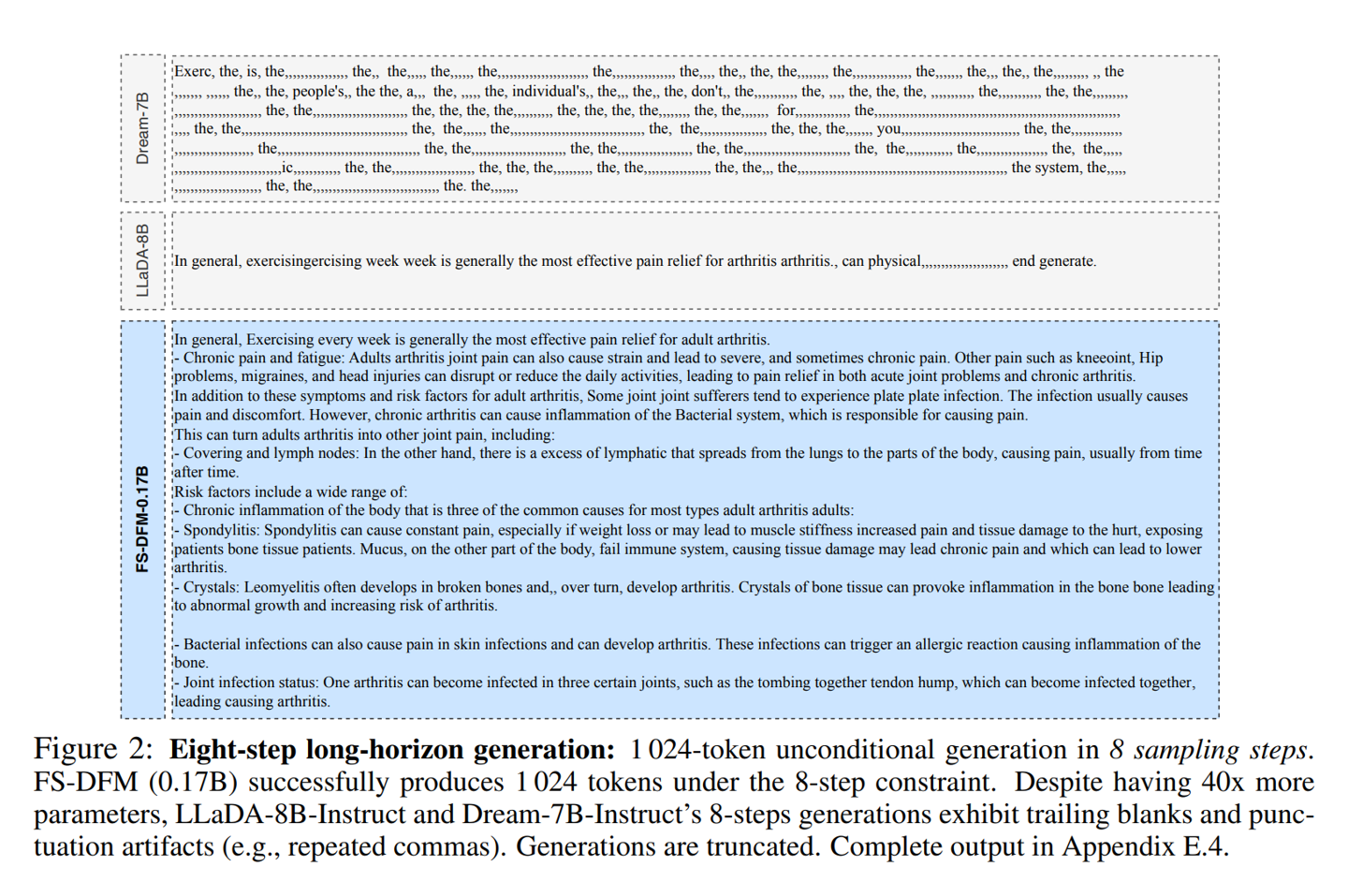
该模型专注于解决长文本生成领域的效率瓶颈,仅需 8 轮快速精练,就能生成高质量的长篇文本,其效果足以媲美传统扩散模型执行上千步迭代所实现的效果。

在深入了解 FS-DFM 之前,需要区分两种主流的语言模型范式:
以 ChatGPT 为代表的自回归模型,其工作方式是逐字(Token)串行生成文本,后一个字的生成依赖于前面所有内容。
而扩散模型则采用并行策略,一次性生成多个字,再通过多轮迭代逐步优化,直至形成完整的回应。
FS-DFM 作为扩散模型的一个变体,进一步简化了迭代过程,旨在用最少的步骤直接生成最终结果。alixixi援引博文介绍,苹果研究人员为实现这一突破,设计了一套精妙的三步法:
首先,模型经过专门训练,能够灵活适应不同的精炼迭代次数。
其次,团队引入一个“教师”模型进行引导,确保模型在每轮迭代中都能进行大幅且精准的更新,同时避免出现“矫枉过正”的问题。
最后,他们还优化了迭代机制本身,让模型能以更少、更稳健的步骤生成最终文本。
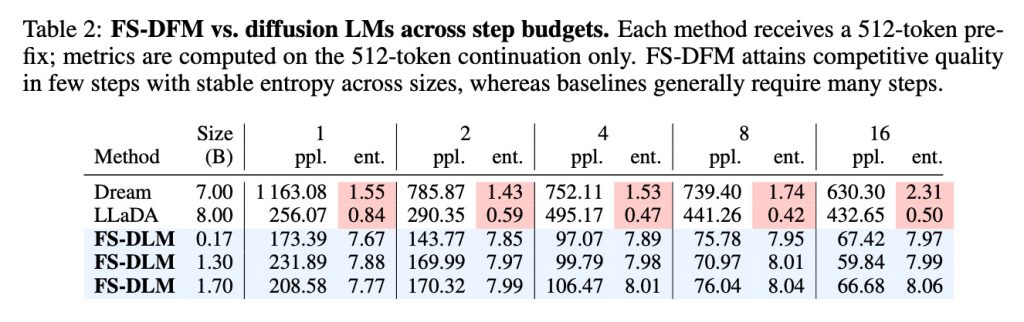
在性能评估中,FS-DFM 还支持对比了拥有 70 亿参数的 Dream 模型和 80 亿参数的 LLaDA 模型。测试结果显示,即使是参数量仅为 1.7 亿至 17 亿的 FS-DFM 变体,在困惑度(衡量文本准确与流畅性的指标,越低越好)和熵(衡量模型选词置信度的指标。熵太低,生成的文本可能单调重复;熵太高,则可能胡言乱语)两项关键数据上,都表现出更低的困惑度和更稳定的熵。