

后宫大酒店0.8汉化安卓版
15.23MB · 2025-12-25

首先声明一下,hive是什么:
hive 不是数据库,hive 只是一个数据仓库工具,可以用来查询、转化和加载数据,是可以调用 mapreduce 任务、用类 mysql 语法查询HDFS数据的一个工具。 再来说 mapreduce 是什么,mapreduce 是分而治之的一种编程模型,适用于大规模数据集的并行计算,当处理一个查询任务时,先调用 map 任务并行处理,最后用 reduce 任务归约结果。
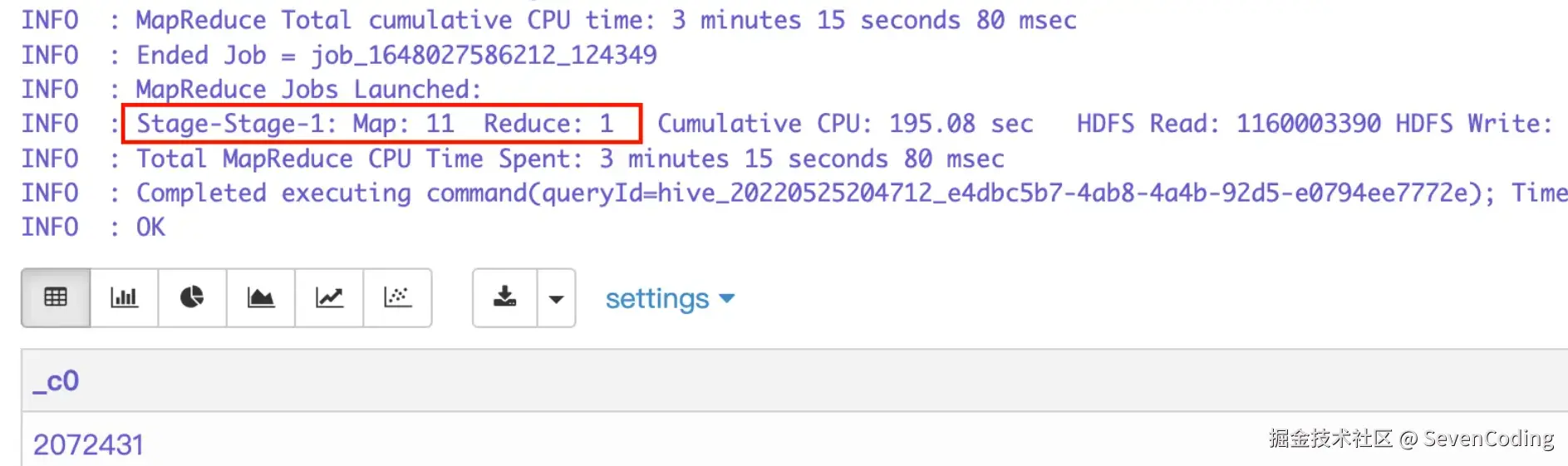
那么对于一张200w+的表,我们来看一下group by 和 distinct 的执行过程:
set mapreduce.map.java.opts="-Dfile.encoding=UTF-8"; set mapreduce.reduce.java.opts="-Dfile.encoding=UTF-8";
select province,city from seven_dataset_67 group by province,city
set mapreduce.map.java.opts="-Dfile.encoding=UTF-8"; set mapreduce.reduce.java.opts="-Dfile.encoding=UTF-8";
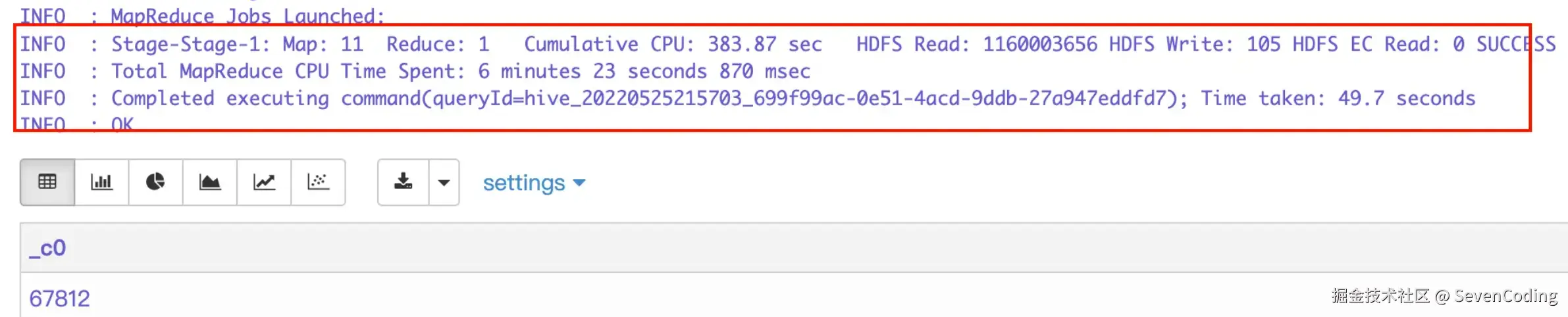
select distinct province,city from seven_dataset_67
这里可能就要问了,不是通常说 group by 的效率高于distinct吗?为什么distinct 和 group by 都调用了 18 个 reduce 任务,distinct 的时间还花费的少一些,其实在数据量不大的情况下,distinct 和 group by的差别不是很大。但是对于count(distinct *) 来说会发生数据倾斜,因为 hive 默认在处理COUNT这种“全聚合(full aggregates)”计算时,它会忽略用户指定的Reduce Task数,而强制使用 1,会发生数据倾斜。
select count(0) from seven_dataset_67
但是仍然要看数据量的大小,在数据量小的情况下去重计数,虽然count(distinct *) 会发生数据倾斜,但是只有执行一次 mapreduce任务,而 select count(0) from(select field from table group by field) 这种要执行两遍 mapreduce 任务,总的时间花费可能不比前者少,如下例子:
select count(0) from (select sales_order_no from seven_dataset_67 group by sales_order_no) a
*但是针对上亿的数据量,数据倾斜就会浪费很多时间,甚至由于机器资源紧张导致运行失败,这种情况就建议使用group by了,不仅可以分组,还能配合聚合函数一起使用*
基础定位差异
GROUP BY:是分组聚合操作,可以配合聚合函数使用,天然具备去重功能
DISTINCT:是纯粹去重操作,语法更简洁但功能单一
性能对比关键发现
| 场景 | GROUP BY优势 | DISTINCT优势 |
|---|---|---|
| 大数据量复杂分析 | 多Reducer并行处理,避免单点压力 | - |
| 简单去重小数据集 | - | 执行计划更简洁,减少中间步骤 |
| 多字段去重 | 支持多字段灵活组合 | 语法更直观 |
| 数据倾斜场景 | 可通过hive.groupby.skewindata优化 | 强制单Reducer处理,风险高 |
执行原理差异
DISTINCT:Map阶段输出全字段作为Key,强制单Reducer去重| 场景特征 | 推荐方案 | 原因说明 |
|---|---|---|
| 简单去重+小数据量 | DISTINCT | 语法简洁,执行计划简单 |
| 需要聚合计算 | GROUP BY | 唯一支持聚合操作的语法 |
| 大数据量+潜在倾斜 | GROUP BY + 倾斜优化参数 | 可避免单Reducer瓶颈 |
| 多维度组合分析 | GROUP BY | 支持多字段灵活组合 |
| 结果二次筛选 | GROUP BY + HAVING | DISTINCT无法实现 |
在 Mysql8.0 之前 group by 会进行隐式排序,导致触发 filesort,sql 执行效率低下, distinct 效率高于 group by。但从 Mysql8.0 开始,Mysql 就删除了隐式排序,所以在语义相同,无索引的情况下,group by 和 distinct 的执行效率也是近乎等价的。
数据倾斜:即数据分布不均匀导致某些reduce处理数据量过大
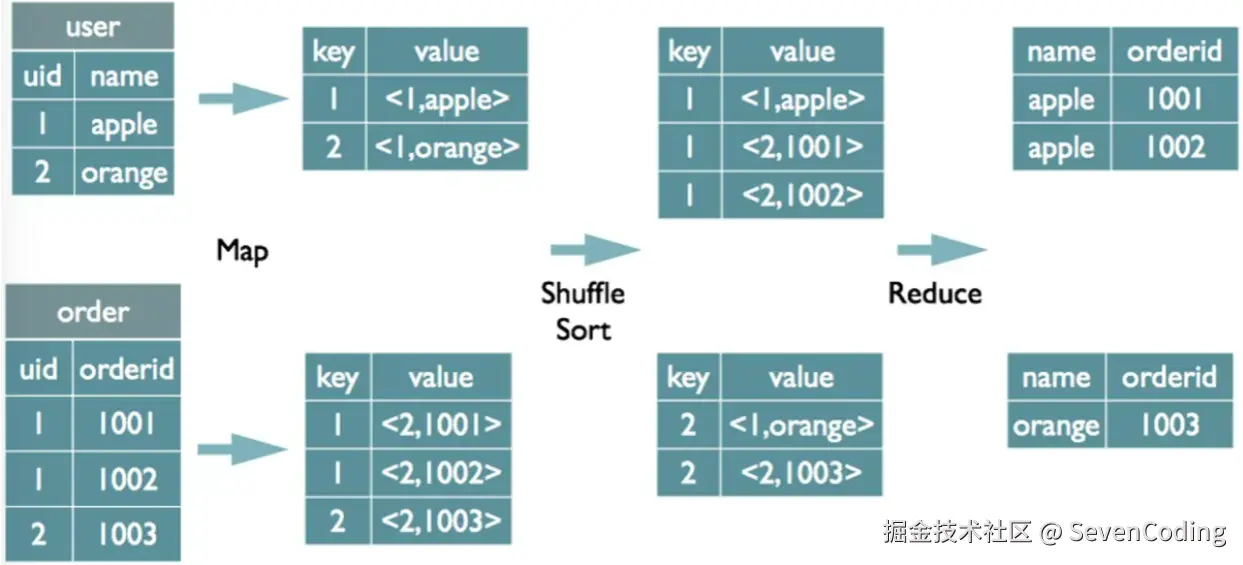
select name, orderid
from user t1
join order t2
on t1.uid=t2.uid
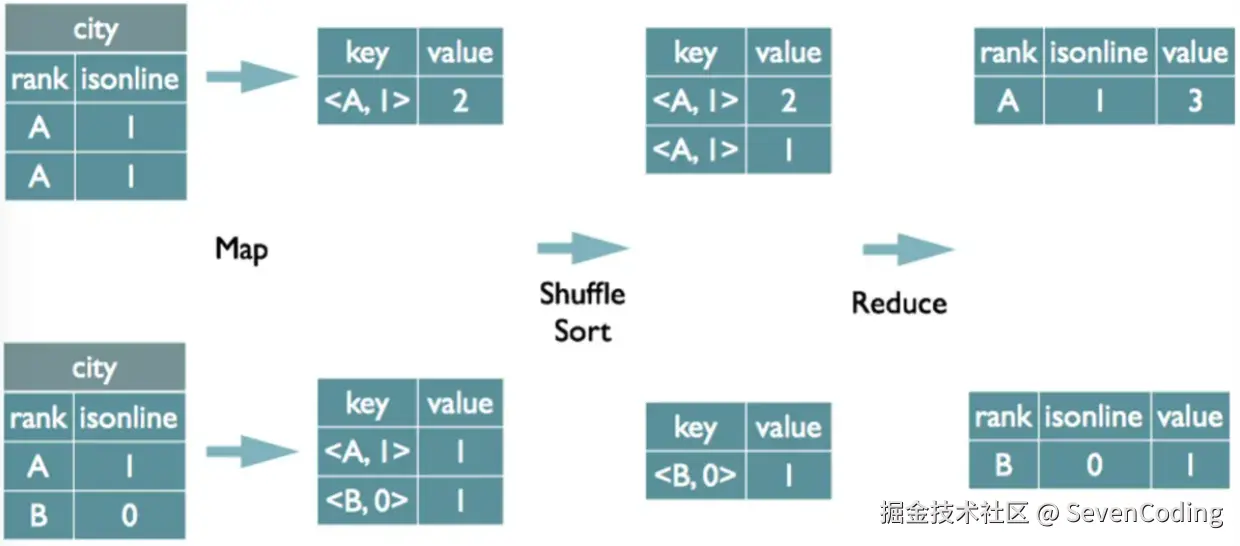
select rank, isonline, count(1)
from city
group by 1, 2
| 关键词 | 情形 | 会出现以下情况 |
|---|---|---|
| group by | group by 维度过小,某值的数量过多 | 处理某值的reduce非常耗时 |
| Count Distinct | 某特殊值过多 | 处理此特殊值的reduce耗时 |
| Join | 其中一个表较小,但是key集中,key值分布不均匀 | 分发到某一个或几个Reduce上的数据远高于平均值 |
| 大表与大表,但是分桶的判断字段0值或空值过多 | 这些空值都由一个reduce处理,非常慢 |
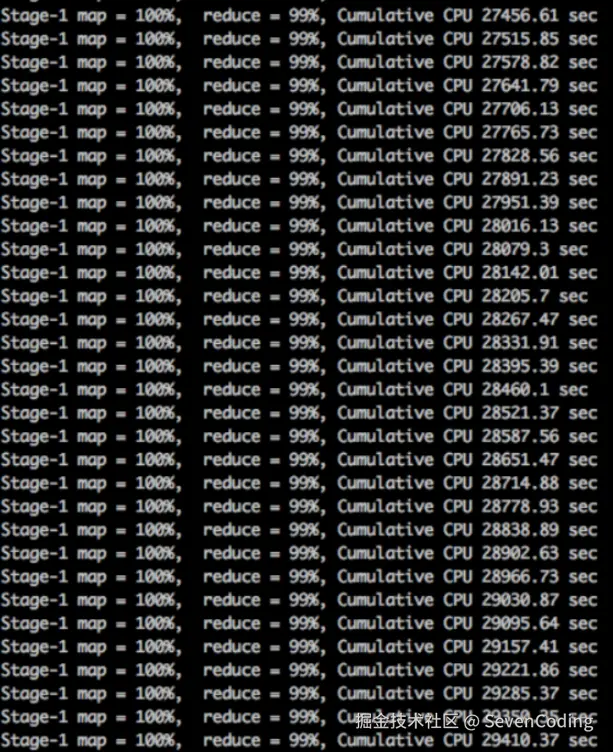
任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。
单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多。 最长时长远大于平均时长。
例如:看到下面这种情况,这肯定是数据倾斜了。map早就完工了,reduce阶段一直卡在99%,而且cumulative cpu的时间还一直在增长,说明整个job还在后台跑着。这种情况下,99%的可能性就是数据发生了倾斜,整个查询任务都在等某个节点完成。
Hive的执行是分阶段的,map处理数据量的差异取决于上一个stage的reduce输出,所以如何将数据均匀的分配到各个reduce中,就是解决数据倾斜的根本所在。
如果是由于key值为空或为异常记录,且这些记录不能被过滤掉的情况下:可以考虑给key赋一个随机值,将这些值分散到不同的reduce进行处理。由于null值关联不上,处理后并不影响最终结果。
关联字段中key都为有效值,某些key量大,造成reduce计算量大
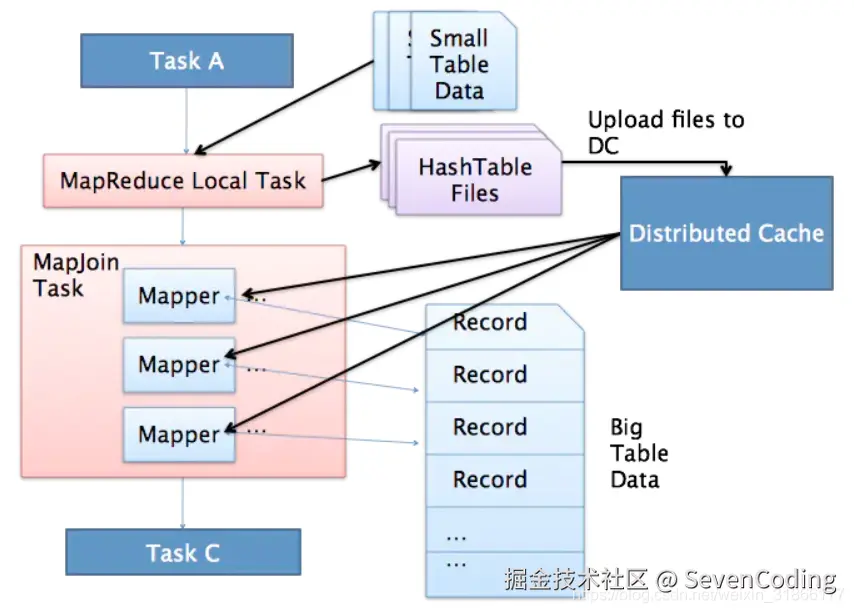
通过mapreduce local task, 扫描小表,生成为一个hashtable文件, 并上传到distributed cache
在map阶段,每个mapper, 从distributed cache中读取hashtable文件,扫描大表,并直接在map端join
set hive.exec.reducers.bytes.per.reducer = 1000000000或
set mapred.reduce.tasks=800 这两个一般不同时使用,
set hive.optimize.skewjoin = true;
set hive.skewjoin.key = skew_key_threshold (default = 100000)
set hive.skewjoin.key = 250000000
可以就按官方默认的1个reduce 只处理1G 的算法,那么skew_key_threshold= 1G/平均行长;或者默认直接设成250000000 (差不多算平均行长4个字节)
Hive的MapJoin理解:join的操作是在map阶段完成后,如果需要的数据在map的过程中可以访问到则就不再需要reduce了。
例如:小表关联一个超大表时,容易发生数据倾斜,可以使用Mapjoin把小表全部加载到内存,广播的方式分发到不同的map中,在map端进行join,避免reduce处理
select c.channel_name,count(t.requesturl) PV
from ods.cms_channel c
join
(select host,requesturl from dms.tracklog_5min where day='20241111' ) t
on c.channel_name=t.host
group by c.channel_name
order by c.channel_name;
上面的是一个小表join一个大表的时候,可以使用mapjoin把小表放到内存中处理,语法只需要增加 /*+MAPJOIN(表的名字)*/
select /*+ MAPJOIN(c) */
c.channel_name,count(t.requesturl) PV
from ods.cms_channel c
join
(select host,requesturl from dms.tracklog_5min where day='20241111' ) t
on c.channel_name=t.host
group by c.channel_name
order by c.channel_name;
数据倾斜的时候,常常如上面这么使用
一般认为在25M以内的数据都是小表:hive.mapjoin.smalltable.filesize=25000000
group by 引起数据倾斜的原因是 group by 维度过小,某值的数量过多
set hive.map.aggr=true
开启map之后使用combiner,但是这个通常对数据比较同质的有用,相反,则没有什么意义。
set hive.groupby.mapaggr.checkinterval = 100000 (默认)执行聚合的条数
set hive.map.aggr.hash.min.reduction=0.5(默认)如果hash表的容量与输入行数之比超过这个数,那么map端的hash聚合将被关闭,默认是0.5,设置为1可以保证hash聚合永不被关闭;
还有一个是set hive.groupby.skewindata=true, 这个只针对单列有效。
如果数据量非常大,执行如 select a,count(distinct b) from t group by a; 类型的SQL时,会出现数据倾斜的问题。
解决方法:采用sum() group by的方式来替换count(distinct)完成计算。
select a,sum(1) from (select a, b from t group by a,b) group by a;
15.23MB · 2025-12-25
248.99MB · 2025-12-25
1.25 GB · 2025-12-25

