Rapid PHP(PHP编辑器) v18.3
119.24M · 2025-09-11

添加图片注释,不超过 140 字(可选)
语音作为人类交流和人机交互的核心媒介,其自然度、表现力和韵律感直接决定了交互体验的质量。在播客、访谈、直播等场景中,对话语音是信息传递的主要形式。然而,传统文本到语音(TTS)模型在单句生成上虽有突破,但在复杂对话场景中,缺乏对整体语境的建模能力,导致生成的语音韵律单一,缺乏真实感。针对这一挑战,MOSS-TTSD(Text to Spoken Dialogue)推出了,一个专为对话场景设计的语音生成模型,带来中英双语、自然流畅、支持多说话人音色克隆的对话语音生成体验。
MOSS-TTSD 是一个基于 Qwen3-1.7B-base 模型深度优化的对话语音生成系统,结合了先进的离散化语音序列建模技术和海量数据训练,实现了以下关键特性:
添加图片注释,不超过 140 字(可选)
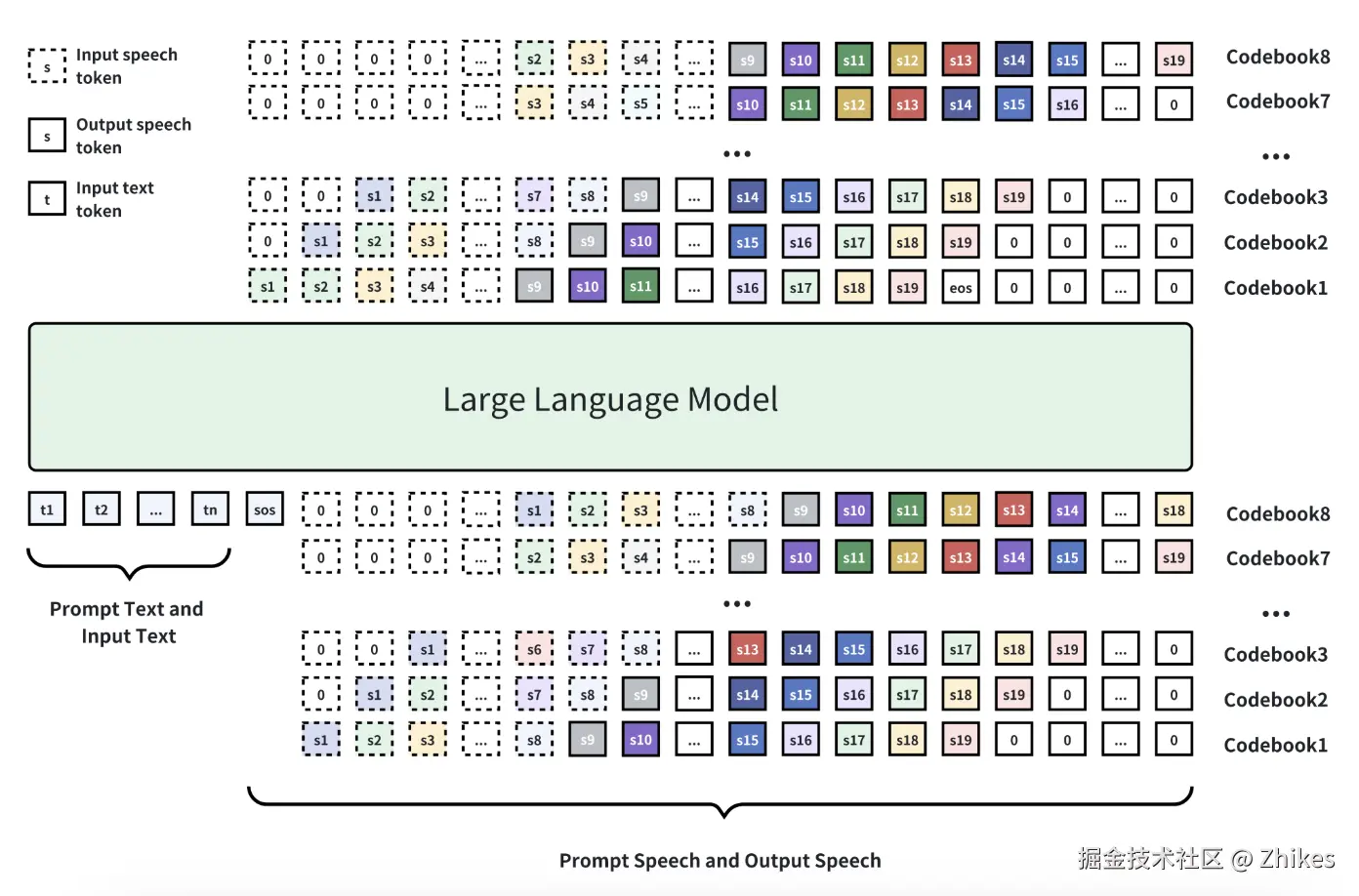
MOSS-TTSD 的核心技术之一是 XY-Tokenizer,一个专为语音离散化设计的 8 层残差矢量量化(RVQ)音频 Codec。它通过以下方式实现高效编码:
下表展示了 XY-Tokenizer 在 LibriSpeech 测试集上的表现,与其他低比特率 Codec 相比,MOSS-TTSD 的语义信息(以词错误率 WER 衡量)与声学性能均达到领先水平:
| Codec | WER ↓ | 声学性能 |
|---|---|---|
| Codec A | 3.5 | 中等 |
| Codec B | 3.2 | 中等 |
| XY-Tokenizer (Ours) | 2.8 | 优异 |
受 MusicGen 和 VOICECRAFT 的启发,MOSS-TTSD 采用 自回归建模 结合 多头 Delay 的方式生成语音 token。这种方法能够有效捕捉对话中的长期依赖关系,确保语音在韵律、语调和风格上的连贯性。
MOSS-TTSD 的出色性能离不开高效的数据处理流水线。从 海量原始音频 中筛选出单人语音和多人对话语音,并通过以下步骤优化数据质量:
| Model | AISHELL-4 | AliMeeting | AMI (IHM) | AMI (SDM) |
|---|---|---|---|---|
| pyannote-speaker-diarization-3.1 | 11.7 | 24.7 | 20.5 | 24.3 |
| pyannoteAI | 11.1 | 18.3 | 17.5 | 20.0 |
| Ours Diarization Model | 9.7 | 14.1 | 14.5 | 17.2 |
最终,构建了 110万小时 的中英文 TTS 训练数据和 37万小时 的对话数据(包括 10万小时 中文和 27万小时 英文对话),并通过 Gemini 修正部分转录文本,提升标点符号的感知能力。
MOSS-TTSD 在 Seed-tts-eval 测试集上的表现与闭源顶尖模型 Seed-TTS 相当,词错误率(WER)和字符错误率(CER)均达到业界领先水平:
| Model | WER ↓ | CER ↓ | WER (Norm) ↓ | CER (Norm) ↓ |
|---|---|---|---|---|
| Seed-TTS | 2.25 | 1.12 | N/A | N/A |
| Cosyvoice2 | 2.80 | 1.59 | 2.52 | 0.80 |
| SparkTTS | 1.99 | 2.12 | 1.69 | 1.44 |
| MOSS TTS-base | 1.90 | 1.56 | 1.54 | 0.82 |
通过 WSD Scheduler 进行后训练,MOSS-TTSD 在 37万小时 真实对话数据和 8万小时 合成对话数据的支持下,进一步提升了说话人切换的准确性和对话语音的自然度。最终模型通过人工评估挑选,确保主观表现达到最佳。
MOSS-TTSD 的强大功能使其适用于多种对话场景,包括但不限于:
本地部署:
克隆仓库
git clone https://github.com/OpenMOSS/MOSS-TTSD.git
使用 conda
conda create -n moss_ttsd python=3.10 -y
conda activate moss_ttsd
pip install -r requirements.txt
pip install flash-attn
下载模型
mkdir -p XY_Tokenizer/weights
huggingface-cli download fnlp/XY_Tokenizer_TTSD_V0_32k xy_tokenizer.ckpt --local-dir ./XY_Tokenizer/weights/
或者在huggingface.co/fnlp/XY_Tok…网站中找到Files and versions下载xy_tokenizer.ckpt文件放到XY_Tokenizer/weights目录下
一键整合包:
卫星公众号:InnoTechX 发送关键字: moss
使用方式
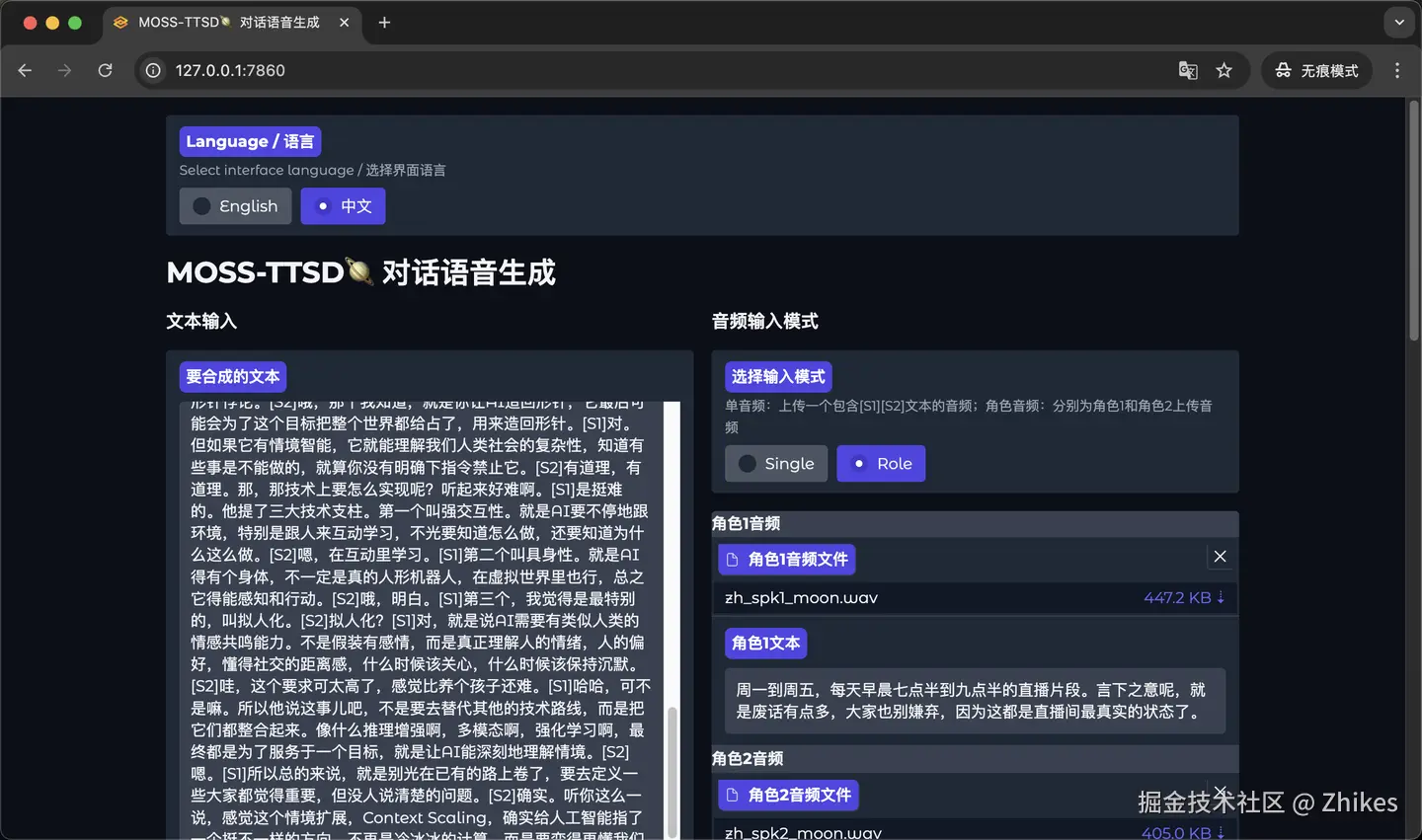
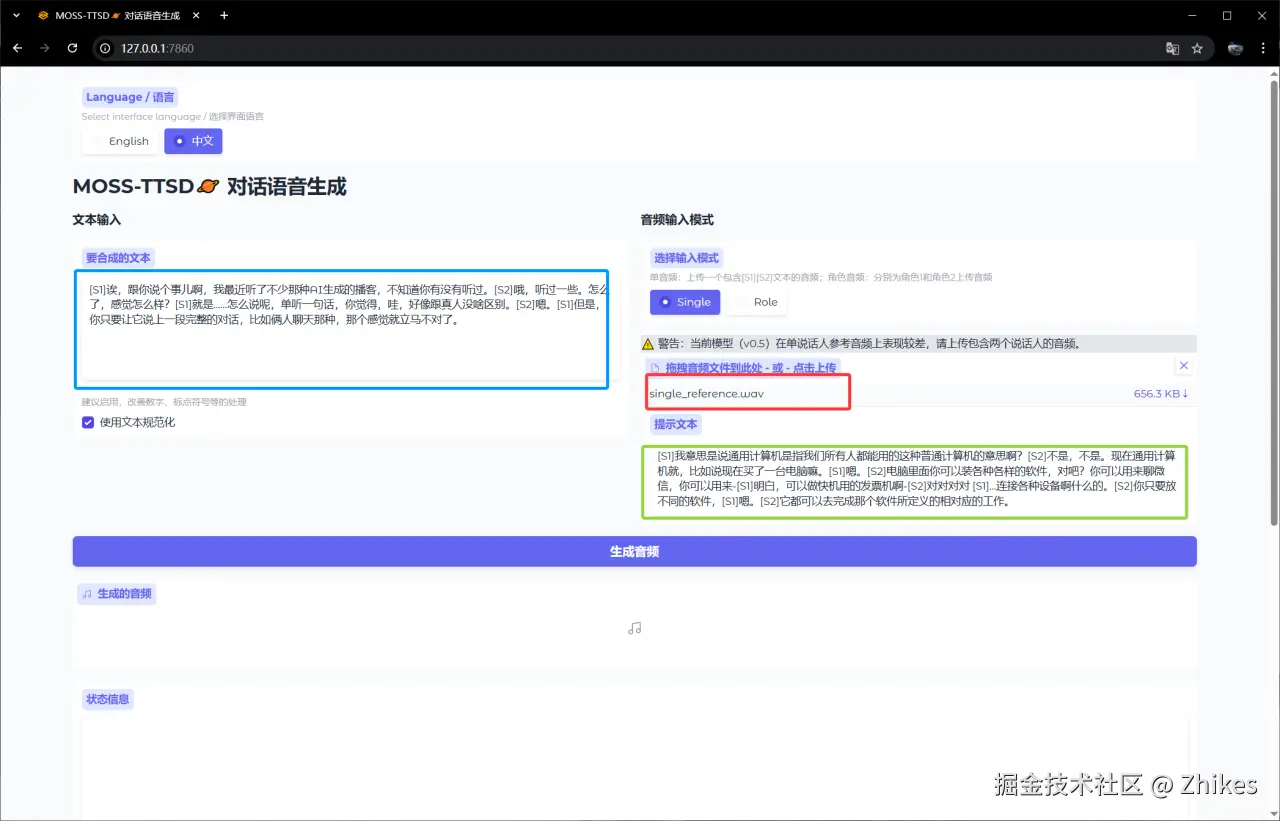
第一种是单音频方式,音频中包含两个说话人的音频,用[S1] [S2] 分别代表两个人的说话内容,填写到提示文本中。然后在要合成的文本中,也是使用这种方式,来进行文本To音频克隆的转换。
添加图片注释,不超过 140 字(可选)
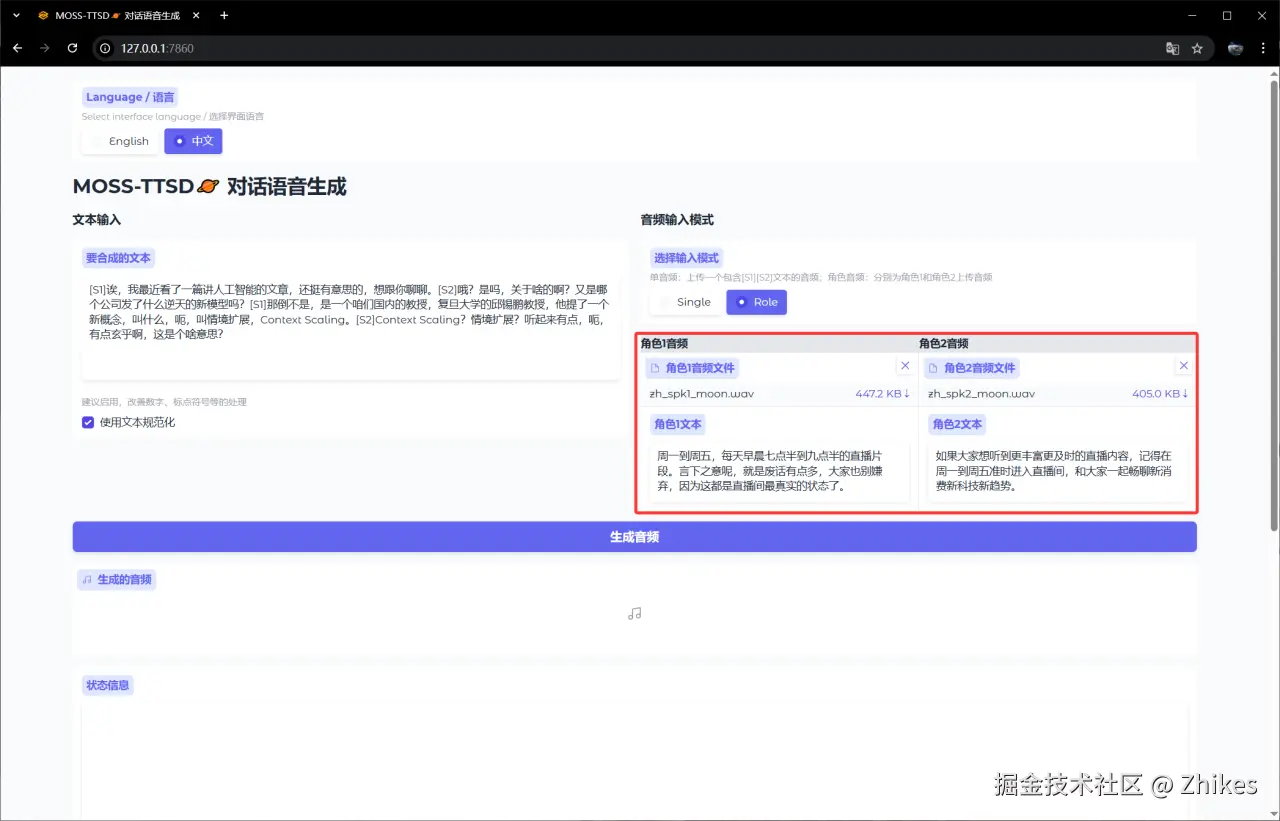
第二种则是,分别上传不同角色的音频,分别输入不同角色的说话内容,在合成的文本中,实现的对话式的合成文本内容即可,也是用[S1] [S2] 分别代表两个人的说话内容
添加图片注释,不超过 140 字(可选)
现在只支持两个人之间的对话克隆,多人的对话克隆,作者还在研究中。。。
119.24M · 2025-09-11
72.39MB · 2025-09-11
3.32MB · 2025-09-11
杭州萧山推出线下消费补贴:18-40 岁青年购 3C 数码产品最高可补 1000 元
努比亚张雷:手机市场从不是“非此即彼”的零和博弈,行业活力正来自这种差异化

