




畅读书城1000000阅币版
14.32M · 2025-09-12

DSPy 是斯坦福大学开发的LLM编程框架,在GitHub上已获得27.5k+ stars,
代表着声明式AI应用开发的新范式。其核心理念是通过编写组合式Python代码,而不过度依赖Prompt工程。
项目地址:
github.com/stanfordnlp…
假如让你构建一个AI应用,任务是对用户评论进行情感分析。使用提示词Prompt的方式下,你会怎么做?
prompt = "请分析以下文本的情感,返回0-10的分数,数字越大表示越积极:{text}"
response = llm.generate(prompt.format(text="我很开心!"))
但这种方式存在什么问题?当提示内容复杂的时候,每次调整都需要重写Prompt。当面对不同任务时,都要重新设计Prompt。当模型更换时,可能还需要重新调试Prompt。
那同样的任务,通过Dspy是怎么解决的?Dspy的核心是:通过在客户端声明数据格式,将LLM调用看作是API调用。
这里的关键是声明式,首先要理解传统的API的调用方式,通常由服务端预先定义好接口格式,然后客户端必须按照服务端的规范发送请求,数据格式是"服务端主导"的,服务端说什么格式,客户端就必须用什么格式。举个例子,服务端按下面定义,那么客户端传参数时,必须传city、date。:
response = requests.post('/api/weather', {
'city': '北京',
'date': '2025-08-23' # 必须按服务端要求
})
temp = response['temperature'] # 服务端决定返回什么字段
而Dspy是客户端(代码)定义输入输出格式,服务端LLM去自适应,是声明式的开发方式。
# DSPy:LLM适应你定义的格式
class WeatherQuery(dspy.Signature):
city = dspy.InputField() # 输入city
temperature = dspy.OutputField() # 输出温度
这样做的好处是,不必要跟随着LLM的响应结果走了。传统API固定了响应格式,当LLM输出格式不稳定时,还需要兼容修改解析代码,影响解析结果。
这里用情感分析的例子来贯穿这四个核心模块。
Signature负责显式定义LLM交互的输入输出格式,使得模型响应无需手动解析字段,确保每次LLM调用都有明确的共识。根据应用复杂度的不同,DSPy提供了两种Signature定义方式:
当需要精确控制字段类型、描述和约束时,推荐使用类基签名。它通过继承 dspy.Signature 类实现,包含 五个核心组件 :
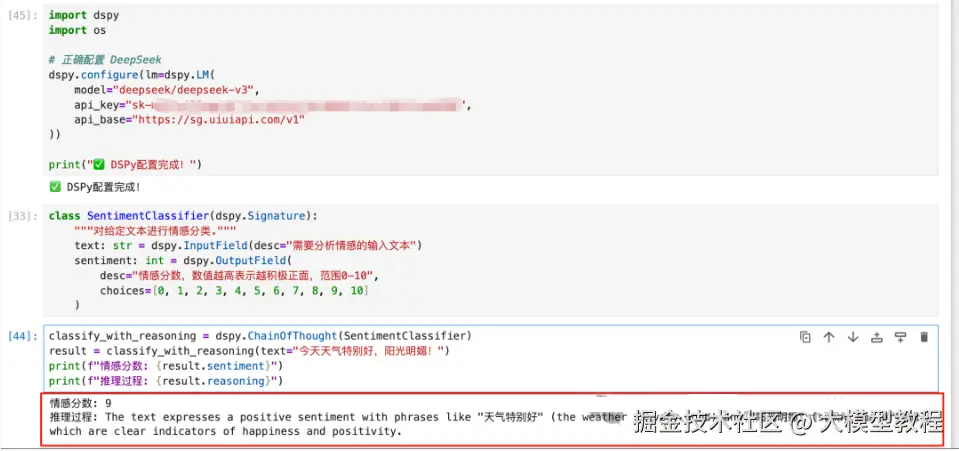
class SentimentClassifier(dspy.Signature):
"""对给定文本进行情感分类."""
text: str = dspy.InputField(desc="需要分析情感的输入文本")
sentiment: int = dspy.OutputField(
desc="情感分数,数值越高表示越积极正面,范围0-10",
choices=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
)
当需要快速实验和原型开发时,可直接使用字符串签名:
# 字符串基签名示例
classify = dspy.Predict("text -> sentiment: int")
Module负责封装与LLM交互的业务逻辑。当通过Signature定义好输入输出接口后,Module将这些接口组织成可执行的推理流程,把多个Signature组合成复杂推理链,再通过forward()方法管理复杂的业务逻辑执行。根据应用复杂度的不同,DSPy提供了两种Module使用方式:
当任务相对简单时,可以直接使用DSPy提供的内置模块:
# 使用内置模块的情感分析示例
classify = dspy.Predict(SentimentClassifier)
result = classify(text="我很开心!")
当需要构建复杂的多步骤推理流程时,需要继承 dspy.Module 并自定义逻辑:
# 自定义模块示例
class CelebrityGuess(dspy.Module):
def __init__(self):
self.question_generator = dspy.ChainOfThought(QuestionGenerator)
self.reflection = dspy.ChainOfThought(Reflection)
def forward(self, celebrity_name):
# 复杂的多轮对话逻辑
# ...
Adapter负责在Signature和LLM之间进行格式转换。当通过Signature定义好输入输出接口后,Adapter将这些接口转换成LLM能理解的prompt格式,并将LLM的文本响应解析为结构化数据,实现将语言模型当作"有明确定义输入输出的API"来使用的目标。根据转换复杂度的不同,DSPy提供了两种Adapter使用方式:
当使用DSPy的内置模块时,框架会自动选择合适的Adapter:
# 自动选择Adapter的情感分析示例
classify = dspy.Predict(SentimentClassifier)
result = classify(text="我很开心!")
# Adapter自动处理prompt构建和响应解析
print(result.sentiment) # 直接访问结构化结果
当需要特定的prompt格式或解析逻辑时,可以自定义Adapter:
# 配置自定义Adapter示例
dspy.settings.configure(
lm=dspy.LM("openai/gpt-4o-mini"),
adapter=CustomAdapter() # 使用自定义适配器
)
Adapter配置完成后,运行时实际的工作流程主要有三步(隐式实现):接受输入->构建prompt->解析响应。
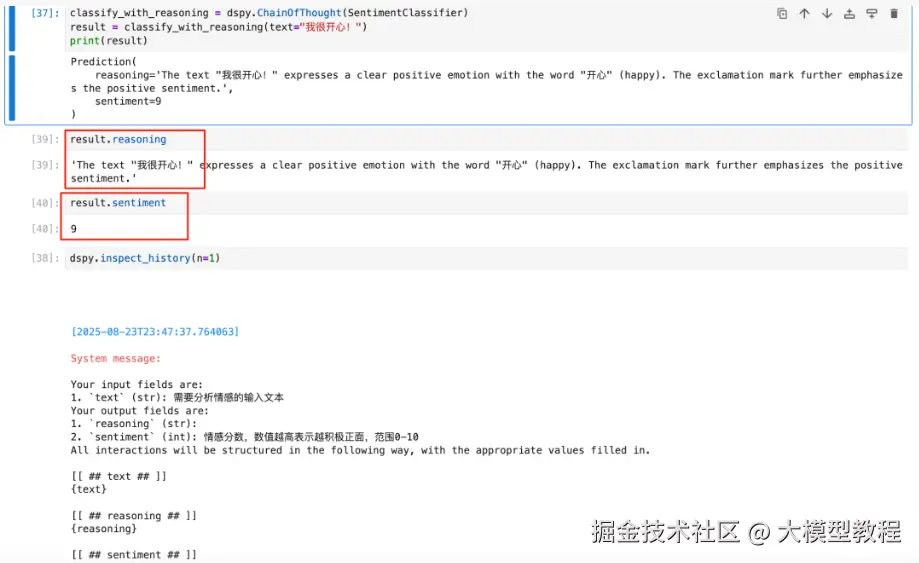
可以通过dspy.inspect_history()查看Adapter的完整工作过程:
# LLM的原始输出
"""
[[ ## reasoning ## ]]
The text "我很开心!" expresses a clear positive emotion with the word "开心" (happy). The exclamation mark further emphasizes the positive sentiment.
[[ ## sentiment ## ]]
9
"""
# Adapter解析后的结构化结果
result.reasoning = "'The text "我很开心!" expresses a clear positive emotion with the word "开心" (happy). The exclamation mark further emphasizes the positive sentiment.'"
result.sentiment = 9 # 自动转换为int类型
注意:使用dspy.ChainOfThought才会包含推理过程,直接使用dspy.Predict不会显示推理过程(也就是reasoning),而是直接输出结果。
Optimizer负责自动优化DSPy程序的性能,解决传统手工调试prompt的痛点。当构建好Module和Signature后,Optimizer通过智能搜索和评估,自动找到最优的prompt模板和few-shot示例组合,实现程序质量的显著提升。根据优化需求的不同,DSPy提供了两种Optimizer使用方式:
当需要快速获得优化效果时,可以使用DSPy提供的自动模式:
# 使用自动模式的优化示例
optimizer = dspy.MIPROv2(mode="auto") # 可选:light, medium, heavy
optimized_program = optimizer.compile(
student=program,
trainset=train_data,
valset=val_data,
metric=accuracy_metric
)
这里的program 就是你自己构建的 DSPy 模块实例 。可以是:dspy.Predict、dspy.ChainOfThought、 dspy.ReAct或者自定义模块。train_data是你用来优化的数据集,类似HotPotQA所使用的QA数据集。Optimizer会用这些数据来生成 few-shot 示例(通过 bootstrapping 过程),选择最佳的指令和示例组合。
# HotPotQA数据集示例
train_data = [
{
"question": "Which magazine was started first Arthur's Magazine or First for Women?",
"answer": "Arthur's Magazine"
},
# ... 更多训练样本
]
当需要精细控制优化过程时,可以自定义优化器配置:
# 自定义优化示例
defcustom_metric(example, prediction):
return example.answer == prediction.answer
# custom_metric: 使用什么评估指标
# max_bootstrapped_demos: 最多生成多少个bootstrap示例
# max_labeled_demos: 最多使用多少个标注示例
optimizer = dspy.BootstrapFewShot(
metric=custom_metric,
max_bootstrapped_demos=8,
max_labeled_demos=4
)
optimized_program = optimizer.compile(
student=program,
trainset=train_data
)
当调用ptimizer.compile() ,DSPy 实际会执行四步流程:
构建一个情感分析系统,要求:
结合前面提到的四个模块,可以很容易的实现:
构建一个"猜名人"游戏AI代理:
首先思考多轮对话的设计实现,既然是多轮对话,就要包含历史对话的内容信息。没有历史感知的方式,是每次都重新开始,例如:
# 每轮独立,历史容易丢失
for attempt in range(20):
question = generate_question() # 从零开始,无历史感知
answer = get_user_input()
使用dspy要传入完整的历史,每次的决策都是基于全局的上下文:
# 每轮都是基于完整历史的智能决策
for attempt in range(20):
question_result = self.question_generator(
past_questions="n".join(past_questions), # 传入完整历史
past_answers="n".join(past_answers) # 传入完整历史
)
# 新的交互立即成为下一轮的历史
past_questions.append(question_result.new_question)
past_answers.append(answer)
要想回答正确,需要从宽泛的问题逐步缩小范围到具体答案。通过reasoning和历史上下文,由AI自动来做分层推理。
设置guess_made,当AI认为有足够的信息可以推断时,guess_made=True时,AI认为信息足够,开始直接猜测。当guess_made=False时,AI生成宽泛的分类问题继续提问。
class QuestionGenerator(dspy.Signature):
"""Generate a yes/no question to narrow down the celebrity guess."""
past_questions: str = dspy.InputField(desc="previously asked questions")
past_answers: str = dspy.InputField(desc="corresponding yes/no answers")
new_question: str = dspy.OutputField(desc="new yes/no question to ask")
guess_made: bool = dspy.OutputField(desc="whether this is a direct guess")
定义子模块Signature:
控制流程模块:
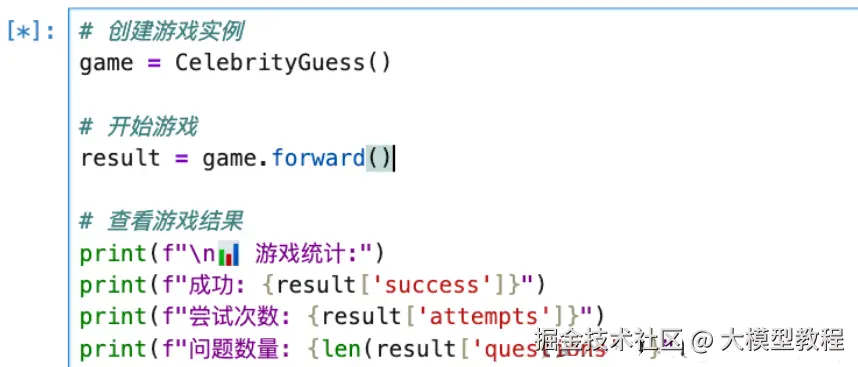
游戏演示:
运行结果:
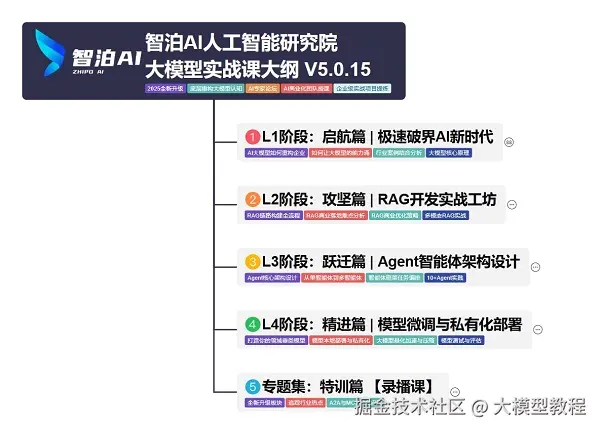
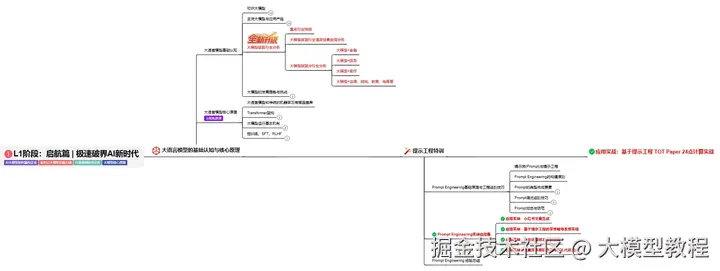
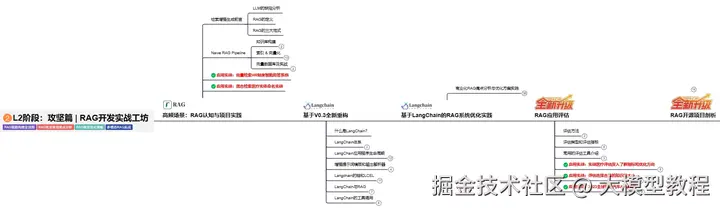
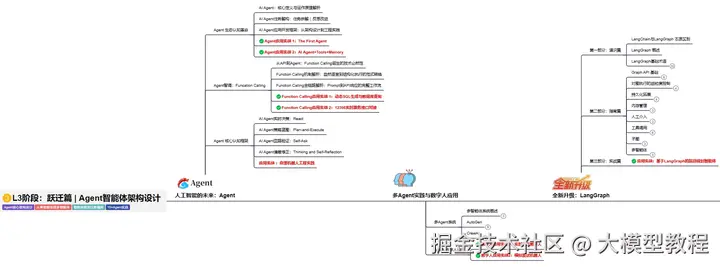
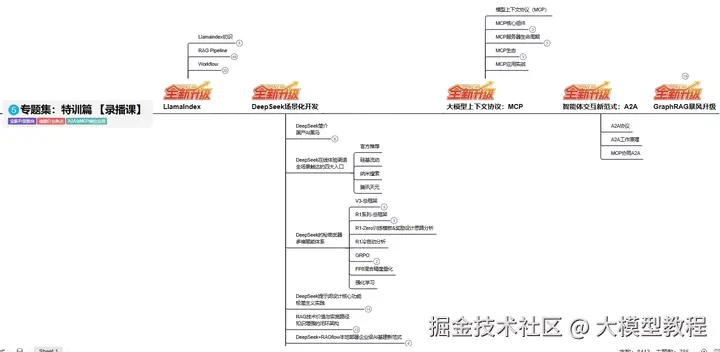
我使用PlantUML绘制了一份技能树脑图,把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。
这份大模型路线大纲已经导出整理打包了,在 >gitcode ←←←←←←

