3d极速摩托苹果版
863.7M · 2025-09-12

alixixi 9 月 12 日消息,小米集团 AI 实验室今日宣布,旗下 Kaldi 团队上个月发布了基于 Flow Matching 架构的 ZipVoice 系列语音合成(TTS)模型,包括:
ZipVoice(零样本单说话人语音合成模型)
ZipVoice-Dialog(零样本对话语音合成模型)
据官方介绍,作为 zipformer 在语音生成任务上的应用和探索,ZipVoice 解决了现有零样本语音合成模型的参数量大、合成速度慢的痛点,在轻量化建模和推理加速上取得了重要突破。
ZipVoice-Dialog 则解决了现有对话语音合成模型在稳定性和推理速度上的瓶颈,实现了又快又稳又自然的语音对话合成。
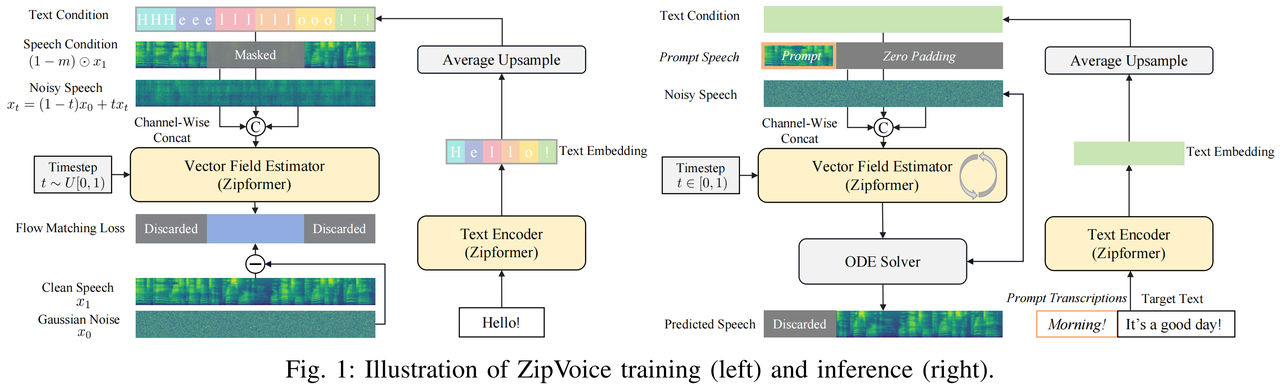
alixixi从小米官方获悉,ZipVoice 首次将原本为自动语音识别(ASR)设计的 Zipformer 架构引入 TTS 任务作为模型的骨干网络,Zipformer 中的三大设计:基于 U-Net 的多尺度高效率结构、卷积与注意力机制的协同处理、以及注意力权重的多次复用都高度适配语音合成任务,从而实现了语音合成模型的高效建模。
得益于这一设计,相比基于 DiT 的语音合成模型,在性能相似的情况下,ZipVoice 的参数量减少了约 63%。
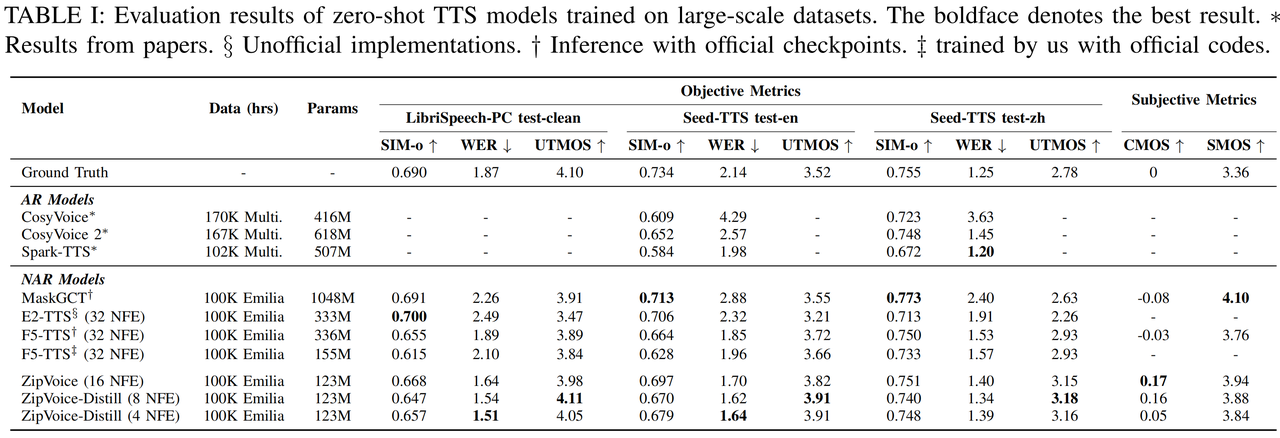
性能方面,ZipVoice 和 ZipVoice-Distill 在具备更小参数量和更快推理速度的同时,在三个客观指标,即说话人相似度(SIM-o)、词错误率(WER)和 UTMOS,以及两个主观指标(CMOS、SMOS)上都极具竞争力,达到了零样本语音合成模型的 SOTA 性能水平,同时显著减少了模型参数量,加快了推理速度。
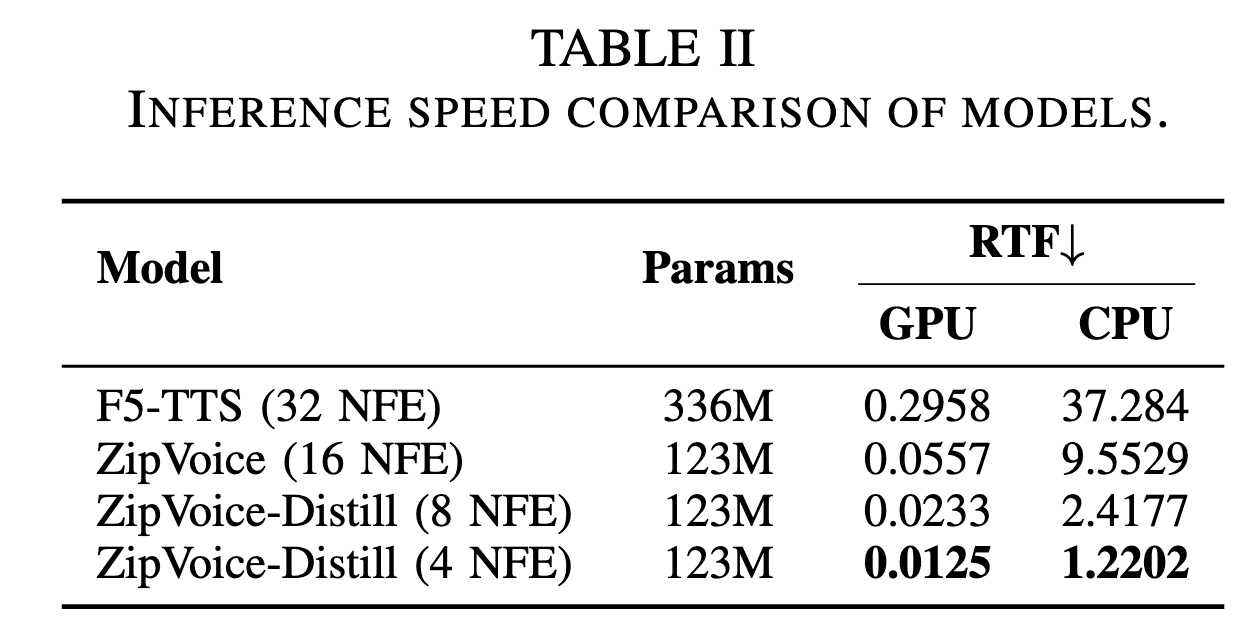
小米官方表示,ZipVoice 零样本语音合成模型具备了低参数量、高推理速度、高语音质量三大优点,ZipVoice-Dialog 提供了又快又稳又好的对话语音合成新方案。ZipVoice 系列模型为轻量化、高速度要求的语音交互应用场景提供了新的解决方案。
此外,小米表示未来团队将持续对 ZipVoice 系列模型进行优化,致力于让每一个人都能享受到低成本高质量的语音合成技术。
参考地址:
ZipVoice 系列的模型文件、训练代码和推理代码以及 6.8k 小时的语音对话数据集 OpenDialog 已全部开源:https://github.com/ k2-fsa / ZipVoice
Zipvoice 论文已被 ASRU2025 接收:https://arxiv.org/ pdf/2506.13053
样例体验请访问:https://zipvoice.github.io

