

清流4K
45.04MB · 2025-11-12

2025年11月6日,一个值得被载入AI史册的日子。美团LongCat团队正式发布了他们潜心研发的全模态大模型评测基准——UNO-Bench。这不仅是一个新的测试工具,更像是一面棱镜,首次清晰地折射出全模态大模型深藏的“组合定律”,为我们理解和构建下一代智能体提供了前所未有的视角。
长期以来,我们对于多模态大模型的理解,似乎总停留在“模态越多越好”的朴素认知上。但UNO-Bench的出现,彻底打破了这种简单粗暴的观念。LongCat团队通过严谨的实验,首次验证并揭示了全模态大模型的**“组合定律”**:
这不再是单模态能力的简单相加,而是呈现出一种非线性的幂律关系。具体而言,当模型能力尚弱时,全模态性能往往受限于其最薄弱的单模态环节,呈现出明显的**“短板效应”。然而,一旦模型跨过某个阈值,其全模态能力便会与单模态能力产生惊人的“协同增益”**,表现出远超预期的强大性能。研究甚至给出了其精确的数学表达,拟合度高达97.59%,这无疑为模型优化指明了方向:我们不仅要提升单一模态的处理能力,更要关注模态间的融合机制与协同效应。
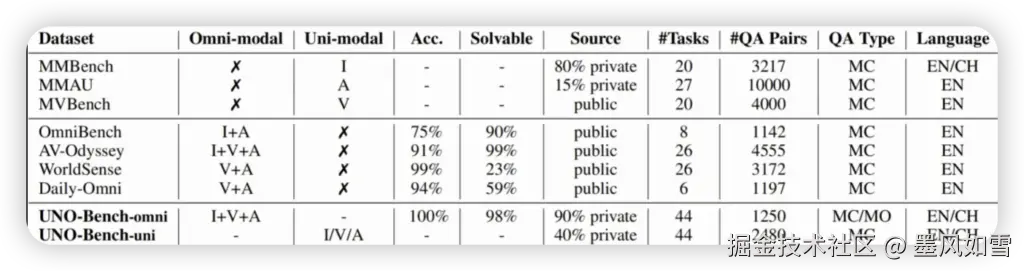
你或许会问,现有的评测基准难道不够吗?答案是:远不够!当前的评估体系面临诸多痛点:
UNO-Bench正是在这样的背景下应运而生,它旨在通过一个统一的框架,系统性地评估模型在单模态与全模态任务中的理解能力,并探索其间的内在规律。
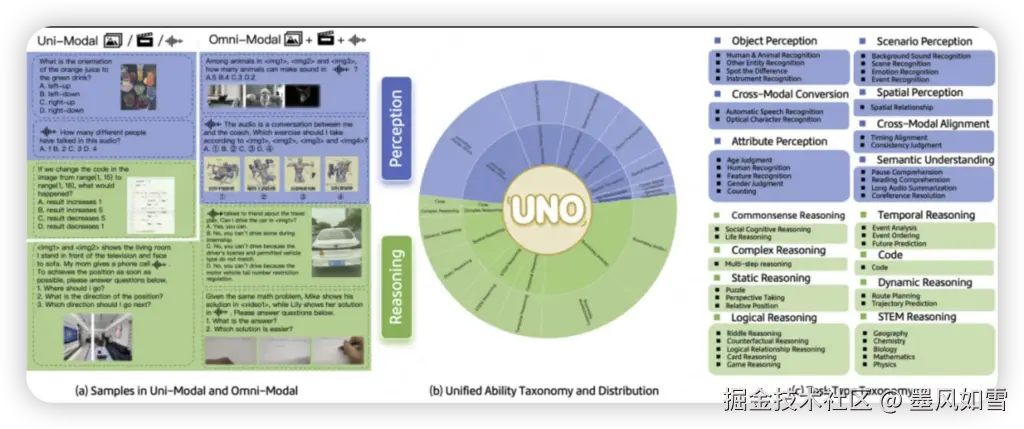
为了构建一个真正能区分模型实力的基准,LongCat团队可谓是下足了功夫:
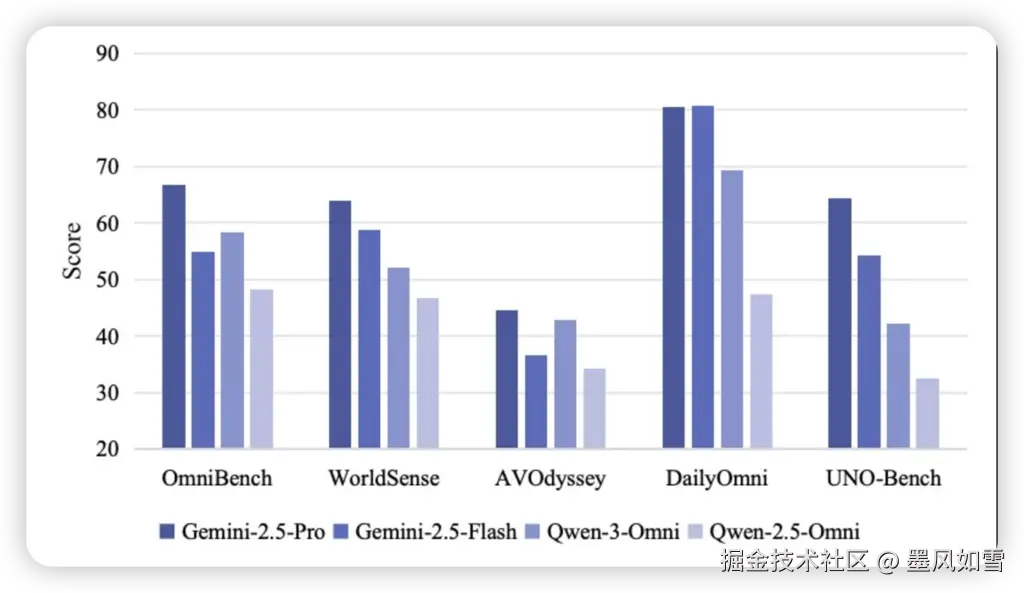
UNO-Bench的发布,无疑为全模态大模型的研发指明了新的方向。初步评测结果显示,闭源模型如Gemini系列仍处于领先地位,尤其在感知任务上已接近人类水平。而开源模型,包括LongCat团队自家的LongCat-Flash-Omni,虽然进步显著,但在复杂推理方面仍有巨大的提升空间,这正是“组合定律”中“短板效应”的体现。
特别值得一提的是,UNO-Bench目前主要专注于中文场景。这不仅是中国AI社区的福音,有助于填补此前多模态评估体系在此领域的不足,更将推动更适合中文环境的全模态模型发展。LongCat团队表示,他们计划持续扩大数据规模,引入STEM(科学、技术、工程、数学)和Code等更高难度任务,并逐步发展英语及多语言版本,持续探索模态交互的边界。
美团LongCat团队的UNO-Bench,不仅仅是一个评测基准,更是一面透视全模态大模型内在机理的棱镜。它让我们看到,未来通用AI的构建,不再是简单的堆叠,而是需要深刻理解模态间的协同与共生。这无疑将加速我们迈向真正通用AI的步伐。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!
公众号:墨风如雪小站

